-thumbnail.webp)
Disclaimer: This post has been translated to English using a machine translation model. Please, let me know if you find any mistakes.
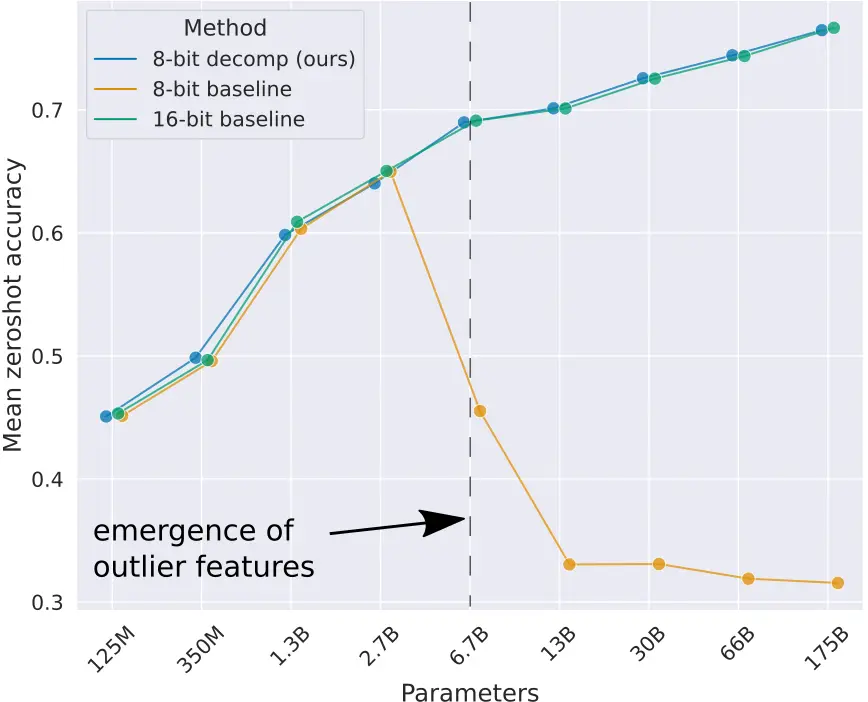
In the post LLMs quantization we explain the importance of LLMs quantization to save memory. Additionally, we explain that there is a type of quantization called zero-point quantization which involves transforming the values of the parameters linearly, but this has the problem of language model degradation once they exceed 2.7B parameters.
Vector Quantization
Since the quantization of all parameters in models introduces errors in large language models, what is proposed in the paper llm.int8() is to perform vector quantization, which means separating weight matrices into vectors so that some of these vectors can be quantized to 8 bits, while others cannot. Therefore, those that can be quantized to 8 bits are quantized and matrix multiplications are performed in INT8 format, while the vectors that cannot be quantized remain in FP16 format and multiplications are performed in FP16 format.
Let's see it with an example
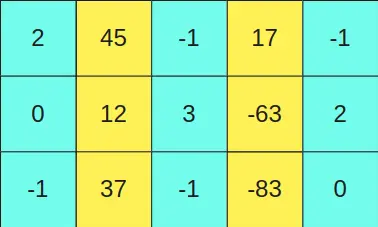
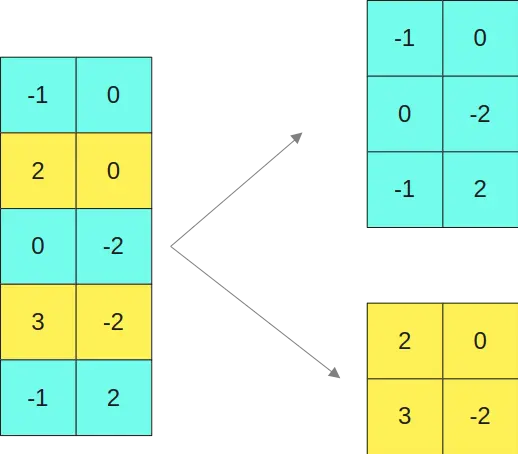
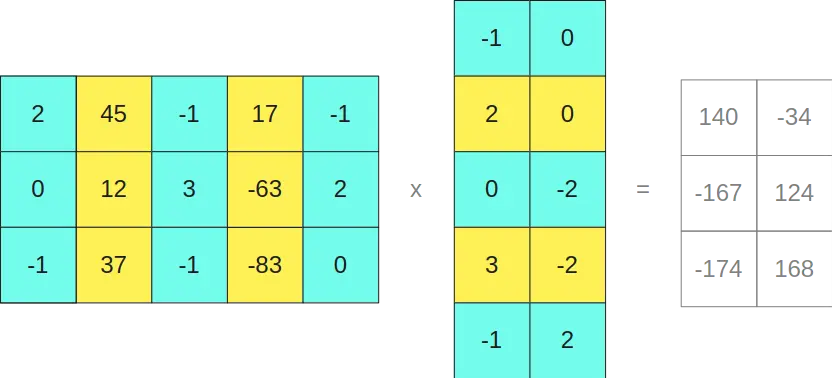
Suppose we have the matrix
and we want to multiply it by the matrix
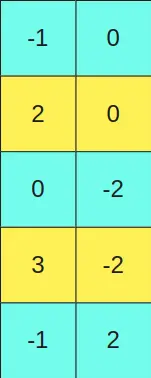
We set a threshold value and all columns of the first matrix that have a value greater than this threshold are kept in FP16 format. The corresponding rows in the second matrix, equivalent to the rows of the first matrix, are also kept in FP16 format.
