Para mí, la mejor descripción de mixtral-8x7b es la siguiente imagen

Entre la salida de gemini y la salida de mixtra-8x7b hubo una diferencia de muy pocos días. Los dos primeros días después del lanzamiento de gemini se habló bastante de ese modelo, pero en cuanto salió mixtral-8x7b, gemini se olvidó por completo y toda la comunidad no paró de hablar de mixtral-8x7b.
Y no es para menos, viendo sus benchmarks, podemos ver que está al nivel de modelos como llama2-70B y GPT3.5, pero con la diferencia de que mientras mixtral-8x7b tiene solo 46.7B de parámetros, llama2-70B tiene 70B y GPT3.5 tiene 175B.
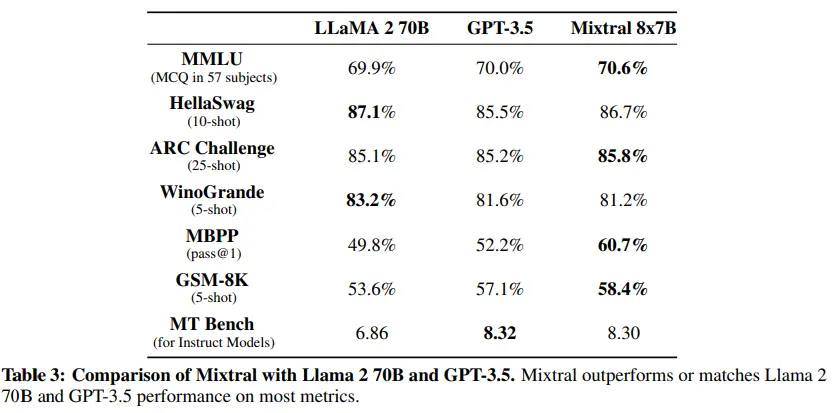
Número de parámetros
Como su nombre indica, mixtral-8x7b es un conjunto de 8 modelos de 7B de parámetros, por lo que podríamos pensar que tiene 56B de parámetros (7Bx8), pero no es así. Como explica Andrej Karpathy solo los bloques Feed forward de los transformers se multiplican por 8, el resto de parámetros se comparten entre los 8 modelos. Por lo que al final el modelo tiene 46.7B de parámetros.
