Aviso: Este post foi traduzido para o português usando um modelo de tradução automática. Por favor, me avise se encontrar algum erro.
As redes neurais foram criadas entre as décadas de 50 e 60, imitando o funcionamento da sinapse entre os neurônios do ser humano; ou seja, as redes neurais imitam nossos neurônios.
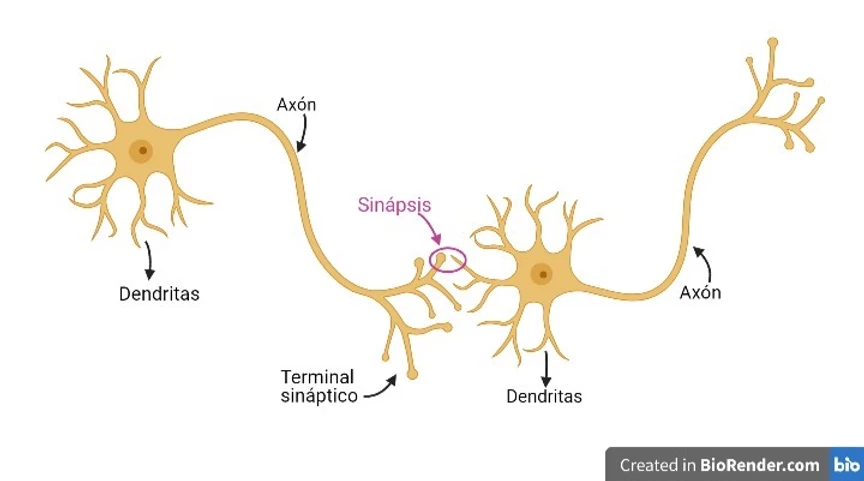
Nossos neurônios têm *Dendritos* por onde chegam os potenciais elétricos e o *Axônio* por onde saem novos potenciais elétricos. Dessa forma, é possível conectar os *axônios* de alguns neurônios com os *dendritos* de outros, formando redes neurais. Cada neurônio receberá diferentes potenciais elétricos por seus *dendritos*; estes processarão esses potenciais, fazendo com que surja um novo potencial elétrico por seu *axônio*.
Portanto, as neuronas podem ser entendidas como elementos que recebem sinais de outras neuronas, os processam e enviam outro sinal para outra neurona.
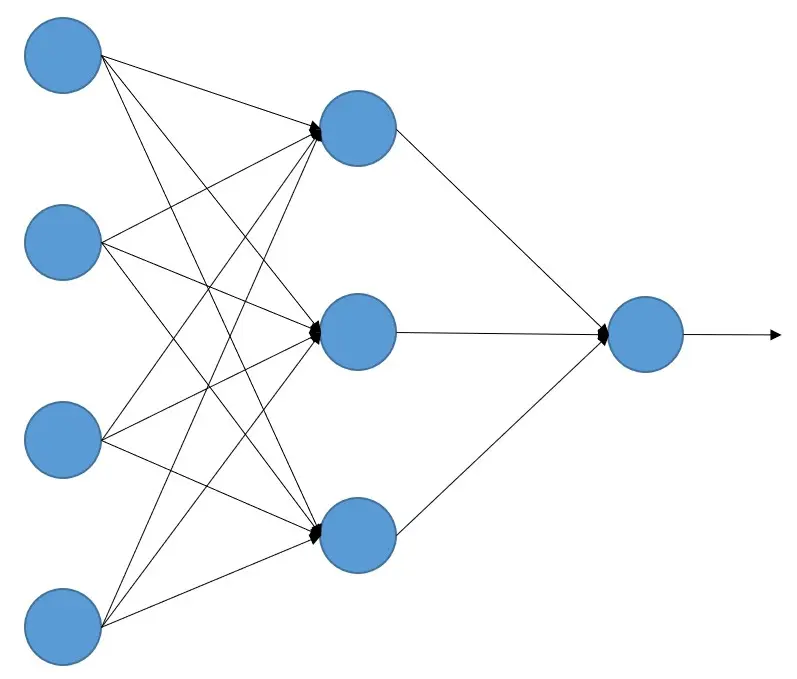
Com essa analogia foram criadas as redes neurais artificiais, que são um conjunto de elementos que recebem sinais de outros neurônios, os processam e devolvem outros sinais. Podem ser entendidas como unidades que realizam cálculos com os sinais que recebem e devolvem outro sinal, ou seja, como unidades de processamento.
Como as redes neurais aprendem?
Como dissemos, as redes neurais artificiais são um conjunto de 'neurônios' que realizam um cálculo de todos os sinais que recebem, mas como sabemos quais cálculos cada neurônio deve fazer para que uma rede neural artificial (daqui em diante vamos chamá-las apenas de redes neurais) realize a tarefa que desejamos?
Isso é feito por meio do aprendizado de máquina. À rede neural são fornecidos vários exemplos rotulados para que ela aprenda. Por exemplo, se quisermos fazer uma rede que distinga entre cães e gatos, forneceremos à rede várias imagens de cães informando que são cães e várias imagens de gatos informando que são gatos.
Quando a rede possui o conjunto de dados rotulados (neste caso, as imagens de cachorros e gatos), cada imagem é passada para a rede, ela gera um resultado e, se não for o esperado (neste caso cachorro ou gato), por meio do algoritmo de backpropagation (propagação para trás), que estudaremos mais adiante (isto é apenas uma introdução teórica), os cálculos feitos por cada neurônio vão sendo corrigidos, de modo que, à medida que um grande número de imagens vai sendo apresentado, a rede neural vai melhorando cada vez mais até que acerta (no nosso caso, distingue entre um cachorro e um gato).
