
**Serie Hugging Face Accelerate**
- Instalación, configuración y entrenamiento
- 👉 Guardado, precisión mixta e inferencia (estás aquí)
Esta es la **segunda parte** de la serie sobre Hugging Face Accelerate. En la primera parte vimos la instalación, la configuración y cómo adaptar un bucle de entrenamiento para correr en múltiples GPUs/TPUs, además del control de ejecución entre procesos. Aquí continuamos con el guardado y carga de modelos, el entrenamiento con precisión mixta (FP16/BF16/FP8) y la inferencia.
Guardar y cargar el state dict
Cuando entrenamos, a veces guardamos el estado para poder seguir en otro momento
Para guardar el estado tendremos que usar los métodos save_state() y load_state()
InputPython%%writefile accelerate_scripts/10_accelerate_save_and_load_checkpoints.pyimport torchfrom torch.utils.data import DataLoaderfrom torch.optim import Adamfrom datasets import load_datasetfrom transformers import AutoTokenizer, AutoModelForSequenceClassificationimport evaluateimport tqdm# Importamos e inicializamos Acceleratorfrom accelerate import Acceleratoraccelerator = Accelerator()dataset = load_dataset("tweet_eval", "emoji")num_classes = len(dataset["train"].info.features["label"].names)max_len = 130checkpoints = "cardiffnlp/twitter-roberta-base-irony"tokenizer = AutoTokenizer.from_pretrained(checkpoints)def tokenize_function(dataset):return tokenizer(dataset["text"], max_length=max_len, padding="max_length", truncation=True, return_tensors="pt")tokenized_dataset = {"train": dataset["train"].map(tokenize_function, batched=True, remove_columns=["text"]),"validation": dataset["validation"].map(tokenize_function, batched=True, remove_columns=["text"]),"test": dataset["test"].map(tokenize_function, batched=True, remove_columns=["text"]),}tokenized_dataset["train"].set_format(type="torch", columns=['input_ids', 'attention_mask', 'label'])tokenized_dataset["validation"].set_format(type="torch", columns=['label', 'input_ids', 'attention_mask'])tokenized_dataset["test"].set_format(type="torch", columns=['label', 'input_ids', 'attention_mask'])BS = 128dataloader = {"train": DataLoader(tokenized_dataset["train"], batch_size=BS, shuffle=True),"validation": DataLoader(tokenized_dataset["validation"], batch_size=BS, shuffle=True),"test": DataLoader(tokenized_dataset["test"], batch_size=BS, shuffle=True),}model = AutoModelForSequenceClassification.from_pretrained(checkpoints)model.classifier.out_proj = torch.nn.Linear(in_features=model.classifier.out_proj.in_features, out_features=num_classes, bias=True)loss_function = torch.nn.CrossEntropyLoss()optimizer = Adam(model.parameters(), lr=5e-4)metric = evaluate.load("accuracy")@accelerator.on_local_main_processdef print_something(something):print(something)EPOCHS = 1# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")device = accelerator.device# model.to(device)model, optimizer, dataloader["train"], dataloader["validation"] = accelerator.prepare(model, optimizer, dataloader["train"], dataloader["validation"])for i in range(EPOCHS):model.train()progress_bar_train = tqdm.tqdm(dataloader["train"], disable=not accelerator.is_local_main_process)for batch in progress_bar_train:optimizer.zero_grad()input_ids = batch["input_ids"]#.to(device)attention_mask = batch["attention_mask"]#.to(device)labels = batch["label"]#.to(device)outputs = model(input_ids=input_ids, attention_mask=attention_mask)loss = loss_function(outputs['logits'], labels)# loss.backward()accelerator.backward(loss)optimizer.step()model.eval()progress_bar_validation = tqdm.tqdm(dataloader["validation"], disable=not accelerator.is_local_main_process)for batch in progress_bar_validation:input_ids = batch["input_ids"]#.to(device)attention_mask = batch["attention_mask"]#.to(device)labels = batch["label"]#.to(device)with torch.no_grad():outputs = model(input_ids=input_ids, attention_mask=attention_mask)predictions = torch.argmax(outputs['logits'], axis=-1)# Recopilamos las predicciones de todos los dispositivospredictions = accelerator.gather_for_metrics(predictions)labels = accelerator.gather_for_metrics(labels)accuracy = metric.add_batch(predictions=predictions, references=labels)accuracy = metric.compute()# Guardamos los pesosaccelerator.save_state("accelerate_scripts/checkpoints")print_something(f"Accuracy = {accuracy['accuracy']}")# Cargamos los pesosaccelerator.load_state("accelerate_scripts/checkpoints")Copied
Overwriting accelerate_scripts/09_accelerate_save_and_load_checkpoints.py
Lo ejecutamos
InputPython!accelerate launch accelerate_scripts/10_accelerate_save_and_load_checkpoints.pyCopied
100%|█████████████████████████████████████████| 176/176 [01:58<00:00, 1.48it/s]100%|███████████████████████████████████████████| 20/20 [00:05<00:00, 3.40it/s]Accuracy = 0.2142
Guardar el modelo
Cuando se usó el método prepare se envolvió el modelo para poder guardarlo en los dispositivos necesarios. Por lo que a la hora de guardarlo tenemos que usar el método save_model que primero lo desenvuelve y luego lo guarda. Además, si usamos el parámetro safe_serialization=True se guardará el modelo como un safe tensor
InputPython%%writefile accelerate_scripts/11_accelerate_save_model.pyimport torchfrom torch.utils.data import DataLoaderfrom torch.optim import Adamfrom datasets import load_datasetfrom transformers import AutoTokenizer, AutoModelForSequenceClassificationimport evaluateimport tqdm# Importamos e inicializamos Acceleratorfrom accelerate import Acceleratoraccelerator = Accelerator()dataset = load_dataset("tweet_eval", "emoji")num_classes = len(dataset["train"].info.features["label"].names)max_len = 130checkpoints = "cardiffnlp/twitter-roberta-base-irony"tokenizer = AutoTokenizer.from_pretrained(checkpoints)def tokenize_function(dataset):return tokenizer(dataset["text"], max_length=max_len, padding="max_length", truncation=True, return_tensors="pt")tokenized_dataset = {"train": dataset["train"].map(tokenize_function, batched=True, remove_columns=["text"]),"validation": dataset["validation"].map(tokenize_function, batched=True, remove_columns=["text"]),"test": dataset["test"].map(tokenize_function, batched=True, remove_columns=["text"]),}tokenized_dataset["train"].set_format(type="torch", columns=['input_ids', 