
Aunque a medida que los LLMs van aumentando de tamaño y van surgiendo nuevas capacidades, tenemos un problema y son las alucionaciones. Los autores del paper DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models proponen un método para evitar este problema.
Proponen un enfoque de decodificación contrastiva, donde la probabilidad de salida de la siguiente palabra se obtiene de la diferencia en los logits entre una capa superior y una inferior. Al enfatizar el conocimiento de las capas superiores y restarle importancia al de las inferiores, podemos hacer que los LM sean más factuales y, por lo tanto, reducir las alucinaciones.
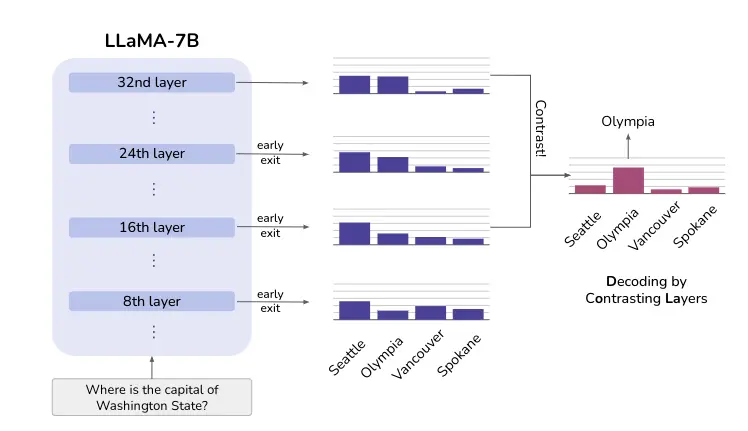
En la siguiente figura se muestra esta idea. Mientras que Seattle mantiene una alta probabilidad en todas las capas, la probabilidad de la respuesta correcta Olympia aumenta después de que las capas superiores inyecten más conocimiento factual. Contrastar las diferencias entre las distintas capas puede revelar la respuesta correcta en este caso
Método
Un LLM consiste en una capa de embedding, varios transformers secuenciales y a continuación una capa de salida. Lo que proponen es medir la salida de cada transformer mediante la divergencia de Jensen-Shannon (JSD)
En la siguiente figura se puede ver esta medida a la salida de cada transformer para una frase de entrada al LLM. Cada columna corresponde a un token de la frase.
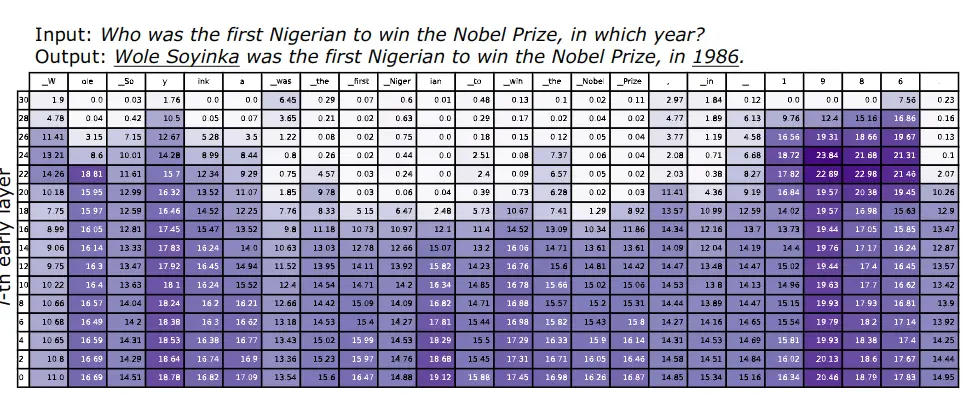
Se pueden observar dos patrones
- El primero ocurre cuando se predicen entidades de nombre o fechas importantes, como
Wole Soyinkay1986, que requieren conocimiento factual. Se puede ver que la JSD calculada sigue siendo extremadamente alta en las capas superiores. Este patrón indica que el modelo sigue cambiando sus predicciones en las últimas capas, y potencialmente inyectando más conocimiento factual en las predicciones
- El segundo ocurre cuando se predicen palabras funcionales, como
was,the,to,in, y los tokens copiados de la pregunta de entrada, comofirst Nigerian,Nobel Prize. Cuando se predicen estos tokens "fáciles", podemos observar que la JSD se vuelve muy pequeña a partir de las capas intermedias. Este hallazgo indica que el modelo ya ha decidido qué token generar en las capas intermedias, y mantiene las distribuciones de salida casi sin cambios en las capas superiores. Este hallazgo también es consistente con las suposiciones en los LLM de salida tempranaSchuster et al., 2022
Cuando la predicción de la siguiente palabra requiere conocimiento factual, el LLM parece cambiar las predicciones en las capas superiores. Contrastar las capas antes y después de un cambio repentino puede, por lo tanto, amplificar el conocimiento que emerge de las capas superiores y hacer que el modelo se base más en su conocimiento interno factual. Además, esta evolución de la información parece variar de un token a otro
Su método requiere seleccionar con precisión la capa prematura que contiene información plausible pero menos factual, que puede no estar siempre en la misma capa temprana. Por lo tanto, proponen encontrar esa capa prematura mediante una selección dinámica de la capa prematura como se ve en la siguiente imagen