Se você pensar bem, isso é o mesmo que acontece no nosso cérebro. Quem é pai ou mãe já deve ter vivido isso. Quando você tem um filho ou filha, não explica como é um cachorro ou como é um gato; conforme vai vendo cachorros e gatos, vai dizendo "*Olha, um cachorro!*" ou "*Ali está o gato que faz miau!*". E a criança, em seu cérebro, vai fazendo o processo de aprendizagem até que um dia diz para você "*Um au au!*"
O inverno da inteligência artificial
Pois bem, já temos tudo o que precisamos, um sistema que aprende da mesma forma que o cérebro humano e algoritmos que o imitam. Só precisamos de dados rotulados e computadores que façam o cálculo... Pois não!
Por um lado, viu-se que era necessária uma grande quantidade de dados para que as redes neurais aprendessem. Coloque-se na situação: como expliquei antes, as redes neurais foram criadas entre as décadas de 50 e 60, naquela época não havia grandes bases de dados, e muito menos etiquetadas!
Além disso, as poucas bases de dados que pudessem existir eram muito pequenas, já que a capacidade de armazenamento era muito reduzida. Hoje em dia, nos nossos telefones móveis, podemos ter GB de memória, mas naquela época isso era impensável, e até há pouco tempo ainda continuava sendo impensável.
Era comum que houvesse *bancos de dados analógicos*, ou seja, uma grande quantidade de documentos guardados em bibliotecas, universidades, etc. Mas o que era necessário era que esses dados fossem digitalizados e introduzidos nas redes. Coloque-se novamente na situação: década entre os anos 50 e 60.
Além disso, os computadores eram muito lentos realizando a quantidade de cálculos que esses algoritmos precisavam, portanto, o treinamento de uma rede muito simples levava muito tempo (dias ou semanas) e, além disso, não produzia resultados muito bons.
Todas essas dificuldades técnicas duraram muitos anos, nos anos 90 ainda era comum ter as coisas guardadas em disquetes, cuja capacidade podia chegar no máximo a 2 MB!
Por esses motivos, esses algoritmos foram descartados e até mal vistos dentro da comunidade científica. Quem tinha interesse em pesquisá-los tinha que fazê-lo quase como um passatempo e sem divulgar muito.