'attention_mask', 'label'])tokenized_dataset["validation"].set_format(type="torch", columns=['label', 'input_ids', 'attention_mask'])tokenized_dataset["test"].set_format(type="torch", columns=['label', 'input_ids', 'attention_mask'])BS = 128dataloader = {"train": DataLoader(tokenized_dataset["train"], batch_size=BS, shuffle=True),"validation": DataLoader(tokenized_dataset["validation"], batch_size=BS, shuffle=True),"test": DataLoader(tokenized_dataset["test"], batch_size=BS, shuffle=True),}model = AutoModelForSequenceClassification.from_pretrained(checkpoints)model.classifier.out_proj = torch.nn.Linear(in_features=model.classifier.out_proj.in_features, out_features=num_classes, bias=True)loss_function = torch.nn.CrossEntropyLoss()optimizer = Adam(model.parameters(), lr=5e-4)metric = evaluate.load("accuracy")@accelerator.on_local_main_processdef print_something(something):print(something)EPOCHS = 1# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")device = accelerator.device# model.to(device)model, optimizer, dataloader["train"], dataloader["validation"] = accelerator.prepare(model, optimizer, dataloader["train"], dataloader["validation"])for i in range(EPOCHS):model.train()progress_bar_train = tqdm.tqdm(dataloader["train"], disable=not accelerator.is_local_main_process)for batch in progress_bar_train:optimizer.zero_grad()input_ids = batch["input_ids"]#.to(device)attention_mask = batch["attention_mask"]#.to(device)labels = batch["label"]#.to(device)outputs = model(input_ids=input_ids, attention_mask=attention_mask)loss = loss_function(outputs['logits'], labels)# loss.backward()accelerator.backward(loss)optimizer.step()model.eval()progress_bar_validation = tqdm.tqdm(dataloader["validation"], disable=not accelerator.is_local_main_process)for batch in progress_bar_validation:input_ids = batch["input_ids"]#.to(device)attention_mask = batch["attention_mask"]#.to(device)labels = batch["label"]#.to(device)with torch.no_grad():outputs = model(input_ids=input_ids, attention_mask=attention_mask)predictions = torch.argmax(outputs['logits'], axis=-1)# Recopilamos las predicciones de todos los dispositivospredictions = accelerator.gather_for_metrics(predictions)labels = accelerator.gather_for_metrics(labels)accuracy = metric.add_batch(predictions=predictions, references=labels)accuracy = metric.compute()# Guardamos el modeloaccelerator.wait_for_everyone()accelerator.save_model(model, "accelerate_scripts/model", safe_serialization=True)print_something(f"Accuracy = {accuracy['accuracy']}")Copied
Writing accelerate_scripts/11_accelerate_save_model.py
Lo ejecutamos
InputPython!accelerate launch accelerate_scripts/11_accelerate_save_model.pyCopied
100%|█████████████████████████████████████████| 176/176 [01:58<00:00, 1.48it/s]100%|███████████████████████████████████████████| 20/20 [00:05<00:00, 3.35it/s]Accuracy = 0.214
Guardar el modelo pretrained
En modelos que usan la librería transformers debemos guardar el modelo con el método save_pretrained para poder cargarlo con el método from_pretrained. Antes de guardarlo hay que desenvolverlo con el método unwrap_model
InputPython%%writefile accelerate_scripts/12_accelerate_save_pretrained.pyimport torchfrom torch.utils.data import DataLoaderfrom torch.optim import Adamfrom datasets import load_datasetfrom transformers import AutoTokenizer, AutoModelForSequenceClassificationimport evaluateimport tqdm# Importamos e inicializamos Acceleratorfrom accelerate import Acceleratoraccelerator = Accelerator()dataset = load_dataset("tweet_eval", "emoji")num_classes = len(dataset["train"].info.features["label"].names)max_len = 130checkpoints = "cardiffnlp/twitter-roberta-base-irony"tokenizer = AutoTokenizer.from_pretrained(checkpoints)def tokenize_function(dataset):return tokenizer(dataset["text"], max_length=max_len, padding="max_length", truncation=True, return_tensors="pt")tokenized_dataset = {"train": dataset["train"].map(tokenize_function, batched=True, remove_columns=["text"]),"validation": dataset["validation"].map(tokenize_function, batched=True, remove_columns=["text"]),"test": dataset["test"].map(tokenize_function, batched=True, remove_columns=["text"]),}tokenized_dataset["train"].set_format(type="torch", columns=['input_ids', 'attention_mask', 'label'])tokenized_dataset["validation"].set_format(type="torch", columns=['label', 'input_ids', 'attention_mask'])tokenized_dataset["test"].set_format(type="torch", columns=['label', 'input_ids', 'attention_mask'])BS = 128dataloader = {"train": DataLoader(tokenized_dataset["train"], batch_size=BS, shuffle=True),"validation": DataLoader(tokenized_dataset["validation"], batch_size=BS, shuffle=True),"test": DataLoader(tokenized_dataset["test"], batch_size=BS, shuffle=True),}model = AutoModelForSequenceClassification.from_pretrained(checkpoints)model.classifier.out_proj = torch.nn.Linear(in_features=model.classifier.out_proj.in_features, out_features=num_classes, bias=True)loss_function = torch.nn.CrossEntropyLoss()optimizer = Adam(model.parameters(), lr=5e-4)metric = evaluate.load("accuracy")@accelerator.on_local_main_processdef print_something(something):print(something)EPOCHS = 1# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")device = accelerator.device# model.to(device)model, optimizer, dataloader["train"], dataloader["validation"] = accelerator.prepare(model, optimizer, dataloader["train"], dataloader["validation"])for i in range(EPOCHS):model.train()progress_bar_train = tqdm.tqdm(dataloader["train"], disable=not accelerator.is_local_main_process)for batch in progress_bar_train:optimizer.zero_grad()input_ids = batch["input_ids"]#.to(device)attention_mask = batch["attention_mask"]#.to(device)labels = batch["label"]#.to(device)outputs = model(input_ids=input_ids, attention_mask=attention_mask)loss = loss_function(outputs['logits'], labels)# loss.backward()accelerator.backward(loss)optimizer.step()model.eval()progress_bar_validation = tqdm.tqdm(dataloader["validation"], disable=not accelerator.is_local_main_process)for batch in progress_bar_validation:input_ids = batch["input_ids"]#.to(device)attention_mask = batch["attention_mask"]#.to(device)labels = batch["label"]#.to(device)with torch.no_grad():outputs = model(input_ids=input_ids, attention_mask=attention_mask)predictions = torch.argmax(outputs['logits'], axis=-1)# Recopilamos las predicciones de todos los dispositivospredictions = accelerator.gather_for_metrics(predictions)labels = accelerator.gather_for_metrics(labels)accuracy = metric.add_batch(predictions=predictions, references=labels)accuracy = metric.compute()# Guardamos el modelo pretrainedunwrapped_model = accelerator.unwrap_model(model)unwrapped_model.save_pretrained("accelerate_scripts/model_pretrained",is_main_process=accelerator.is_main_process,save_function=accelerator.save,)print_something(f"Accuracy = {accuracy['accuracy']}")Copied