Mixture of Experts (MoE)
Como hemos dicho, el modelo es un conjunto de 8 modelos de 7B de parámetros, de ahí MoE, que significa Mixture of Experts. Cada uno de los 8 modelos se entrena de forma independiente, pero cuando se hace la inferencia un router decide la salida de qué modelo es la que se va a usar.
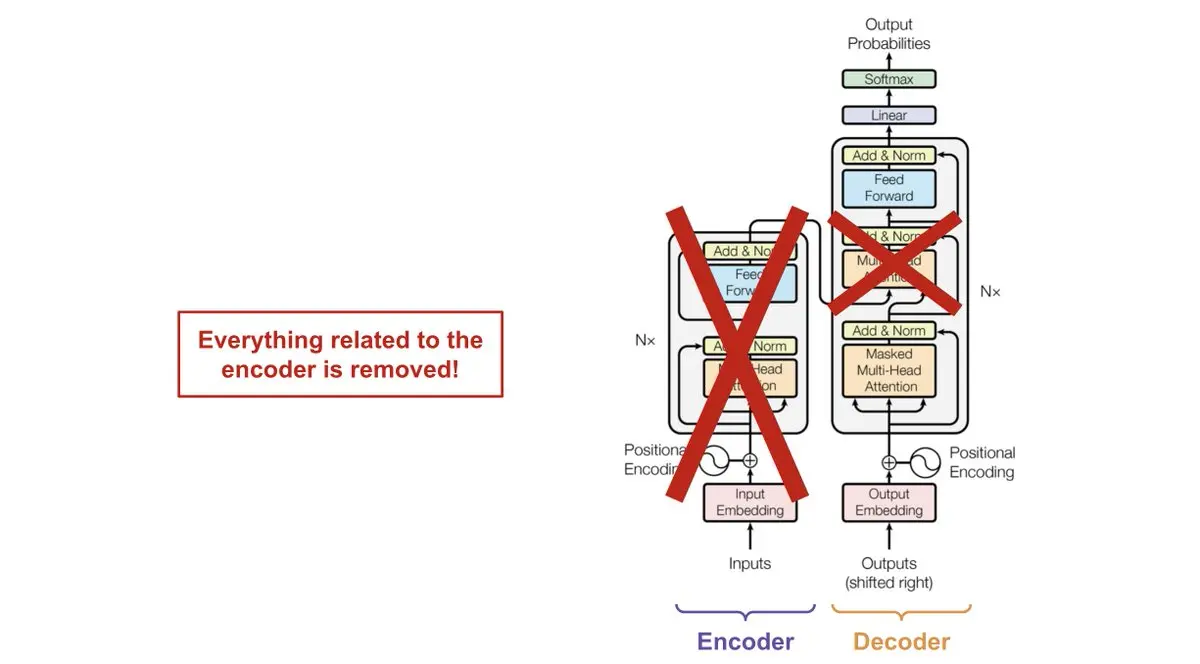
En la siguiente imagen podemos ver cómo es la arquitectura de un Transformer
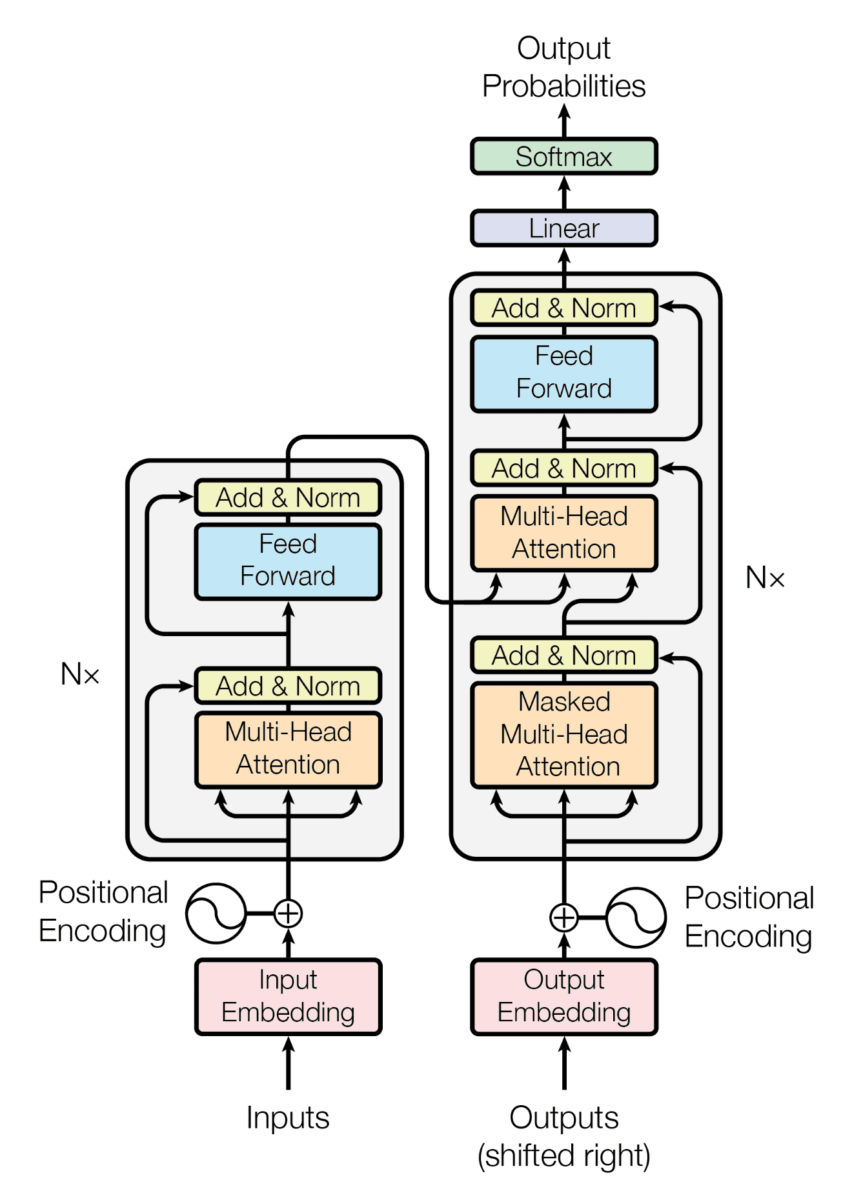
Si no la conoces, no pasa nada. Lo importante es que esta arquitectura consiste en un encoder y un decoder
Los LLMs son modelos que solo tienen el decoder, por lo que no tienen encoder. Puedes ver que en la arquitectura hay tres módulos de atención, uno de ellos de hecho conecta el encoder con el decoder. Pero como los LLMs no tienen encoder, no es necesario el módulo de atención que une el decoder y el decoder
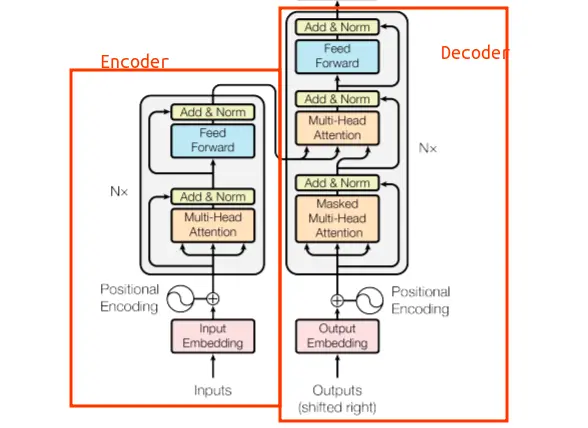
Ahora que sabemos cómo es la arquitectura de un LLM, podemos ver cómo es la arquitectura de mixtral-8x7b. En la siguiente imagen podemos ver la arquitectura del modelo