To make it clearer, since the second and fourth columns of the first matrix (yellow columns) have values greater than a certain threshold, then the second and fourth rows of the second matrix (yellow rows) are kept in FP16 format.
If there are threshold values in the second matrix, the same would be done, for example, if a row in the second matrix had a value greater than a threshold it would be kept in FP16 format, and that column in the first matrix would be kept in FP16 format.
The rest of the rows and columns that are not kept in FP16 format are quantized to 8 bits, and the multiplications are performed in INT8 format.
So we separate the first matrix into the two submatrices
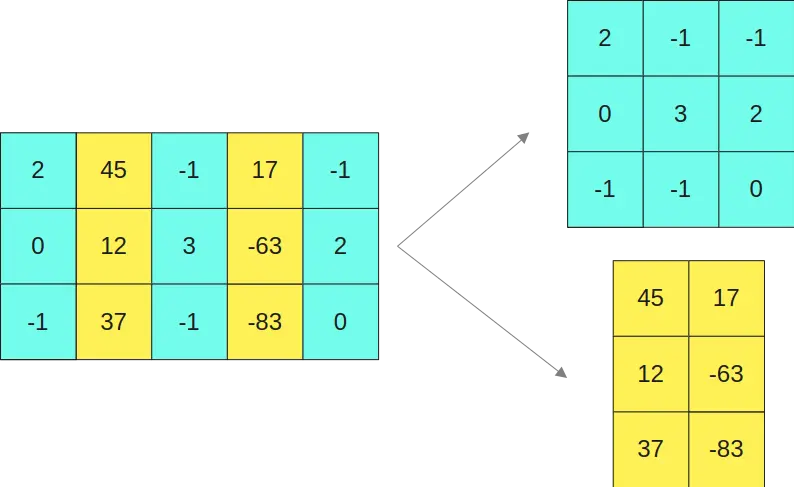
And the second matrix in the two matrices
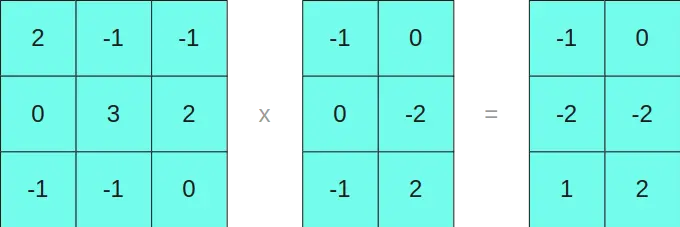
We multiply the matrices in INT8 on one side
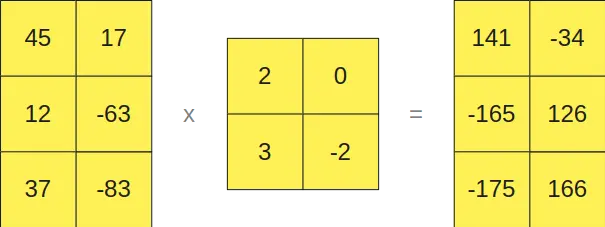
And those that are in FP16 format on the other hand
As can be seen, multiplying the matrices in INT8 format gives us a result of a 3x2 matrix, and multiplying the matrices in FP16 format also gives us another 3x2 matrix, so if we add them together
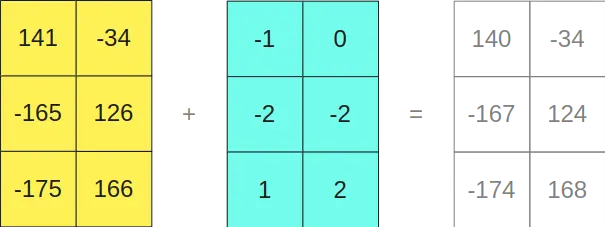
Interestingly, it gives us the same result as if we had multiplied the original matrices
To understand why this happens, if we develop the cross product of the two original matrices
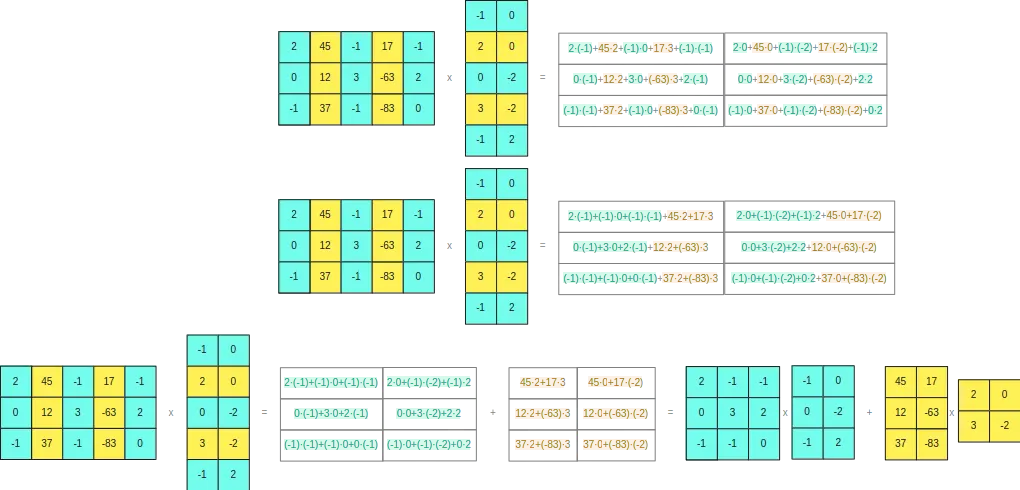
We see that the separation we have made does not cause any problems
Therefore, we can conclude that we can separate rows and columns of matrices to perform matrix multiplications. This separation will occur when some element of the row or column is greater than a threshold value, so that rows or columns that do not have a value greater than this threshold will be encoded in INT8 occupying only one byte, and rows or columns that have an element greater than this threshold will be converted to FP16 occupying 2 bytes. This way, we won't have rounding issues, as the calculations we perform in INT8 will be with values that ensure the multiplications do not exceed the range of 8 bits.
Threshold value α
As we have said, we are going to split into rows and columns that have some element greater than a threshold value, but what threshold value should we choose? The authors of the paper conducted experiments with several values and determined that this threshold value should be α=6. Above this value, they started to observe degradations in the language models.
Use of llm.int8()
Let's see how to quantize a model with llm.int8() using the transformers library. For this, you need to have bitsandbytes installed.
pip install bitsandbytesWe load a 1B parameter model twice, once in the usual way and the second time quantizing it with llm.int8()