Writing accelerate_scripts/11_accelerate_save_pretrained.py
Lo ejecutamos
InputPython!accelerate launch accelerate_scripts/12_accelerate_save_pretrained.pyCopied
Map: 100%|██████████████████████| 45000/45000 [00:02<00:00, 15152.47 examples/s]Map: 100%|██████████████████████| 45000/45000 [00:02<00:00, 15119.13 examples/s]Map: 100%|████████████████████████| 5000/5000 [00:00<00:00, 12724.70 examples/s]Map: 100%|████████████████████████| 5000/5000 [00:00<00:00, 12397.49 examples/s]Map: 100%|██████████████████████| 50000/50000 [00:03<00:00, 15247.21 examples/s]Map: 100%|██████████████████████| 50000/50000 [00:03<00:00, 15138.03 examples/s]100%|█████████████████████████████████████████| 176/176 [01:59<00:00, 1.48it/s]100%|███████████████████████████████████████████| 20/20 [00:05<00:00, 3.37it/s]Accuracy = 0.21
Ahora lo podríamos cargar
InputPythonfrom transformers import AutoModelcheckpoints = "accelerate_scripts/model_pretrained"tokenizer = AutoModel.from_pretrained(checkpoints)Copied
Some weights of RobertaModel were not initialized from the model checkpoint at accelerate_scripts/model_pretrained and are newly initialized: ['roberta.pooler.dense.bias', 'roberta.pooler.dense.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Entrenamiento en notebooks
Hasta ahora hemos visto cómo ejecutar scripts, pero si quieres ejecutar el código en un notebook, podemos escribir el mismo código de antes, pero encapsulado en una función
Primero importamos las librerías
InputPythonimport torchfrom torch.utils.data import DataLoaderfrom torch.optim import Adamfrom datasets import load_datasetfrom transformers import AutoTokenizer, AutoModelForSequenceClassificationimport evaluateimport tqdmimport time# from accelerate import AcceleratorCopied
Ahora creamos la función
InputPythondef train_code(batch_size: int = 64):from accelerate import Acceleratoraccelerator = Accelerator()dataset = load_dataset("tweet_eval", "emoji")num_classes = len(dataset["train"].info.features["label"].names)max_len = 130checkpoints = "cardiffnlp/twitter-roberta-base-irony"tokenizer = AutoTokenizer.from_pretrained(checkpoints)def tokenize_function(dataset):return tokenizer(dataset["text"], max_length=max_len, padding="max_length", truncation=True, return_tensors="pt")tokenized_dataset = {"train": dataset["train"].map(tokenize_function, batched=True, remove_columns=["text"]),"validation": dataset["validation"].map(tokenize_function, batched=True, remove_columns=["text"]),"test": dataset["test"].map(tokenize_function, batched=True, remove_columns=["text"]),}tokenized_dataset["train"].set_format(type="torch", columns=['input_ids', 'attention_mask', 'label'])tokenized_dataset["validation"].set_format(type="torch", columns=['label', 'input_ids', 'attention_mask'])tokenized_dataset["test"].set_format(type="torch", columns=['label', 'input_ids', 'attention_mask'])BS = batch_sizedataloader = {"train": DataLoader(tokenized_dataset["train"], batch_size=BS, shuffle=True),"validation": DataLoader(tokenized_dataset["validation"], batch_size=BS, shuffle=True),"test": DataLoader(tokenized_dataset["test"], batch_size=BS, shuffle=True),}model = AutoModelForSequenceClassification.from_pretrained(checkpoints)model.classifier.out_proj = torch.nn.Linear(in_features=model.classifier.out_proj.in_features, out_features=num_classes, bias=True)loss_function = torch.nn.CrossEntropyLoss()optimizer = Adam(model.parameters(), lr=5e-4)metric = evaluate.load("accuracy")EPOCHS = 1# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")device = accelerator.device# model.to(device)model, optimizer, dataloader["train"], dataloader["validation"] = accelerator.prepare(model, optimizer, dataloader["train"], dataloader["validation"])for i in range(EPOCHS):model.train()progress_bar_train = tqdm.tqdm(dataloader["train"], disable=not accelerator.is_local_main_process)for batch in progress_bar_train:optimizer.zero_grad()input_ids = batch["input_ids"]#.to(device)attention_mask = batch["attention_mask"]#.to(device)labels = batch["label"]#.to(device)outputs = model(input_ids=input_ids, attention_mask=attention_mask)loss = loss_function(outputs['logits'], labels)# loss.backward()accelerator.backward(loss)optimizer.step()model.eval()progress_bar_validation = tqdm.tqdm(dataloader["validation"], disable=not accelerator.is_local_main_process)for batch in progress_bar_validation:input_ids = batch["input_ids"]#.to(device)attention_mask = batch["attention_mask"]#.to(device)labels = batch["label"]#.to(device)with torch.no_grad():outputs = model(input_ids=input_ids, attention_mask=attention_mask)predictions = torch.argmax(outputs['logits'], axis=-1)# Recopilamos las predicciones de todos los dispositivospredictions = accelerator.gather_for_metrics(predictions)labels = accelerator.gather_for_metrics(labels)accuracy = metric.add_batch(predictions=predictions, references=labels)accuracy = metric.compute()accelerator.print(f"Accuracy = {accuracy['accuracy']}")Copied
Para poder ejecutar el entrenamiento en el notebook usamos la función notebook_launcher, a la que le pasamos la función que queremos ejecutar, los argumentos de esa función y el número de GPUs en las que vamos a entrenar con la variable num_processes
InputPythonfrom accelerate import notebook_launcherargs = (128,)notebook_launcher(train_code, args, num_processes=2)Copied
Launching training on 2 GPUs.