Revolução da inteligência artificial
No entanto, em 2012 ocorre um fato que revoluciona tudo. Mas vamos voltar alguns anos para colocar em contexto.
Em 2007 foi lançado no mercado o primeiro iPhone (e posteriormente uma porção de smartphones de outras marcas), o que colocou nas mãos de quase todo mundo um dispositivo com a capacidade de tirar fotos com qualidade cada vez maior, escrever textos, músicas, áudios, etc. E cada vez com mais capacidade de armazenamento. Por isso, em poucos anos foi possível criar grandes bases de dados, digitalizadas e etiquetadas.
Portanto, já tínhamos 2 dos 3 problemas resolvidos. Tínhamos grande capacidade de gerar dados em formato digital, etiquetados e capacidade de armazená-los.
Por outro lado, nessa época, devido ao crescente mundo dos videogames, as placas gráficas ou GPUs estavam cada vez mais potentes devido ao mercado cada vez maior. E aconteceu que os cálculos realizados por essas GPUs eram muito parecidos com os que os algoritmos das redes neurais necessitavam.
Portanto, já tínhamos dispositivos que eram capazes de realizar os cálculos necessários em um tempo aceitável.
Já tínhamos tudo, era apenas uma questão de tempo até que alguém juntasse tudo.
Competição ImageNet
Em 2010, começou a ser lançada uma competição de reconhecimento de imagens por computador chamada ILSVRC (ImageNet Large Scale Visual Recognition Challenge). Esta contém mais de 14 milhões de imagens classificadas em 1000 categorias diferentes. Ganha a equipe que tiver o menor percentual de erro.
Nos dois primeiros anos, em 2010 e 2011, os vencedores foram obtidos com uma taxa de erro semelhante, entre 25% e 30%, mas em 2012 a competição foi vencida por uma equipe que participou com uma rede neural chamada AlexNet e conseguiu um erro acima de 15%, ou seja, uma diferença de 10 pontos. A partir daí, todos os anos equipes com redes neurais melhores venceram até chegar um momento em que a taxa de erro do ser humano, que é de 5%, foi superada.
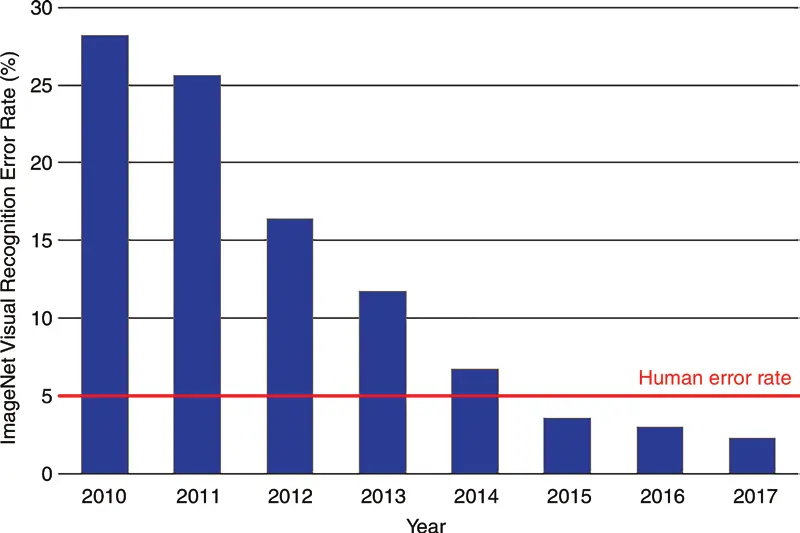
Esse marco na competição em 2012 fez a comunidade científica perceber que as redes neurais funcionavam e o grande poder que tinham. Desde então, a pesquisa não parou, fazendo com que de um ano para o outro os avanços fossem enormes.
Exemplos de redes neurais
Pode-se ver como a geração de imagens de rostos por meio do uso de uma arquitetura de rede neural chamada GAN melhorou significativamente desde 2014.

Podemos acessar o site this person does not exist, onde toda vez que entrarmos será exibida a imagem de uma pessoa que não existe e que foi gerada por uma rede neural. Ou podemos acessar o site this X does not exist, onde são mostradas páginas que fazem o mesmo, mas com outros temas.
A OpenAI criou o Dall-e 2, que é uma rede à qual você pede para desenhar algo como um astronauta descansando em um resort tropical em um estilo fotorrealista.

A Nvidia criou o GauGan2, com o qual, a partir de um rabisco mal feito, ele o transforma em uma bela paisagem.

Podemos ver como, graças às redes neurais, a Tesla conseguiu criar seu piloto automático

E como não ficar de queixo caído com os deepfakes
A cada vez surgem exemplos que surpreendem ainda mais e, provavelmente, quando você estiver assistindo a este curso, os exemplos que coloquei já serão muito antigos e haverá outros muito mais novos e impressionantes.
