InputPythonfrom transformers import AutoModelForCausalLM, AutoTokenizerimport torchdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")checkpoint = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"tokenizer = AutoTokenizer.from_pretrained(checkpoint)model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device)model_8bit = AutoModelForCausalLM.from_pretrained(checkpoint, device_map="auto", load_in_8bit=True)Copied
The `load_in_4bit` and `load_in_8bit` arguments are deprecated and will be removed in the future versions. Please, pass a `BitsAndBytesConfig` object in `quantization_config` argument instead.
We see how much memory each of the models occupies
InputPythonmodel.get_memory_footprint()/(1024**3), model_8bit.get_memory_footprint()/(1024**3)Copied
(4.098002195358276, 1.1466586589813232)
As can be seen, the quantized model takes up much less memory
Let's now do a text generation test with the two models
InputPythoninput_tokens = tokenizer("Hello my name is Maximo and I am a Machine Learning Engineer", return_tensors="pt").to(device)input_tokens.input_idsCopied
tensor([[ 1, 15043, 590, 1024, 338, 5918, 4200, 322, 306, 626,263, 6189, 29257, 10863, 261]], device='cuda:0')
We see the output with the normal model
InputPythonimport timet0 = time.time()max_new_tokens = 50outputs = model.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(time.time() - t0)Copied
Hello my name is Maximo and I am a Machine Learning Engineer. I am currently working at [Company Name] as a Machine Learning Engineer. I have a Bachelor's degree in Computer Science from [University Name] and a Master's degree in Computer Science from [University Name]. I1.7616662979125977
And now with the quantized model
InputPythont0 = time.time()max_new_tokens = 50outputs = model_8bit.generate(input_ids=input_tokens.input_ids,attention_mask=input_tokens.attention_mask,max_length=input_tokens.input_ids.shape[1] + max_new_tokens,)print(tokenizer.decode(outputs[0], skip_special_tokens=True))print(time.time() - t0)Copied
Hello my name is Maximo and I am a Machine Learning Engineer. I am currently working at [Company Name] as a Machine Learning Engineer. I have a Bachelor's degree in Computer Science from [University Name] and a Master's degree in Computer Science from [University Name]. I9.100712776184082
We see two things: on the one hand, that the output we get is the same text; so with a much smaller model we can obtain the same output. However, the quantized model takes much longer to run, so if it needs to be used in real time, it would not be advisable.
This is contradictory, because we might think that a smaller model would run faster, but we have to consider that in reality both models, the normal and the quantized one, perform the same operations; it's just that one performs all operations in FP32 while the other does them in INT8 and FP16. However, the quantized model has to find rows and columns with values greater than the threshold value, separate them, perform the operations in INT8 and FP16, and then recombine the results, which is why the quantized model takes longer to run.