100%|██████████| 176/176 [02:01<00:00, 1.45it/s]100%|██████████| 20/20 [00:06<00:00, 3.31it/s]
Accuracy = 0.2112
Entrenamiento en FP16
Cuando al principio configuramos accelerate nos preguntó Do you wish to use FP16 or BF16 (mixed precision)? y dijimos que no, así que ahora vamos a decirle que sí, que queremos en FP16
Hasta ahora hemos entrenado en FP32, lo que quiere decir que cada peso del modelo es un número en coma flotante de 32 bits, y ahora vamos a usar un número en coma flotante de 16 bits, es decir, el modelo va a ocupar menos. Por lo que van a pasar dos cosas: podremos usar un batch size mayor y además será más rápido
Primero volvemos a lanzar accelerate config y le vamos a decir que queremos FP16
InputPython!accelerate configCopied
--------------------------------------------------------------------------------In which compute environment are you running?This machine--------------------------------------------------------------------------------multi-GPUHow many different machines will you use (use more than 1 for multi-node training)? [1]: 1Should distributed operations be checked while running for errors? This can avoid timeout issues but will be slower. [yes/NO]: noDo you wish to optimize your script with torch dynamo?[yes/NO]:noDo you want to use DeepSpeed? [yes/NO]: noDo you want to use FullyShardedDataParallel? [yes/NO]: noDo you want to use Megatron-LM ? [yes/NO]: noHow many GPU(s) should be used for distributed training? [1]:2What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:0,1--------------------------------------------------------------------------------Do you wish to use FP16 or BF16 (mixed precision)?fp16accelerate configuration saved at ~/.cache/huggingface/accelerate/default_config.yaml
Ahora creamos un script para entrenar, con el mismo batch size de antes, para ver si tarda menos en entrenar
InputPython%%writefile accelerate_scripts/13_accelerate_base_code_fp16_bs128.pyimport torchfrom torch.utils.data import DataLoaderfrom torch.optim import Adamfrom datasets import load_datasetfrom transformers import AutoTokenizer, AutoModelForSequenceClassificationimport evaluateimport tqdm# Importamos e inicializamos Acceleratorfrom accelerate import Acceleratoraccelerator = Accelerator()dataset = load_dataset("tweet_eval", "emoji")num_classes = len(dataset["train"].info.features["label"].names)max_len = 130checkpoints = "cardiffnlp/twitter-roberta-base-irony"tokenizer = AutoTokenizer.from_pretrained(checkpoints)def tokenize_function(dataset):return tokenizer(dataset["text"], max_length=max_len, padding="max_length", truncation=True, return_tensors="pt")tokenized_dataset = {"train": dataset["train"].map(tokenize_function, batched=True, remove_columns=["text"]),"validation": dataset["validation"].map(tokenize_function, batched=True, remove_columns=["text"]),"test": dataset["test"].map(tokenize_function, batched=True, remove_columns=["text"]),}tokenized_dataset["train"].set_format(type="torch", columns=['input_ids', 'attention_mask', 'label'])tokenized_dataset["validation"].set_format(type="torch", columns=['label', 'input_ids', 'attention_mask'])tokenized_dataset["test"].set_format(type="torch", columns=['label', 'input_ids', 'attention_mask'])BS = 128dataloader = {"train": DataLoader(tokenized_dataset["train"], batch_size=BS, shuffle=True),"validation": DataLoader(tokenized_dataset["validation"], batch_size=BS, shuffle=True),"test": DataLoader(tokenized_dataset["test"], batch_size=BS, shuffle=True),}model = AutoModelForSequenceClassification.from_pretrained(checkpoints)model.classifier.out_proj = torch.nn.Linear(in_features=model.classifier.out_proj.in_features, out_features=num_classes, bias=True)loss_function = torch.nn.CrossEntropyLoss()optimizer = Adam(model.parameters(), lr=5e-4)metric = evaluate.load("accuracy")EPOCHS = 1# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")device = accelerator.device# model.to(device)model, optimizer, dataloader["train"], dataloader["validation"] = accelerator.prepare(model, optimizer, dataloader["train"], dataloader["validation"])for i in range(EPOCHS):model.train()progress_bar_train = tqdm.tqdm(dataloader["train"], disable=not accelerator.is_local_main_process)for batch in progress_bar_train:optimizer.zero_grad()input_ids = batch["input_ids"]#.to(device)attention_mask = batch["attention_mask"]#.to(device)labels = batch["label"]#.to(device)outputs = model(input_ids=input_ids, attention_mask=attention_mask)loss = loss_function(outputs['logits'], labels)# loss.backward()accelerator.backward(loss)optimizer.step()model.eval()progress_bar_validation = tqdm.tqdm(dataloader["validation"], disable=not accelerator.is_local_main_process)for batch in progress_bar_validation:input_ids = batch["input_ids"]#.to(device)attention_mask = batch["attention_mask"]#.to(device)labels = batch["label"]#.to(device)with torch.no_grad():outputs = model(input_ids=input_ids, attention_mask=attention_mask)predictions = torch.argmax(outputs['logits'], axis=-1)# Recopilamos las predicciones de todos los dispositivospredictions = accelerator.gather_for_metrics(predictions)labels = accelerator.gather_for_metrics(labels)accuracy = metric.add_batch(predictions=predictions, references=labels)accuracy = metric.compute()accelerator.print(f"Accuracy = {accuracy['accuracy']}")Copied
Overwriting accelerate_scripts/12_accelerate_base_code_fp16_bs128.py
Lo ejecutamos a ver cuánto tarda
InputPython%%time!accelerate launch accelerate_scripts/13_accelerate_base_code_fp16_bs128.pyCopied
Map: 100%|████████████████████████| 5000/5000 [00:00<00:00, 14983.76 examples/s]Map: 100%|██████████████████████| 50000/50000 [00:03<00:00, 14315.47 examples/s]100%|█████████████████████████████████████████| 176/176 [01:01<00:00, 2.88it/s]100%|███████████████████████████████████████████| 20/20 [00:02<00:00, 6.84it/s]Accuracy = 0.2094CPU times: user 812 ms, sys: 163 ms, total: 976 msWall time: 1min 27s
Cuando ejecutamos este entrenamiento en FP32 tardó unos 2 minutos y medio, y ahora más o menos 1 minuto y medio. Vamos a ver si ahora, en vez de entrenar con un batch size de 128, lo hacemos con uno de 256