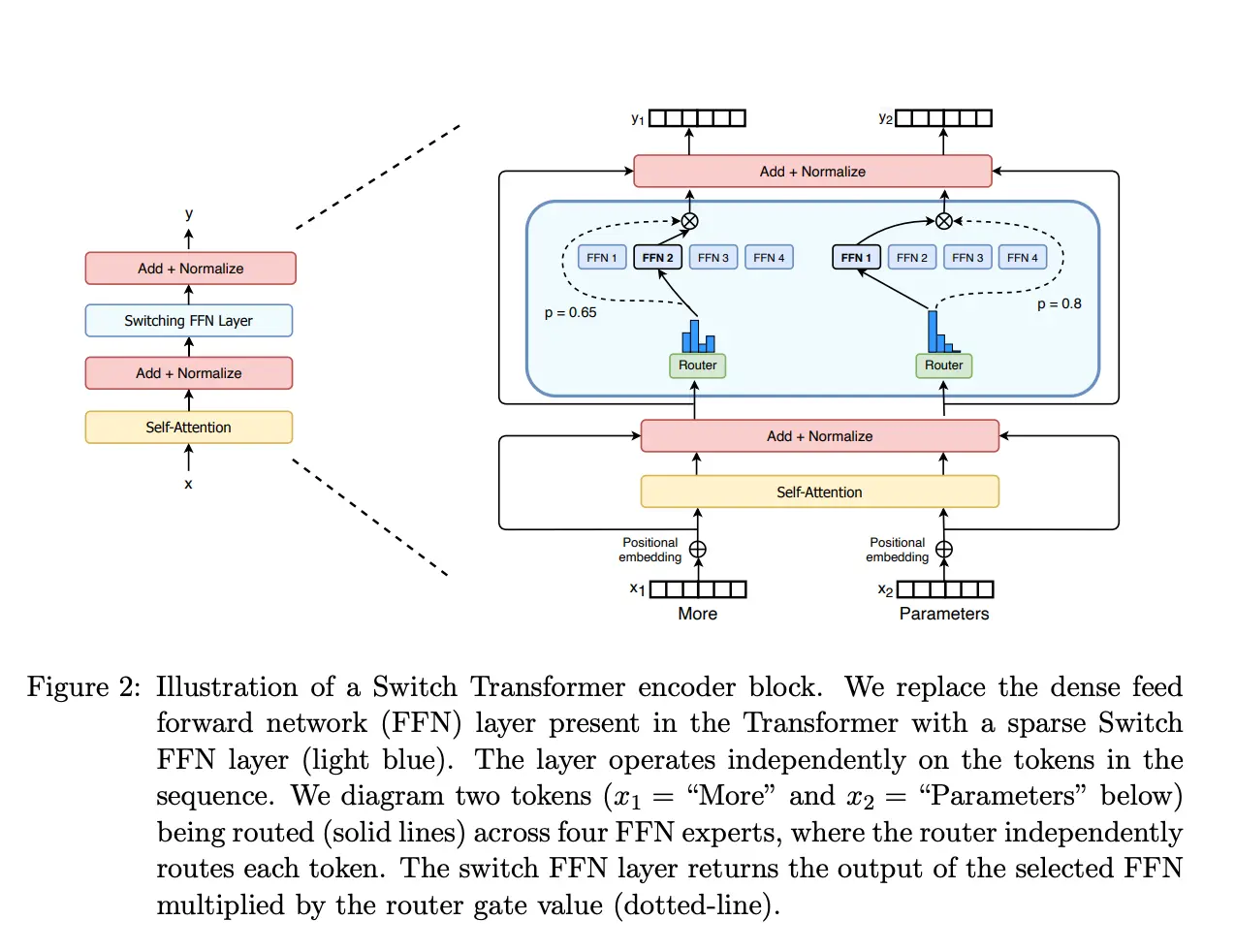
Como se puede ver, la arquitectura consiste en el decoder de un Transformer de 7B de parámetros, solo que la capa Feed forward consiste en 8 capas Feed forward con un router que elige cuál de las 8 capas Feed forward se va a usar. En la imagen anterior solo se muestran cuatro capas Feed forward, supongo que es para simplificar el diagrama, pero en realidad hay 8 capas Feed forward. También se ven dos caminos para dos palabras distintas, la palabra More y la palabra Parameters y cómo el router elige qué Feed forward se va a usar para cada palabra.
Viendo la arquitectura podemos entender por qué el modelo tiene 46.7B de parámetros y no 56B. Como hemos dicho, solo los bloques Feed forward se multiplican por 8, el resto de parámetros se comparten entre los 8 modelos
Uso de Mixtral-8x7b en la nube
Por desgracia, para usar mixtral-8x7b en local es complicado, ya que los requisitos de hardware son los siguientes
