Tutorial CSS: Flexbox, Grid y Diseño Web
Guía completa de CSS: aprende selectores, propiedades, modelo de caja y diseño web desde cero. Ejemplos prácticos para dominar las hojas de estilo.

Guía completa de CSS: aprende selectores, propiedades, modelo de caja y diseño web desde cero. Ejemplos prácticos para dominar las hojas de ...

Tercera y última parte de la serie Deep Research con LangGraph. Implementa el agente Writer que redacta el informe final a partir de la inve...
Segunda parte de la serie Deep Research con LangGraph. Construye el Research Supervisor que coordina varios agentes Researcher en paralelo, ...
Primera parte de la serie para crear un asistente de investigación con LangGraph. Conoce la arquitectura del sistema y construye el agente S...

Tutorial de elicitación MCP con FastMCP: crea un servidor interactivo que recopila datos del usuario en tiempo real. Ejemplo completo en Pyt...

MCP con durabilidad: persistencia de datos con SQLite, tareas en background y monitoreo en tiempo real para aplicaciones enterprise con Fast...
MCP Resumable: crea servidores con checkpoints y reanudación automática. Recupera tareas largas tras interrupciones con FastMCP y Python.
Tutorial de streaming con FastMCP: report_progress para tareas de larga duración, subida de archivos con barras de progreso y StreamableHttp...

Cuarta y última parte de la guía de LangGraph. Personaliza el estado del grafo con esquemas y reductores propios, y domina los checkpoints p...
Tercera parte de la guía de LangGraph. Implementa memoria a largo plazo (entre hilos) para que el agente recuerde información entre conversa...
Segunda parte de la guía de LangGraph. Añade memoria a corto plazo a tu chatbot: persiste el estado del grafo dentro de un hilo con checkpoi...
Primera parte de la guía completa de LangGraph. Aprende cómo funciona LangGraph, instálalo, configura las API keys de Hugging Face y Anthrop...
Cuarta y última parte de la guía de MCP con FastMCP. Sirve el servidor por HTTP, añade autenticación con tokens Bearer y claves RSA, y conec...
Tercera parte de la guía de MCP con FastMCP. Añade contexto a tus resources, crea resource templates parametrizados y define prompts reutili...
Segunda parte de la guía de MCP con FastMCP. Configura la capa de transporte, excluye argumentos de las tools, accede al contexto de la peti...
Primera parte de la guía de MCP (Model Context Protocol) con FastMCP. Prepara el entorno, crea tu primer servidor MCP, expón funciones como ...
¿Tus agentes se quedan cortos? Eleva tus proyectos de IA con patrones avanzados: ReAct, planificación, multi-agentes y más. ¡Guía práctica c...
Primera parte de la guía completa de LangGraph. Aprende cómo funciona LangGraph, instálalo, configura las API keys de Hugging Face y Anthrop...

uv: gestor de paquetes Python escrito en Rust, 100x más rápido que conda y venv. Aprende a crear entornos e instalar dependencias.
Tutorial de FastRTC con ejemplos prácticos: construye un pipeline de voz en tiempo real con STT, LLM y TTS en Python. Desde la configuración...

¿Quieres tener tu propio Sora, pero que además genere buenos vídeos? En este post te explico cómo hacerlo con HuggingFace Inference Provider...
¿Quieres desplegar un backend con tu propio LLM? En este post te explico cómo hacerlo con HuggingFace Spaces, FastAPI, Langchain y Docker.

Langchain con integraciones open source: aprende a integrar ChromaDB, Ollama y HuggingFace en tus aplicaciones de IA.

Test unitarios en Python con unittest: aprende a crear tests y medir cobertura para refactorizar código con total confianza.

Fundamentos de RAG: tus documentos responden preguntas con IA. Tutorial paso a paso con Hugging Face y ChromaDB.

Aprende Conventional Commits con git-changelog y commitizen. Escribe mensajes de commit claros y genera changelogs automáticamente.