InputPython%%writefile accelerate_scripts/14_accelerate_base_code_fp16_bs256.pyimport torchfrom torch.utils.data import DataLoaderfrom torch.optim import Adamfrom datasets import load_datasetfrom transformers import AutoTokenizer, AutoModelForSequenceClassificationimport evaluateimport tqdm# Importamos e inicializamos Acceleratorfrom accelerate import Acceleratoraccelerator = Accelerator()dataset = load_dataset("tweet_eval", "emoji")num_classes = len(dataset["train"].info.features["label"].names)max_len = 130checkpoints = "cardiffnlp/twitter-roberta-base-irony"tokenizer = AutoTokenizer.from_pretrained(checkpoints)def tokenize_function(dataset):return tokenizer(dataset["text"], max_length=max_len, padding="max_length", truncation=True, return_tensors="pt")tokenized_dataset = {"train": dataset["train"].map(tokenize_function, batched=True, remove_columns=["text"]),"validation": dataset["validation"].map(tokenize_function, batched=True, remove_columns=["text"]),"test": dataset["test"].map(tokenize_function, batched=True, remove_columns=["text"]),}tokenized_dataset["train"].set_format(type="torch", columns=['input_ids', 'attention_mask', 'label'])tokenized_dataset["validation"].set_format(type="torch", columns=['label', 'input_ids', 'attention_mask'])tokenized_dataset["test"].set_format(type="torch", columns=['label', 'input_ids', 'attention_mask'])BS = 256dataloader = {"train": DataLoader(tokenized_dataset["train"], batch_size=BS, shuffle=True),"validation": DataLoader(tokenized_dataset["validation"], batch_size=BS, shuffle=True),"test": DataLoader(tokenized_dataset["test"], batch_size=BS, shuffle=True),}model = AutoModelForSequenceClassification.from_pretrained(checkpoints)model.classifier.out_proj = torch.nn.Linear(in_features=model.classifier.out_proj.in_features, out_features=num_classes, bias=True)loss_function = torch.nn.CrossEntropyLoss()optimizer = Adam(model.parameters(), lr=5e-4)metric = evaluate.load("accuracy")EPOCHS = 1# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")device = accelerator.device# model.to(device)model, optimizer, dataloader["train"], dataloader["validation"] = accelerator.prepare(model, optimizer, dataloader["train"], dataloader["validation"])for i in range(EPOCHS):model.train()progress_bar_train = tqdm.tqdm(dataloader["train"], disable=not accelerator.is_local_main_process)for batch in progress_bar_train:optimizer.zero_grad()input_ids = batch["input_ids"]#.to(device)attention_mask = batch["attention_mask"]#.to(device)labels = batch["label"]#.to(device)outputs = model(input_ids=input_ids, attention_mask=attention_mask)loss = loss_function(outputs['logits'], labels)# loss.backward()accelerator.backward(loss)optimizer.step()model.eval()progress_bar_validation = tqdm.tqdm(dataloader["validation"], disable=not accelerator.is_local_main_process)for batch in progress_bar_validation:input_ids = batch["input_ids"]#.to(device)attention_mask = batch["attention_mask"]#.to(device)labels = batch["label"]#.to(device)with torch.no_grad():outputs = model(input_ids=input_ids, attention_mask=attention_mask)predictions = torch.argmax(outputs['logits'], axis=-1)# Recopilamos las predicciones de todos los dispositivospredictions = accelerator.gather_for_metrics(predictions)labels = accelerator.gather_for_metrics(labels)accuracy = metric.add_batch(predictions=predictions, references=labels)accuracy = metric.compute()accelerator.print(f"Accuracy = {accuracy['accuracy']}")Copied
Overwriting accelerate_scripts/13_accelerate_base_code_fp16_bs256.py
Lo ejecutamos
InputPython%%time!accelerate launch accelerate_scripts/14_accelerate_base_code_fp16_bs256.pyCopied
Map: 100%|████████████████████████| 5000/5000 [00:00<00:00, 15390.30 examples/s]Map: 100%|████████████████████████| 5000/5000 [00:00<00:00, 14990.92 examples/s]100%|███████████████████████████████████████████| 88/88 [00:54<00:00, 1.62it/s]100%|███████████████████████████████████████████| 10/10 [00:02<00:00, 3.45it/s]Accuracy = 0.2236CPU times: user 670 ms, sys: 91.6 ms, total: 761 msWall time: 1min 12s
Ha bajado solo unos 15 segundos
Entrenamiento en BF16
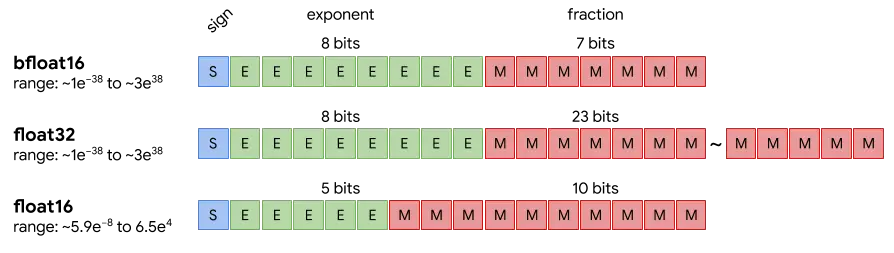
Antes hemos entrenado en FP16 y ahora lo vamos a hacer en BF16, ¿cuál es la diferencia?
Como podemos ver en la imagen, mientras que FP16 en comparación con FP32 tiene menos bits en la mantisa y el exponente, lo que hace que su rango sea mucho menor, BF16 en comparación con FP32 tiene el mismo número de bits del exponente pero menos en la mantisa, lo que hace que BF16 tenga el mismo rango de números que FP32, pero es menos preciso
Esto es beneficioso porque en FP16 algunos cálculos podrían dar números muy altos, que en formato FP16 no se podrían representar. Además hay ciertos dispositivos HW que están optimizados para este formato
Al igual que antes, ejecutamos accelerate config y le indicamos que queremos BF16
InputPython!accelerate configCopied
--------------------------------------------------------------------------------In which compute environment are you running?This machine--------------------------------------------------------------------------------multi-GPUHow many different machines will you use (use more than 1 for multi-node training)? [1]: 1Should distributed operations be checked while running for errors? This can avoid timeout issues but will be slower. [yes/NO]: noDo you wish to optimize your script with torch dynamo?[yes/NO]:noDo you want to use DeepSpeed? [yes/NO]: noDo you want to use FullyShardedDataParallel? [yes/NO]: noDo you want to use Megatron-LM ? [yes/NO]: noHow many GPU(s) should be used for distributed training? [1]:2What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:0,1--------------------------------------------------------------------------------Do you wish to use FP16 or BF16 (mixed precision)?bf16accelerate configuration saved at ~/.cache/huggingface/accelerate/default_config.yaml
Ahora ejecutamos el último script que habíamos creado, es decir, con un batch size de 256
InputPython%%time!accelerate launch accelerate_scripts/14_accelerate_base_code_fp16_bs256.pyCopied
Map: 100%|██████████████████████| 50000/50000 [00:03<00:00, 14814.95 examples/s]Map: 100%|██████████████████████| 50000/50000 [00:03<00:00, 14506.83 examples/s]100%|███████████████████████████████████████████| 88/88 [00:51<00:00, 1.70it/s]100%|███████████████████████████████████████████| 10/10 [00:03<00:00, 3.21it/s]Accuracy = 0.2112CPU times: user 688 ms, sys: 144 ms, total: 832 msWall time: 1min 17s
Ha tardado un tiempo similar a lo que tardó antes, lo cual es normal, ya que hemos entrenado un modelo con pesos de 16 bits, al igual que antes
Entrenamiento en FP8
Ahora vamos a entrenar en formato FP8, que como su nombre indica, es un formato de coma flotante donde cada peso tiene 8 bits, por lo que ejecutamos accelerate config para decirle que queremos FP8
InputPython!accelerate configCopied
--------------------------------------------------------------------------------In which compute environment are you running?This machine--------------------------------------------------------------------------------multi-GPUHow many different machines will you use (use more than 1 for multi-node training)? [1]: 1Should distributed operations be checked while running for errors? This can avoid timeout issues but will be slower. [yes/NO]: noDo you wish to optimize your script with torch dynamo?[yes/NO]:noDo you want to use DeepSpeed? [yes/NO]: noDo you want to use FullyShardedDataParallel? [yes/NO]: noDo you want to use Megatron-LM ? [yes/NO]: noHow many GPU(s) should be used for distributed training? [1]:2What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:0,1--------------------------------------------------------------------------------Do you wish to use FP16 or BF16 (mixed precision)?fp8accelerate configuration saved at ~/.cache/huggingface/accelerate/default_config.yaml