- float32: VRAM > 180 GB, es decir, como cada parámetro ocupa 4 bytes, necesitamos 46.7B * 4 = 186.8 GB de VRAM solo para almacenar el modelo, además a eso hay que sumarle la VRAM que se necesita para almacenar los datos de entrada y salida
- float16: VRAM > 90 GB, en este caso cada parámetro ocupa 2 bytes, por lo que necesitamos 46.7B * 2 = 93.4 GB de VRAM solo para almacenar el modelo, además a eso hay que sumarle la VRAM que se necesita para almacenar los datos de entrada y salida
- 8-bit: VRAM > 45 GB, aquí cada parámetro ocupa 1 byte, por lo que necesitamos 46.7B * 1 = 46.7 GB de VRAM solo para almacenar el modelo, además a eso hay que sumarle la VRAM que se necesita para almacenar los datos de entrada y salida
- 4-bit: VRAM > 23 GB, aquí cada parámetro ocupa 0.5 bytes, por lo que necesitamos 46.7B * 0.5 = 23.35 GB de VRAM solo para almacenar el modelo, además a eso hay que sumarle la VRAM que se necesita para almacenar los datos de entrada y salida
Necesitamos unas GPUs muy potentes para poder ejecutarlo, incluso cuando usamos el modelo cuantizado a 4 bits.