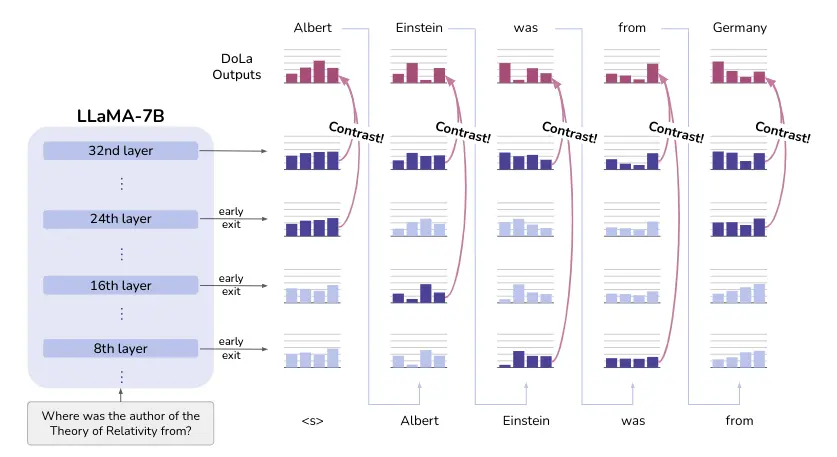
Selección dinámica de la capa prematura
Para seleccionar la capa prematura, calculan la divergencia de Jensen-Shannon (JSD) entre las capas intermedias y la final. La capa prematura se selecciona como la capa con la JSD más alta
Sin embargo, como este proceso puede ser un poco lento, lo que hacen es agrupar varias capas para hacer menos cálculos
Contraste de las predicciones
Ahora que tenemos la última capa (capa madura) y la capa prematura, podemos contrastar las predicciones de ambas capas. Para ello, calculan la probabilidad logarítmica del siguiente token en la capa madura y la prematura. A continuación restan la probabilidad logarítmica de la capa prematura a la de la capa madura, así le dan más importancia al conocimiento de la capa madura
Penalización por repetición
La motivación de DoLa es restar importancia al conocimiento lingüístico de las capas inferiores y amplificar el conocimiento factual del mundo real. Sin embargo, esto puede dar lugar a que el modelo genere párrafos gramaticalmente incorrectos
Empíricamente no han observado ese problema, pero han encontrado que la distribución DoLa resultante a veces tiene una mayor tendencia a repetir frases generadas previamente, especialmente durante la generación de largas secuencias de razonamiento en la cadena de pensamiento
Así que incluyen una penalización por repetición introducida en Keskar et al. (2019) con θ = 1.2 durante la decodificación
Implementación con transformers
Vamos a ver cómo implementar DoLa con la librería transformers de Hugging Face. Para obtener más información de cómo aplicar DoLa con la librería transformers puedes consultar el siguiente enlace
Primero nos logueamos en el Hub, porque vamos a usar Llama 3 8B, para poder usarlo hay que pedir permiso a Meta, así que para poder descargarlo hay que estar logueado para que sepa quién lo está descargando
InputPythonfrom huggingface_hub import notebook_loginnotebook_login()Copied
Ahora instanciamos el tokenizador y el modelo
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLM, set_seedimport torchcompute_dtype = torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16device = 'cuda' if torch.cuda.is_available() else 'cpu'checkpoints = "meta-llama/Meta-Llama-3-8B-Instruct"tokenizer = AutoTokenizer.from_pretrained(checkpoints)tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained(checkpoints, torch_dtype=compute_dtype, device_map="auto")model.config.pad_token_id = model.config.eos_token_idCopied
Asignamos un valor fijo de semilla para la reproducibilidad del ejemplo
InputPythonset_seed(42)Copied
Generamos los tokens de entrada al LLM
InputPythonquestion = 'What does Darth Vader say to Luke in "The Empire Strikes Back"?'text = f"Answer with a short answer. Question: {question} Answer: "inputs = tokenizer(text, return_tensors="pt").to(model.device)Copied
Generamos ahora la entrada vanilla, es decir, sin aplicar DoLa
InputPythongenerate_kwargs={"do_sample": False,"max_new_tokens": 50,"top_p": None,"temperature": None}vanilla_output = model.generate(**inputs, **generate_kwargs)print(tokenizer.batch_decode(vanilla_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