Ahora ejecutamos el último script, el de batch size de 256
InputPython%%time!accelerate launch accelerate_scripts/14_accelerate_base_code_fp16_bs256.pyCopied
Traceback (most recent call last):File "/home/wallabot/Documentos/web/portafolio/posts/accelerate_scripts/13_accelerate_base_code_fp16_bs256.py", line 12, in <module>accelerator = Accelerator()^^^^^^^^^^^^^File "/home/wallabot/miniconda3/envs/nlp/lib/python3.11/site-packages/accelerate/accelerator.py", line 371, in __init__self.state = AcceleratorState(^^^^^^^^^^^^^^^^^File "/home/wallabot/miniconda3/envs/nlp/lib/python3.11/site-packages/accelerate/state.py", line 790, in __init__raise ValueError(ValueError: Using `fp8` precision requires `transformer_engine` or `MS-AMP` to be installed.Traceback (most recent call last):File "/home/wallabot/Documentos/web/portafolio/posts/accelerate_scripts/13_accelerate_base_code_fp16_bs256.py", line 12, in <module>accelerator = Accelerator()^^^^^^^^^^^^^File "/home/wallabot/miniconda3/envs/nlp/lib/python3.11/site-packages/accelerate/accelerator.py", line 371, in __init__self.state = AcceleratorState(^^^^^^^^^^^^^^^^^File "/home/wallabot/miniconda3/envs/nlp/lib/python3.11/site-packages/accelerate/state.py", line 790, in __init__raise ValueError(ValueError: Using `fp8` precision requires `transformer_engine` or `MS-AMP` to be installed....[0]:time : 2024-05-13_21:40:56host : wallabotrank : 0 (local_rank: 0)exitcode : 1 (pid: 501480)error_file: <N/A>traceback : To enable traceback see: https://pytorch.org/docs/stable/elastic/errors.html============================================================CPU times: user 65.1 ms, sys: 14.5 ms, total: 79.6 msWall time: 7.24 s
Como los pesos ahora son de 8 bits y ocupan la mitad de memoria, vamos a subir el batch size a 512
InputPython%%writefile accelerate_scripts/15_accelerate_base_code_fp8_bs512.pyimport torchfrom torch.utils.data import DataLoaderfrom torch.optim import Adamfrom datasets import load_datasetfrom transformers import AutoTokenizer, AutoModelForSequenceClassificationimport evaluateimport tqdm# Importamos e inicializamos Acceleratorfrom accelerate import Acceleratoraccelerator = Accelerator()dataset = load_dataset("tweet_eval", "emoji")num_classes = len(dataset["train"].info.features["label"].names)max_len = 130checkpoints = "cardiffnlp/twitter-roberta-base-irony"tokenizer = AutoTokenizer.from_pretrained(checkpoints)def tokenize_function(dataset):return tokenizer(dataset["text"], max_length=max_len, padding="max_length", truncation=True, return_tensors="pt")tokenized_dataset = {"train": dataset["train"].map(tokenize_function, batched=True, remove_columns=["text"]),"validation": dataset["validation"].map(tokenize_function, batched=True, remove_columns=["text"]),"test": dataset["test"].map(tokenize_function, batched=True, remove_columns=["text"]),}tokenized_dataset["train"].set_format(type="torch", columns=['input_ids', 'attention_mask', 'label'])tokenized_dataset["validation"].set_format(type="torch", columns=['label', 'input_ids', 'attention_mask'])tokenized_dataset["test"].set_format(type="torch", columns=['label', 'input_ids', 'attention_mask'])BS = 512dataloader = {"train": DataLoader(tokenized_dataset["train"], batch_size=BS, shuffle=True),"validation": DataLoader(tokenized_dataset["validation"], batch_size=BS, shuffle=True),"test": DataLoader(tokenized_dataset["test"], batch_size=BS, shuffle=True),}model = AutoModelForSequenceClassification.from_pretrained(checkpoints)model.classifier.out_proj = torch.nn.Linear(in_features=model.classifier.out_proj.in_features, out_features=num_classes, bias=True)loss_function = torch.nn.CrossEntropyLoss()optimizer = Adam(model.parameters(), lr=5e-4)metric = evaluate.load("accuracy")EPOCHS = 1# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")device = accelerator.device# model.to(device)model, optimizer, dataloader["train"], dataloader["validation"] = accelerator.prepare(model, optimizer, dataloader["train"], dataloader["validation"])for i in range(EPOCHS):model.train()progress_bar_train = tqdm.tqdm(dataloader["train"], disable=not accelerator.is_local_main_process)for batch in progress_bar_train:optimizer.zero_grad()input_ids = batch["input_ids"]#.to(device)attention_mask = batch["attention_mask"]#.to(device)labels = batch["label"]#.to(device)outputs = model(input_ids=input_ids, attention_mask=attention_mask)loss = loss_function(outputs['logits'], labels)# loss.backward()accelerator.backward(loss)optimizer.step()model.eval()progress_bar_validation = tqdm.tqdm(dataloader["validation"], disable=not accelerator.is_local_main_process)for batch in progress_bar_validation:input_ids = batch["input_ids"]#.to(device)attention_mask = batch["attention_mask"]#.to(device)labels = batch["label"]#.to(device)with torch.no_grad():outputs = model(input_ids=input_ids, attention_mask=attention_mask)predictions = torch.argmax(outputs['logits'], axis=-1)# Recopilamos las predicciones de todos los dispositivospredictions = accelerator.gather_for_metrics(predictions)labels = accelerator.gather_for_metrics(labels)accuracy = metric.add_batch(predictions=predictions, references=labels)accuracy = metric.compute()accelerator.print(f"Accuracy = {accuracy['accuracy']}")Copied
Writing accelerate_scripts/15_accelerate_base_code_fp8_bs512.py
Lo ejecutamos
InputPython%%time!accelerate launch accelerate_scripts/15_accelerate_base_code_fp8_bs512.pyCopied
Inferencia de modelos
Uso del ecosistema de Hugging Face
Vamos a ver cómo hacer inferencia de grandes modelos con la librería transformers de Hugging Face.
Inferencia con pipeline
Si usamos el ecosistema de Hugging Face es muy sencillo, ya que todo se produce por debajo sin tener que hacer nosotros mucho. En el caso de usar pipeline, que es la manera más sencilla de hacer inferencia con la librería transformers, simplemente tenemos que decirle el modelo que queremos usar y, muy importante, pasarle device_map="auto". Esto hará que por debajo accelerate distribuya el modelo entre las distintas GPUs, RAM de la CPU o disco duro si es necesario
Hay más posibles valores para device_map, que los veremos más adelante, pero de momento quédate con "auto".
Vamos a usar el modelo Llama3 8B, que como su nombre indica es un modelo de unos 8 mil millones de parámetros. Como cada parámetro, por defecto, está en formato FP32, que corresponde a 4 bytes (32 bits), eso quiere decir que si multiplicamos 8 mil millones de parámetros por 4 bytes, nos queda que necesitaría una GPU con unos 32 GB de VRAM.