Por tanto, la forma más sencilla de usar Mixtral-8x7B es usandolo ya desplegado en la nube. He encontrado varios sitios donde lo puedes usar
Uso de Mixtral-8x7b en huggingface chat
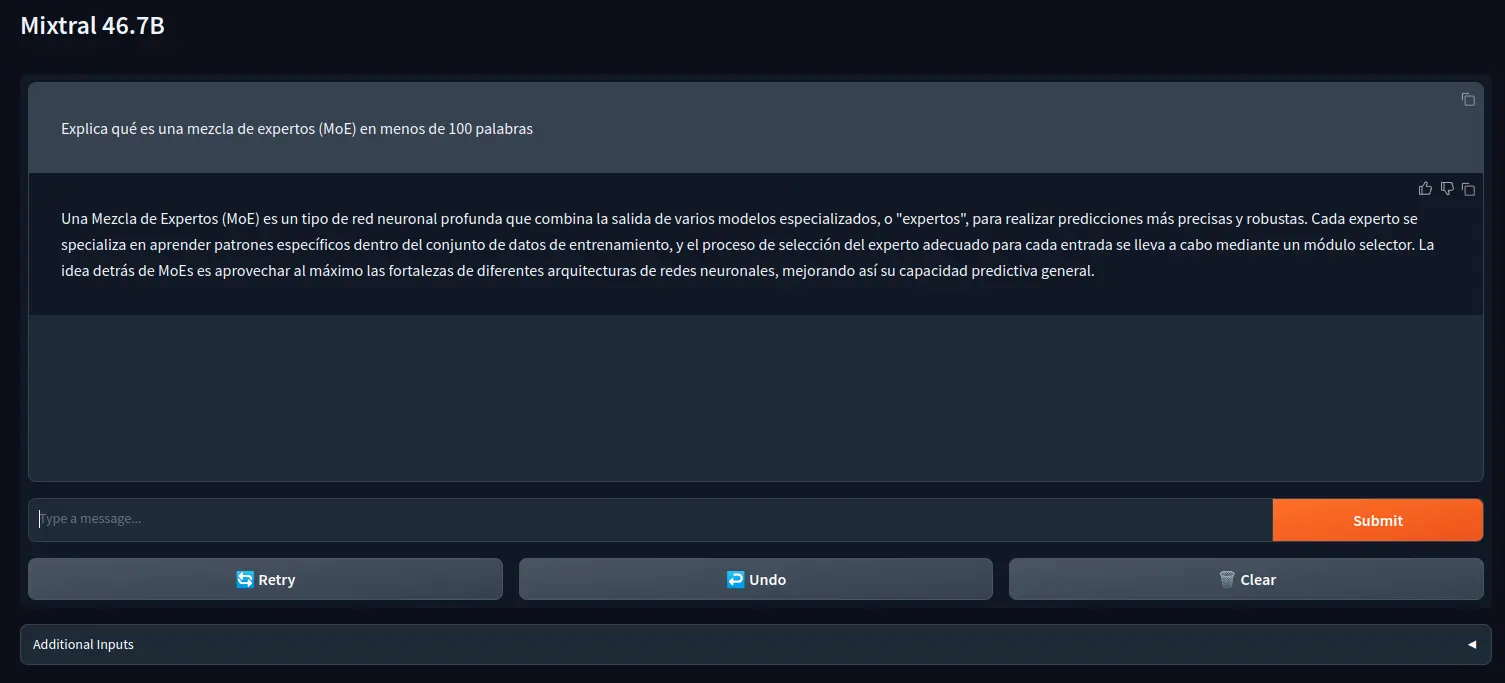
El primero es en huggingface chat. Para poder usarlo hay que darle a la rueda dentada dentro de la caja Current Model y seleccionar Mistral AI - Mixtral-8x7B. Una vez seleccionado, ya puedes empezar a hablar con el modelo.
