
Disclaimer: This post has been translated to English using a machine translation model. Please, let me know if you find any mistakes.
Now that LLMs are on the rise, we keep hearing about the number of tokens each model supports, but what are tokens? They are the smallest units of representation of words.
To explain what tokens are, let's first look at a practical example using the OpenAI tokenizer, called tiktoken.
So, first we install the package:
pip install tiktokenOnce installed, we create a tokenizer using the cl100k_base model, which in the example notebook How to count tokens with tiktoken explains is used by the models gpt-4, gpt-3.5-turbo and text-embedding-ada-002
import tiktokenencoder = tiktoken.get_encoding("cl100k_base")Copied
Now we create an example word to tokenize it
example_word = "breakdown"Copied
And we tokenize it
tokens = encoder.encode(example_word)tokensCopied
[9137, 2996]
The word has been split into 2 tokens, the 9137 and the 2996. Let's see which words they correspond to.
word1 = encoder.decode([tokens[0]])word2 = encoder.decode([tokens[1]])word1, word2Copied
('break', 'down')
The OpenAI tokenizer has split the word breakdown into the words break and down. That is, it has divided the word into 2 simpler ones.
This is important, as when it is said that an LLM supports x tokens, it does not mean that it supports x words, but rather that it supports x minimal units of word representation.
If you have a text and want to see the number of tokens it has for the OpenAI tokenizer, you can check it on the Tokenizer page, which displays each token in a different color.
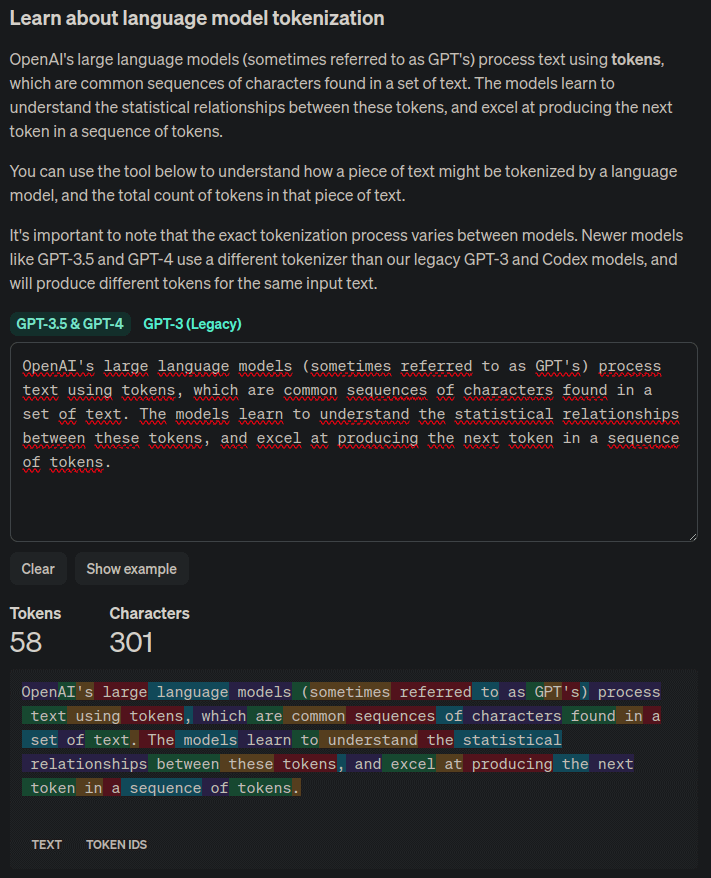
We have seen the tokenizer of OpenAI, but each LLM may use a different one.
As we have said, the tokens are the minimal units of representation of words, so let's see how many distinct tokens tiktoken has.
n_vocab = encoder.n_vocabprint(f"Vocab size: {n_vocab}")Copied
Vocab size: 100277
Let's see how it tokenizes another type of words
def encode_decode(word):tokens = encoder.encode(word)decode_tokens = []for token in tokens:decode_tokens.append(encoder.decode([token]))return tokens, decode_tokensCopied
word = "dog"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "tomorrow..."tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "artificial intelligence"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "Python"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "12/25/2023"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "😊"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")Copied
Word: dog ==> tokens: [18964], decode_tokens: ['dog']Word: tomorrow... ==> tokens: [38501, 7924, 1131], decode_tokens: ['tom', 'orrow', '...']Word: artificial intelligence ==> tokens: [472, 16895, 11478], decode_tokens: ['art', 'ificial', ' intelligence']Word: Python ==> tokens: [31380], decode_tokens: ['Python']Word: 12/25/2023 ==> tokens: [717, 14, 914, 14, 2366, 18], decode_tokens: ['12', '/', '25', '/', '202', '3']Word: 😊 ==> tokens: [76460, 232], decode_tokens: ['�', '�']
Finally, we will see it with words in another language
word = "perro"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "perra"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "mañana..."tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "inteligencia artificial"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "Python"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "12/25/2023"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "😊"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")Copied
Word: perro ==> tokens: [716, 299], decode_tokens: ['per', 'ro']Word: perra ==> tokens: [79, 14210], decode_tokens: ['p', 'erra']Word: mañana... ==> tokens: [1764, 88184, 1131], decode_tokens: ['ma', 'ñana', '...']Word: inteligencia artificial ==> tokens: [396, 39567, 8968, 21075], decode_tokens: ['int', 'elig', 'encia', ' artificial']Word: Python ==> tokens: [31380], decode_tokens: ['Python']Word: 12/25/2023 ==> tokens: [717, 14, 914, 14, 2366, 18], decode_tokens: ['12', '/', '25', '/', '202', '3']Word: 😊 ==> tokens: [76460, 232], decode_tokens: ['�', '�']
We can see that for similar words, Spanish generates more tokens than English, so for the same text, with a similar number of words, the number of tokens will be greater in Spanish than in English.

