En mi caso tengo 2 GPUs de 24 GB de VRAM, por lo que no entraría en una sola GPU. Pero gracias a poner device_map="auto", accelerate distribuirá el modelo entre las dos GPUs y podré realizar la inferencia
InputPython%%writefile accelerate_scripts/16_inference_with_pipeline.pyfrom transformers import pipelinecheckpoints = "meta-llama/Meta-Llama-3-8B-Instruct"generator = pipeline(model=checkpoints, device_map="auto")prompt = "Conoces accelerate de hugging face?"output = generator(prompt)print(output)Copied
Overwriting accelerate_scripts/09_inference_with_pipeline.py
Ahora lo ejecutamos, solo que como pipeline usa por debajo accelerate, no necesitamos ejecutarlo con accelerate launch script.py sino que con python script.py vale
InputPython!python accelerate_scripts/16_inference_with_pipeline.pyCopied
Loading checkpoint shards: 100%|██████████████████| 4/4 [00:09<00:00, 2.27s/it]Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.[{'generated_text': 'Conoces accelerate de hugging face? ¿Qué es el modelo de lenguaje de transformers y cómo se utiliza en el marco de hugging face? ¿Cómo puedo utilizar modelos de lenguaje de transformers en mi aplicación? ¿Qué son los tokenizers y cómo se utilizan en el marco de hugging face? ¿Cómo puedo crear un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los datasets y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar datasets para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar finetuning para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los checkpoints y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar checkpoints para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los evaluadores y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar evaluadores para evaluar el rendimiento de un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los pre-trainados y cómo se utilizan en el marco de hugging face? ¿Cómo puedo utilizar pre-trainados para entrenar un modelo de lenguaje personalizado utilizando transformers y hugging face? ¿Qué son los finetuning'}]
Como se puede ver, no ha respondido, sino que ha seguido haciendo preguntas. Esto es porque Llama3 es un modelo de lenguaje que lo que hace es predecir el siguiente token, así que con el prompt que le he pasado, ha considerado que los siguientes mejores tokens son unos que corresponden a más preguntas. Lo cual tiene sentido, porque hay veces que la gente tiene dudas sobre un tema y genera muchas preguntas, así que para que nos conteste a la pregunta hay que condicionarle un poco
InputPython%%writefile accelerate_scripts/17_inference_with_pipeline_condition.pyfrom transformers import pipelinecheckpoints = "meta-llama/Meta-Llama-3-8B-Instruct"generator = pipeline(model=checkpoints, device_map="auto")prompt = "Conoces accelerate de hugging face?"messages = [{"role": "system","content": "Eres un chatbot amigable que siempre intenta solucionar las dudas",},{"role": "user", "content": f"{prompt}"},]output = generator(messages)print(output[0]['generated_text'][-1])Copied
Overwriting accelerate_scripts/10_inference_with_pipeline_condition.py
Como ves, se ha generado un mensaje con roles, condicionando el modelo y con el prompt
InputPython!python accelerate_scripts/17_inference_with_pipeline_condition.pyCopied
Loading checkpoint shards: 100%|██████████████████| 4/4 [00:09<00:00, 2.41s/it]Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.{'role': 'assistant', 'content': '¡Hola! Sí, conozco Accelerate de Hugging Face. Accelerate es una biblioteca de Python desarrollada por Hugging Face que se enfoca en simplificar y acelerar el entrenamiento y la evaluación de modelos de lenguaje en diferentes dispositivos y entornos. Con Accelerate, puedes entrenar modelos de lenguaje en diferentes plataformas y dispositivos, como GPUs, TPUs, CPUs y servidores, sin necesidad de cambiar el código de tu modelo. Esto te permite aprovechar al máximo la potencia de cálculo de tus dispositivos y reducir el tiempo de entrenamiento. Accelerate también ofrece varias características adicionales, como: * Soporte para diferentes frameworks de machine learning, como TensorFlow, PyTorch y JAX. * Integración con diferentes sistemas de almacenamiento y procesamiento de datos, como Amazon S3 y Google Cloud Storage. * Soporte para diferentes protocolos de comunicación, como HTTP y gRPC. * Herramientas para monitorear y depurar tus modelos en tiempo real. En resumen, Accelerate es una herramienta muy útil para desarrolladores de modelos de lenguaje que buscan simplificar y acelerar el proceso de entrenamiento y evaluación de sus modelos. ¿Tienes alguna pregunta específica sobre Accelerate o necesitas ayuda para implementarlo en tu proyecto?'}
Ahora la respuesta sí responde a nuestro prompt
Inferencia con AutoClass
Por último vamos a ver cómo hacer la inferencia solo con AutoClass.
InputPython%%writefile accelerate_scripts/18_inference_with_autoclass.pyfrom transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamercheckpoints = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoints, device_map="auto")model = AutoModelForCausalLM.from_pretrained(checkpoints, device_map="auto")streamer = TextStreamer(tokenizer)prompt = "Conoces accelerate de hugging face?"tokens_input = tokenizer([prompt], return_tensors="pt").to(model.device)_ = model.generate(**tokens_input, streamer=streamer, max_new_tokens=500, do_sample=True, top_k=50, top_p=0.95, temperature=0.7)Copied
Overwriting accelerate_scripts/11_inference_with_autoclass.py
Como se puede ver, se ha creado el objeto streamer que luego se le pasa al método generate del modelo. Esto es útil para que se vaya imprimiendo cada palabra a medida que se va generando y no haya que esperar a que se genere toda la salida para imprimirla
InputPython!python accelerate_scripts/18_inference_with_autoclass.pyCopied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.Loading checkpoint shards: 100%|██████████████████| 4/4 [00:09<00:00, 2.28s/it]Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.<|begin_of_text|>Conoces accelerate de hugging face? Si es así, puedes utilizar la biblioteca `transformers` de Hugging Face para crear un modelo de lenguaje que pueda predecir la siguiente palabra en una secuencia de texto.Aquí te muestro un ejemplo de cómo hacerlo:```import pandas as pdimport torchfrom transformers import AutoModelForSequenceClassification, AutoTokenizer# Cargar el modelo y el tokenizadormodel_name = "bert-base-uncased"model = AutoModelForSequenceClassification.from_pretrained(model_name)tokenizer = AutoTokenizer.from_pretrained(model_name)# Cargar el conjunto de datostrain_df = pd.read_csv("train.csv")test_df = pd.read_csv("test.csv")# Preprocesar los datostrain_texts = train_df["text"]train_labels = train_df["label"]test_texts = test_df["text"]...input_ids = batch[0].to(device)attention_mask = batch[1].to(device)labels = batch[2].to(device)optimizer.zero_grad()outputs = model(input_ids, attention_mask=attention_mask, labels=labels)loss = criterion(outputs, labels)loss.backward()optimizer.step()total_loss += loss.item()print(f"Epoch {epoch+1}, Loss: {total