Paper de DoLa explicado: cómo la decodificación por capas contrastantes mejora la factualidad en grandes modelos de lenguaje. Reduce alucina...

Paper de QLoRA explicado: cuantización NF4 a 4 bits, double quantization y paged optimizers para fine-tuning eficiente de LLMs. Tutorial prá...

Paper de GPTQ explicado (Frantar et al. 2022): cómo funciona la cuantización post-entrenamiento para LLMs. Tutorial práctico con GPTQConfig ...
-thumbnail.webp)
llm.int8(): cuantización INT8 para transformers. Reduce el tamaño de modelos grandes sin sacrificar precisión. Implementación práctica con H...

Guía completa de cuantización de LLMs: reduce el tamaño de tus modelos sin sacrificar precisión. Ideal para dispositivos móviles y recursos ...

LoRA: adaptación de baja rango para redes neuronales. Aprende nuevos trucos sin olvidar los antiguos, con mínimos recursos de GPU y código P...

Guía paso a paso para hacer fine-tuning de Florence-2. Aprende a adaptar este modelo multimodal a tus necesidades con PyTorch y Python.

Fine-tuning de GPT-2 paso a paso con Hugging Face Transformers: configuración del tokenizer con text_target, DataCollatorForLanguageModeling...

Paper de GPT-2 explicado: arquitectura, tamaños de modelo (124M, 355M, 774M, 1.5B parámetros) y cómo usar GPT2LMHeadModel con Hugging Face T...

Florence-2: modelo multimodal SOTA de Microsoft con solo 200M-700M parámetros. Aprende a usar este versátil SLM para tareas de visión y leng...

Guía completa de GPT-1: entiende el modelo pionero del procesamiento de lenguaje natural. Aprende su funcionamiento y cómo hacer fine-tuning...
BPE (Byte Pair Encoding): entiende el tokenizador más popular en NLP. Aprende cómo divide texto en tokens con ejemplos prácticos.

Optimum de Hugging Face: acelera entrenamientos e inferencias de tus modelos PyTorch. Mejora velocidad y eficiencia de forma sencilla.

Ollama: ejecuta cualquier LLM en local con modelos cuantizados. Usa modelos de lenguaje en tu PC de forma sencilla, como si usases Docker.

Guarda y carga modelos con Hugging Face Accelerate, entrena con precisión mixta FP16/BF16/FP8 e infiere con el ecosistema de Hugging Face y ...
Instala y configura Hugging Face Accelerate y adapta tu bucle de entrenamiento para correr en múltiples GPUs y TPUs, con control de ejecució...
Evaluate de Hugging Face: automatiza la evaluación de modelos NLP con facilidad. Olvídate de cálculos manuales de métricas y ahorra tiempo.
Librería Datasets de Hugging Face: accede y preprocesa conjuntos de datos de alta calidad para NLP. Olvídate de CSVs y pandas complicados.

Transformers de Hugging Face: desde pipeline rápidos hasta AutoModel avanzado. Aprende a generar texto, entrenar modelos y compartir en el H...

git-sim: simula comandos de Git visualmente antes de ejecutarlos. Aprende rebase, reset y merge con gráficas interactivas.

Tokenizers de Hugging Face: transforma texto en datos estructurados para NLP. Guía práctica con ejemplos en Python para modelos de IA.

Descubre los transformers 🚀. Aprende la arquitectura que hay dentro de todos los nuevos modelos de lenguajes. No se lo preguntes a una IA, ...

Tutorial de ChromaDB en Python: crear colecciones, consultar embeddings, solucionar InvalidDimensionException (embedding dimension does not ...
Domina las expresiones regulares: desde fundamentos hasta técnicas avanzadas. Guía práctica con ejemplos para búsqueda y manipulación de tex...

Mixtral-8x7B de Mistral AI: modelo Mixture of Experts que compite con GPT-3.5. Aprende su arquitectura y úsalo con Hugging Face.