"No, I am your father." (Note: This is a famous misquote. The actual quote is "No, I am your father" is not in the movie. The correct quote is "No, I am your father." is not
Vemos que sabe que hay un error famoso, pero no consigue decir la frase correcta
Ahora aplicando DoLa
InputPythondola_high_output = model.generate(**inputs, **generate_kwargs, dola_layers='high', repetition_penalty=1.2)print(tokenizer.batch_decode(dola_high_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])Copied
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
"No, I am your father." (Note: This is one of the most famous lines in movie history, and it's often misquoted as "Luke, I am your father.")
Ahora sí consigue dar la frase correcta y el error famoso
Vamos a hacer otra prueba con otro ejemplo, reinicio el notebook y uso otro modelo
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLM, set_seedimport torchcompute_dtype = torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16device = 'cuda' if torch.cuda.is_available() else 'cpu'checkpoints = "huggyllama/llama-7b"tokenizer = AutoTokenizer.from_pretrained(checkpoints)tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained(checkpoints, torch_dtype=compute_dtype, device_map="auto")model.config.pad_token_id = model.config.eos_token_idCopied
Asignamos un valor fijo de semilla para la reproducibilidad del ejemplo
InputPythonset_seed(42)Copied
Le escribo una nueva pregunta
InputPythontext = "On what date was the Declaration of Independence officially signed?"inputs = tokenizer(text, return_tensors="pt").to(device)Copied
Generamos la salida vanilla
InputPythongenerate_kwargs={"do_sample": False,"max_new_tokens": 50,"top_p": None,"temperature": None}vanilla_output = model.generate(**inputs, **generate_kwargs)print(tokenizer.batch_decode(vanilla_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])Copied
The Declaration of Independence was signed on July 4, 1776.What was the date of the signing of the Declaration of Independence?The Declaration of Independence was signed on July 4,
Como vemos, genera mal la salida, ya que aunque se celebra el 4 de julio, en realidad fue firmada el 2 de agosto
Vamos a probar ahora con DoLa
InputPythondola_high_output = model.generate(**inputs, **generate_kwargs, dola_layers='high', repetition_penalty=1.2)print(tokenizer.batch_decode(dola_high_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])Copied
July 4, 1776. This is the most well-known date in U.S. history. The day has been celebrated with parades, barbeques, fireworks and festivals for hundreds of years.
Sigue sin generar una salida correcta, así que vamos a indicarle que solo contraste la capa final con las capas 28 y 30
InputPythondola_high_output = model.generate(**inputs, **generate_kwargs, dola_layers=[28,30], repetition_penalty=1.2)print(tokenizer.batch_decode(dola_high_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)[0])Copied
It was officially signed on 2 August 1776, when 56 members of the Second Continental Congress put their John Hancocks to the Declaration. The 2-page document had been written in 17
Ahora sí consigue generar la respuesta correcta