Uso de PyTorch
Normalmente la manera de hacer inferencias con pytorch es crear un modelo con los pesos inicializados aleatoriamente y a continuación cargar un state dict con los pesos del modelo preentrenado, así que para obtener ese state dict vamos a hacer primero una pequeña trampa y nos lo vamos a descargar
InputPythonimport torchimport torchvision.models as modelsmodel = models.resnet152(weights=models.ResNet152_Weights.IMAGENET1K_V1)torch.save(model.state_dict(), 'accelerate_scripts/resnet152_pretrained.pth')Copied
Downloading: "https://download.pytorch.org/models/resnet152-394f9c45.pth" to /home/maximo.fernandez/.cache/torch/hub/checkpoints/resnet152-394f9c45.pth100%|██████████| 230M/230M [02:48<00:00, 1.43MB/s]
Ahora que tenemos el state dict vamos a hacer inferencia como se hace normalmente en PyTorch
InputPythonimport torchimport torchvision.models as modelsdevice = "cuda" if torch.cuda.is_available() else "cpu" # Set deviceresnet152 = models.resnet152().to(device) # Create model with random weights and move to devicestate_dict = torch.load('accelerate_scripts/resnet152_pretrained.pth', map_location=device) # Load pretrained weights into device memoryresnet152.load_state_dict(state_dict) # Load this weights into the modelinput = torch.rand(1, 3, 224, 224).to(device) # Random image with batch size 1output = resnet152(input)output.shapeCopied
torch.Size([1, 1000])
Vamos a explicar qué ha pasado
- Cuando hemos hecho
resnet152 = models.resnet152().to(device)se ha cargado una ResNet152 con pesos aleatorios en la memoria de la GPU - Cuando hemos hecho
state_dict = torch.load('accelerate_scripts/resnet152_pretrained.pth', map_location=device)se ha cargado un diccionario con los pesos entrenados en la memoria de la GPU - Cuando hemos hecho
resnet152.load_state_dict(state_dict)se han asignado esos pesos preentrenados al modelo
Es decir, se han cargado dos veces el modelo en la memoria de la GPU
Te puedes estar preguntando por qué hemos hecho primero
model = models.resnet152(weights=models.ResNet152_Weights.IMAGENET1K_V1)
torch.save(model.state_dict(), 'accelerate_scripts/resnet152_pretrained.pth')Para luego hacer
resnet152 = models.resnet152().to(device)
state_dict = torch.load('accelerate_scripts/resnet152_pretrained.pth', map_location=device)
resnet152.load_state_dict(state_dict)Y por qué no usamos directamente
model = models.resnet152(weights=models.ResNet152_Weights.IMAGENET1K_V1)Y nos dejamos de guardar el state dict para luego cargarlo. Bueno, pues porque Pytorch, por debajo hace lo mismo que hemos hecho. Así que para poder ver todo el proceso hemos hecho en varias líneas lo que Pytorch hace en una
Esta manera de trabajar ha funcionado bien hasta ahora, mientras que los modelos tenían un tamaño manejable por las GPUs de usuario. Pero desde la llegada de los LLMs este enfoque no tiene sentido
Por ejemplo, un modelo de 6B de parámetros ocuparía en la memoria 24 GB, y como se carga dos veces con esta manera de trabajar, haría falta tener una GPU de 48 GB.
Así que para arreglar esto, la manera de cargar un modelo preentrenado de PyTorch es:
- Crear un modelo vacío con
init_empty_weightsque no ocupará memoria RAM - Luego cargar los pesos con
load_checkpoint_and_dispatchque cargará un punto de control dentro del modelo vacío y distribuirá los pesos para cada capa en todos los dispositivos que se tengan disponibles (GPU, CPU, RAM y disco duro), gracias a ponerdevice_map="auto"
InputPythonimport torchimport torchvision.models as modelsfrom accelerate import init_empty_weights, load_checkpoint_and_dispatchwith init_empty_weights():resnet152 = models.resnet152()resnet152 = load_checkpoint_and_dispatch(resnet152, checkpoint='accelerate_scripts/resnet152_pretrained.pth', device_map="auto")device = "cuda" if torch.cuda.is_available() else "cpu"input = torch.rand(1, 3, 224, 224).to(device) # Random image with batch size 1output = resnet152(input)output.shapeCopied
torch.Size([1, 1000])
Cómo funciona accelerate por debajo
En este vídeo se puede ver gráficamente cómo funciona accelerate por debajo
Inicialización de un modelo vacío
Accelerate crea el esqueleto de un modelo vacío mediante init_empty_weights para que ocupe la menor cantidad de memoria posible
Por ejemplo, veamos cuánta RAM tengo ahora disponible en mi ordenador
InputPythonimport psutildef get_ram_info():ram = dict(psutil.virtual_memory()._asdict())print(f"Total RAM: {(ram['total']/1024/1024/1024):.2f} GB, Available RAM: {(ram['available']/1024/1024/1024):.2f} GB, Used RAM: {(ram['used']/1024/1024/1024):.2f} GB")get_ram_info()Copied
Total RAM: 31.24 GB, Available RAM: 22.62 GB, Used RAM: 7.82 GB
Tengo unos 22 GB de RAM disponibles
Ahora vamos a intentar crear un modelo 5000x1000x1000 parámetros, es decir, de 5B de parámetros, si cada parámetro está en FP32, supone 20 GB de RAM
InputPythonimport torchfrom torch import nnmodel = nn.Sequential(*[nn.Linear(5000, 1000) for _ in range(1000)])Copied
Si volvemos a ver la RAM
InputPythonget_ram_info()Copied
Total RAM: 31.24 GB, Available RAM: 3.77 GB, Used RAM: 26.70 GB
Como vemos, ahora solo tenemos 3 GB de RAM disponibles
Ahora vamos a eliminar el modelo para liberar RAM
InputPythondel modelget_ram_info()Copied
Total RAM: 31.24 GB, Available RAM: 22.44 GB, Used RAM: 8.03 GB
Volvemos a tener unos 22 GB de RAM disponibles
Vamos ahora a usar init_empty_weights de accelerate y luego vemos la RAM
InputPythonfrom accelerate import init_empty_weightswith init_empty_weights():model = nn.Sequential(*[nn.Linear(5000, 1000) for _ in range(1000)])get_ram_info()Copied
Total RAM: 31.24 GB, Available RAM: 22.32 GB, Used RAM: 8.16 GB
Antes teníamos exactamente 22.44 GB libres y tras crear el modelo con init_empty_weights tenemos 22.32 GB. El ahorro en RAM es enorme. Casi no se ha ocupado RAM para crear el modelo.
Esto se basa en el metadispositivo introducido en PyTorch 1.9, por lo que es importante que para usar accelerate tengamos una versión de PyTorch posterior
Carga de los pesos
Una vez hemos inicializado el modelo, tenemos que cargarle los pesos, lo cual hacemos mediante load_checkpoint_and_dispatch, que como su nombre indica, carga los pesos y los envía al dispositivo o dispositivos que sean necesarios.
















{kind=link}