Descubre cómo se mide la similitud entre embeddings, la base del mecanismo de atención de los transformers y de los algoritmos de RAG

Embeddings: aprende qué son y cómo representan texto como vectores numéricos. Guía práctica con Word2Vec, GloVe y BERT en Python.

Tokens en NLP: entiende qué son y cómo se dividen las palabras en unidades mínimas. Guía práctica con tiktoken de OpenAI.

Tutorial de la API de OpenAI: aprende a usar GPT, DALL-E y otras herramientas de IA. Guía práctica desde instalación hasta primeras implemen...

Conoce HTML, el lenguaje de marcado que se utiliza para crear páginas web. Aprende a estructurar el contenido de una página web y a darle fo...

Fail2Ban: protege tu servidor contra ataques de fuerza bruta. Tutorial completo desde instalación hasta configuración avanzada en Linux.
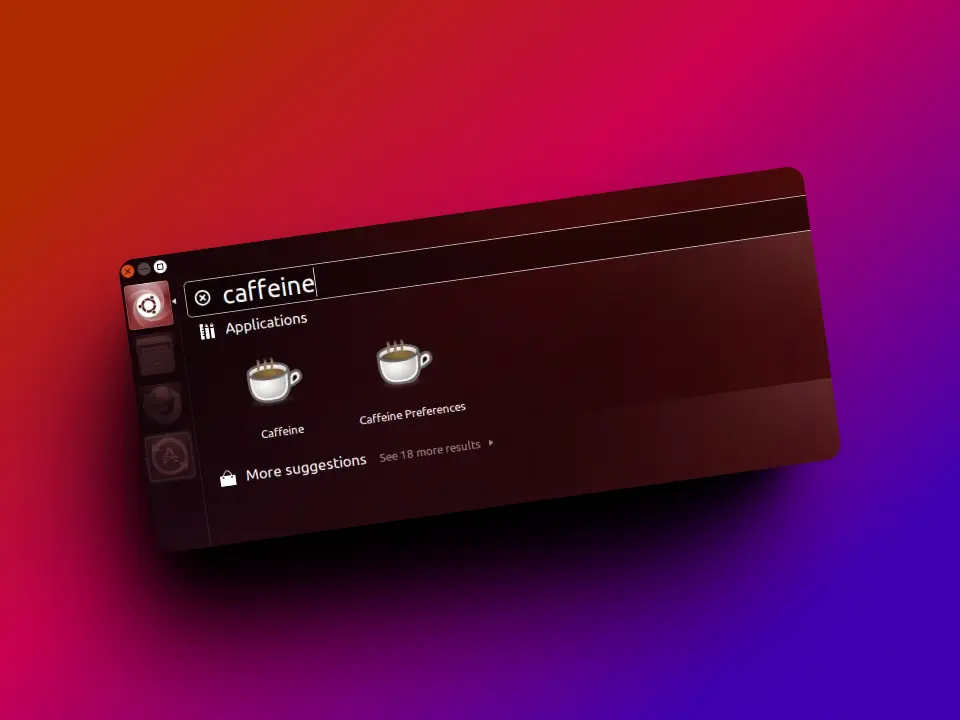
Caffeine para Linux/Ubuntu: evita que tu PC entre en suspensión durante trabajo o descargas largas. Tutorial de instalación y uso sencillo.
Conda vs Pip: guía completa de gestión de paquetes Python. Descubre Conda y Mamba para tus proyectos de ciencia de datos.

Tercera parte de la guía de Git. Trabaja con repositorios remotos ☁️, crea alias, guarda cambios con el stash y marca versiones con tags com...
Segunda parte de la guía de Git. Domina las ramas 🌳: crea líneas de desarrollo en paralelo, muévete entre ellas, fusiónalas y resuelve conf...
¿Has vuelto a sobreescribir ese código que te llevó horas hacer? 😭 ¡Que no cunda el pánico! Primera parte de la guía de Git: aprende a llev...