Una vez dentro seleccionar mistralai/Mixtral-8x7B-Instruct-v0.1 y por último darle al botón Activate. Ahora podremos probar el modelo
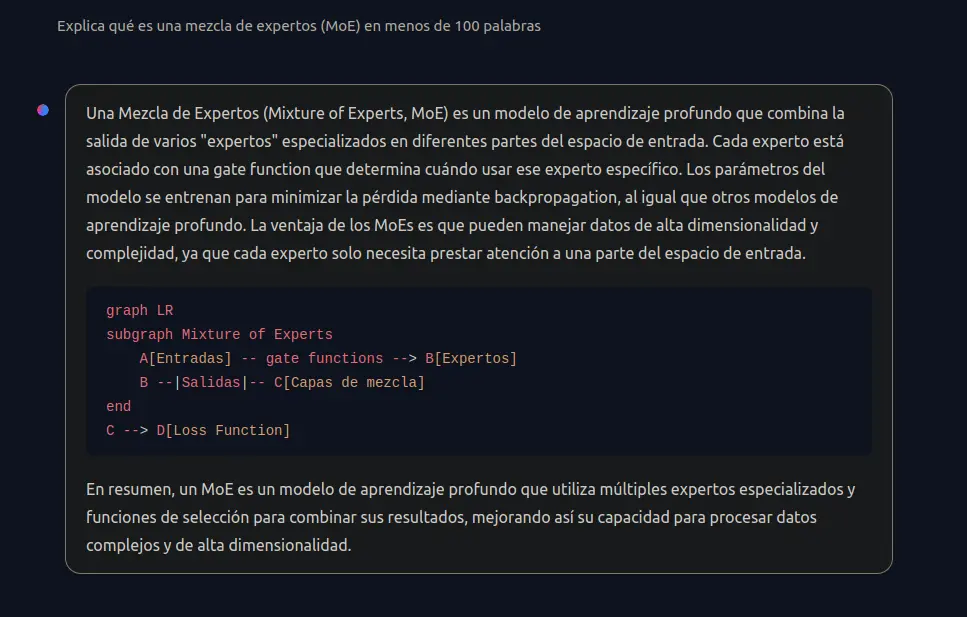
Como se puede ver, le he preguntado en español qué es MoE y me lo ha explicado
Uso de Mixtral-8x7b en Perplexity Labs
Otra opción es usar Perplexity Labs. Una vez dentro hay que seleccionar mixtral-8x7b-instruct en un desplegable que hay en la parte inferior derecha
Como se puede ver, también le he preguntado en español qué es MoE y me lo ha explicado
Uso de Mixtral-8x7b en local a traves de la API de huggingface
Una manera de usarlo en local, tengas los recursos HW que tengas es a través de la API de huggingface. Para ello hay que instalar la librería huggingface-hub de huggingface
InputPython%pip install huggingface-hubCopied
Aquí se muestra una implementación con gradio
InputPythonfrom huggingface_hub import InferenceClientimport gradio as grclient = InferenceClient("mistralai/Mixtral-8x7B-Instruct-v0.1")def format_prompt(message, history):prompt = "<s>"for user_prompt, bot_response in history:prompt += f"[INST] {user_prompt} [/INST]"prompt += f" {bot_response}</s> "prompt += f"[INST] {message} [/INST]"return promptdef generate(prompt, history, system_prompt, temperature=0.9, max_new_tokens=256, top_p=0.95, repetition_penalty=1.0,):temperature = float(temperature)if temperature < 1e-2:temperature = 1e-2top_p = float(top_p)generate_kwargs = dict(temperature=temperature, max_new_tokens=max_new_tokens, top_p=top_p, repetition_penalty=repetition_penalty, do_sample=True, seed=42,)formatted_prompt = format_prompt(f"{system_prompt}, {prompt}", history)stream = client.text_generation(formatted_prompt, **generate_kwargs, stream=True, details=True, return_full_text=False)output = ""for response in stream:output += response.token.textyield outputreturn outputadditional_inputs=[gr.Textbox(label="System Prompt", max_lines=1, interactive=True,),gr.Slider(label="Temperature", value=0.9, minimum=0.0, maximum=1.0, step=0.05, interactive=True, info="Higher values produce more diverse outputs"),gr.Slider(label="Max new tokens", value=256, minimum=0, maximum=1048, step=64, interactive=True, info="The maximum numbers of new tokens"),gr.Slider(label="Top-p (nucleus sampling)", value=0.90, minimum=0.0, maximum=1, step=0.05, interactive=True, info="Higher values sample more low-probability tokens"),gr.Slider(label="Repetition penalty", value=1.2, minimum=1.0, maximum=2.0, step=0.05, interactive=True, info="Penalize repeated tokens")]gr.ChatInterface(fn=generate,chatbot=gr.Chatbot(show_label=False, show_share_button=False, show_copy_button=True, likeable=True, layout="panel"),additional_inputs=additional_inputs,title="Mixtral 46.7B",concurrency_limit=20,).launch(show_api=False)Copied