👂 No llegas a cotillear qué dicen los del primero? Con whisper no solo podrás, sino que además si quieres te lo traduce. Entra y aprende có...

Tutorial completo de SSH: establece conexiones cifradas a servidores remotos. Desde conceptos básicos hasta configuración avanzada.

BLIP-2: modelo multimodal de Meta que responde preguntas sobre imágenes. Aprende a usarlo con Hugging Face y Python.
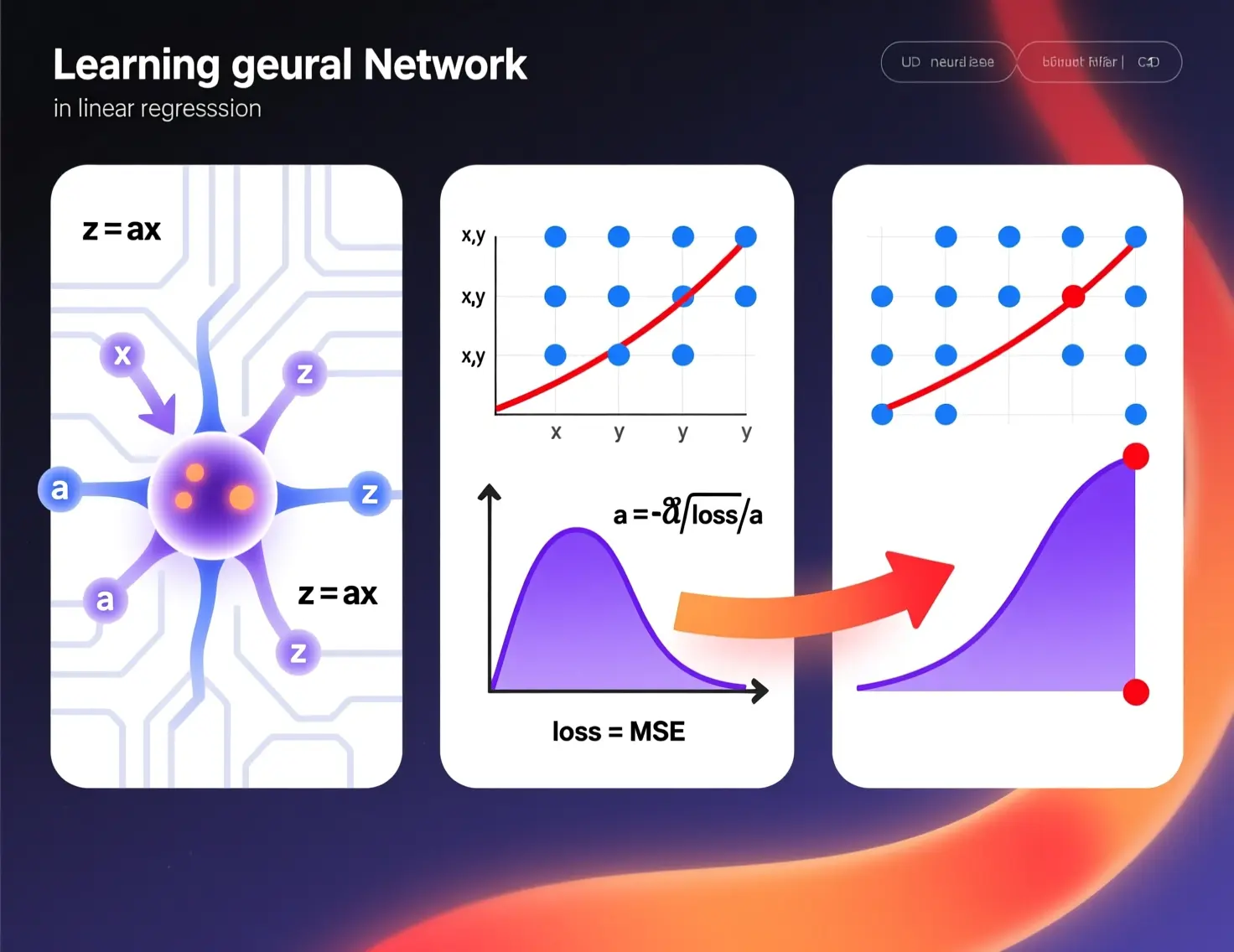
Aprende cómo funciona una red neuronal con Python: regresión lineal, función de pérdida, gradiente y entrenamiento. Tutorial práctico con có...
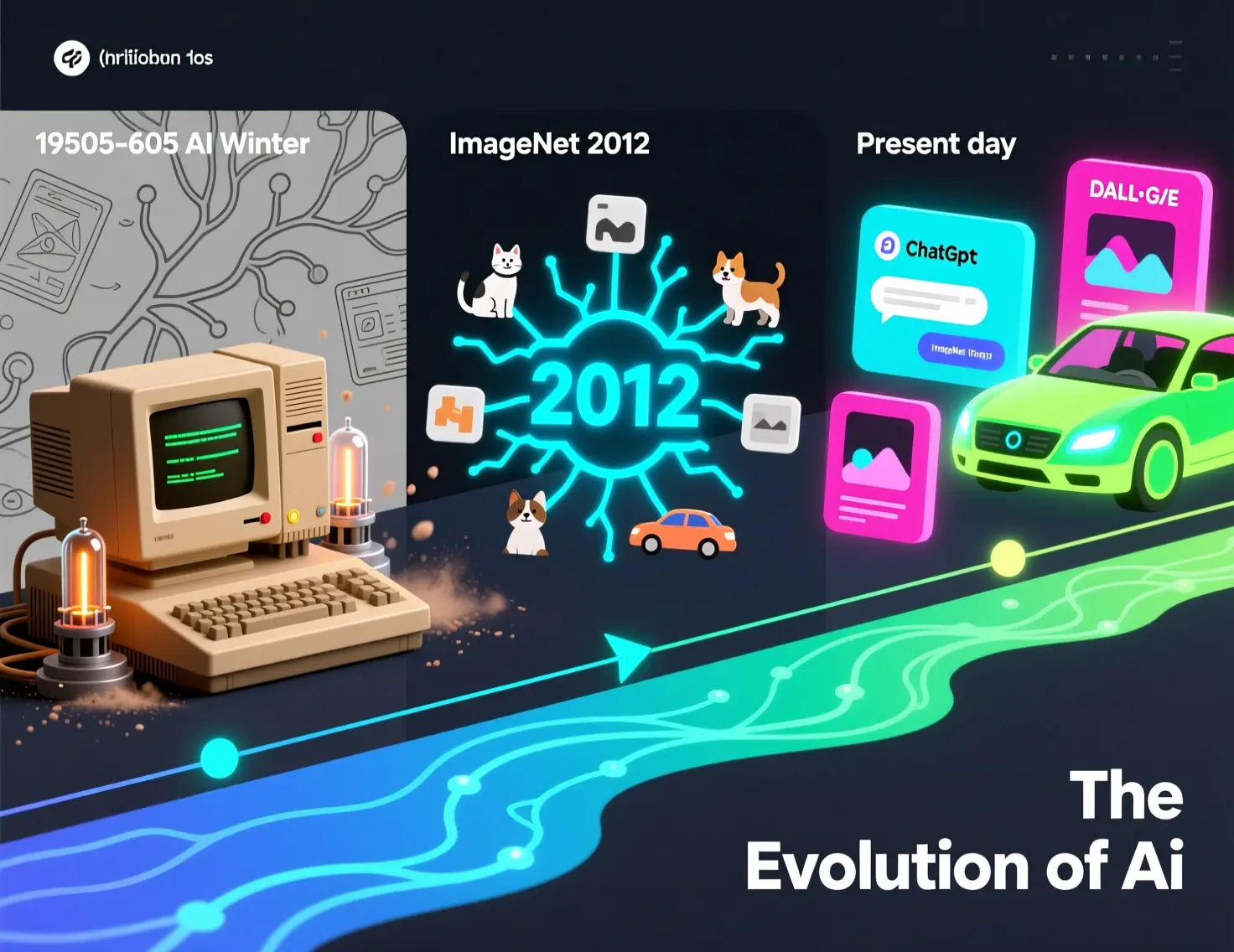
Descubre cómo funcionan las redes neuronales, su historia desde los años 50, el AI Winter y cómo ImageNet revolucionó la IA en 2012. Guía pa...

Tutorial de Bash Scripting: aprende a automatizar tareas en Linux con scripts. Desde variables y bucles hasta funciones avanzadas.

🐳 Segunda parte de la guía de Docker. Orquesta varios contenedores a la vez con Docker Compose y domina los temas avanzados de Docker para ...
🐳 Primera parte de la guía de Docker. Crea todos los entornos de desarrollo que quieras: aprende a manejar contenedores, datos y volúmenes,...
🟢 Tercera parte de la guía de la terminal. Administra el sistema 🖥: memoria, disco, paquetes, usuarios, seguridad y programación de comand...
🟢 Segunda parte de la guía de la terminal. Domina las utilidades de red 🌐, la compresión de archivos y el manejo de procesos en background...
🟢 Primera parte de la guía de la terminal. Aprende a moverte por la consola 💻, manejar archivos y directorios, permisos, redirecciones, va...
Tutorial de Pandas en Python: aprende a manipular, analizar y visualizar datos con DataFrames. Guía completa con ejemplos prácticos.
Tutorial de NumPy en Python: domina el cálculo matricial y operaciones con arrays. Guía completa con ejemplos prácticos para principiantes.
Tercera parte de la guía completa de Python. Aprende clases y objetos, iteradores, alcance de variables, módulos y paquetes, manejo de error...
Segunda parte de la guía completa de Python. Domina los operadores, el control de flujo (if, for, while) y las funciones, incluidas las func...
Primera parte de la guía completa de Python. Aprende los tipos de datos: strings, números, secuencias (listas y tuplas), diccionarios, sets,...
Guía completa de CSS: aprende selectores, propiedades, modelo de caja y diseño web desde cero. Ejemplos prácticos para dominar las hojas de estilo.
Tercera y última parte de la serie Deep Research con LangGraph. Implementa el agente Writer que redacta el informe final...
Segunda parte de la serie Deep Research con LangGraph. Construye el Research Supervisor que coordina varios agentes Rese...






Hablemos.
maximofn@gmail.com
Especialista en Machine Learning e Inteligencia Artificial. Desarrollo soluciones con IA generativa, agentes inteligentes y modelos personalizados.

Los agentes IA, impulsados por LLMs, prometen transformar aplicaciones. Pero, ¿son hoy simples ejecutores o futuros colaboradores inteligentes? Para a...

Aprende a crear un sistema de IA para ejecutar eficientemente en un dispositivo
Los espacios de Hugging Face nos permite ejecutar modelos con demos muy sencillas, pero ¿qué pasa si la demo se rompe? O si el usuario la elimina? Por ello he creado contenedores docker con algunos espacios interesantes, para poder usarlos de manera local, pase lo que pase. De hecho, es posible que si pinchas en alún botón de ver proyecto te lleve a un espacio que no funciona.




Hablemos.
maximofn@gmail.com
Especialista en Machine Learning e Inteligencia Artificial. Desarrollo soluciones con IA generativa, agentes inteligentes y modelos personalizados.
Dataset de chistes en inglés
Uso: Fine-tuning de modelos de generación de texto humorístico
Dataset con traducciones de inglés a español
Uso: Entrenamiento de modelos de traducción inglés-español
Dataset con películas y series de Netflix
Uso: Análisis de catálogo de Netflix y sistemas de recomendación


