
Paper
Language Models are Unsupervised Multitask Learners es el paper de GPT-2. Esta es la segunda versión del modelo GPT-1 que ya vimos
Arquitectura
Antes de hablar de la arquitectura de GPT-2 recordemos cómo era la arquitectura de GPT-1
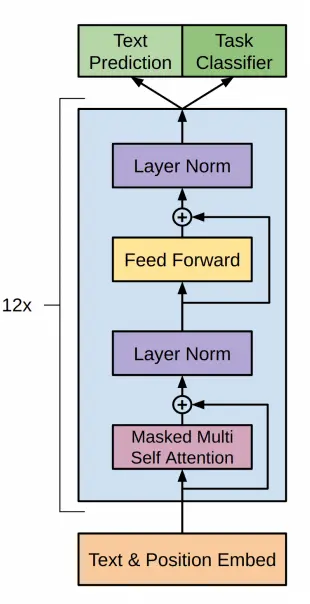
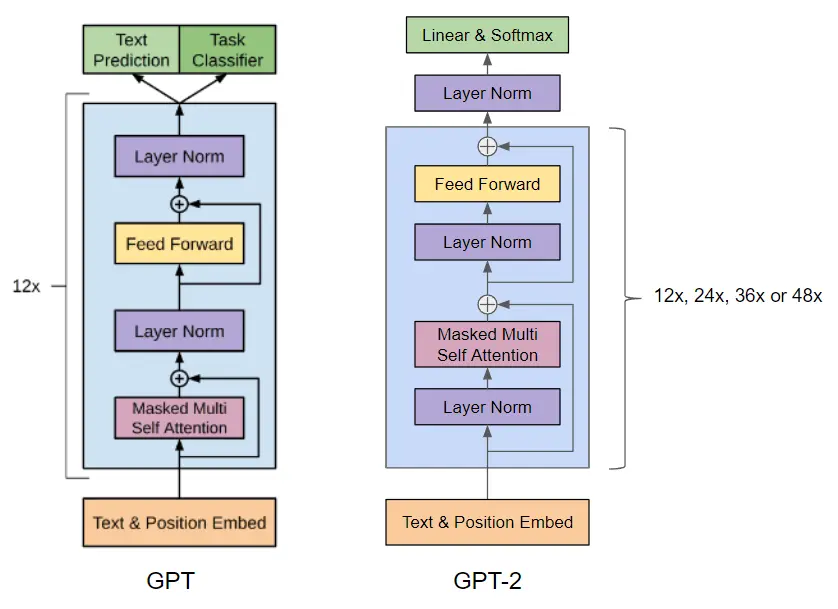
En GPT-2 se utiliza una arquitectura basada en transformers, igual que GPT-1, con los siguientes tamaños
| Parameters | Layers | d_model |
|---|---|---|
| 117M | 12 | 768 |
| 345M | 24 | 1024 |
| 762M | 36 | 1280 |
| 1542M | 48 | 1600 |
El modelo más pequeño es equivalente al GPT original, y el segundo más pequeño es equivalente al modelo más grande de BERT. El modelo más grande tiene más de un orden de magnitud más parámetros que GPT
Además, se realizaron las siguientes modificaciones en la arquitectura
- Se añade una capa de normalización antes del bloque de atención. Esto puede ayudar a estabilizar el entrenamiento del modelo y a mejorar su capacidad para aprender representaciones más profundas. Al normalizar las entradas de cada bloque, se reduce la variabilidad en las salidas y se facilita el entrenamiento del modelo
- Se ha agregado una normalización adicional después del bloque de auto-atención final. Esto puede ayudar a reducir la variabilidad en las salidas del modelo y a mejorar su estabilidad.
- En la mayoría de los modelos, los pesos de las capas se inicializan de manera aleatoria, siguiendo una distribución normal o uniforme. Sin embargo, en el caso de GPT-2, los autores decidieron utilizar una inicialización modificada que tiene en cuenta la profundidad del modelo.La idea detrás de esta inicialización modificada es que, a medida que el modelo se hace más profundo, la señal que fluye a través de las capas residuales se va debilitando. Esto se debe a que cada capa residual se suma a la entrada original, lo que puede hacer que la señal se vaya atenuando con la profundidad del modelo. Para contrarrestar este efecto decidieron escalar los pesos de las capas residuales en la inicialización por un factor de 1/√N, donde N es el número de capas residuales. Esto significa que, a medida que el modelo se hace más profundo, los pesos de las capas residuales se vuelven más pequeños. Este truco de inicialización puede ayudar a estabilizar el entrenamiento del modelo y a mejorar su capacidad para aprender representaciones más profundas. Al escalar los pesos de las capas residuales, se reduce la variabilidad en las salidas de cada capa y se facilita el flujo de la señal a través del modelo. En resumen, la inicialización modificada en GPT-2 se utiliza para contrarrestar el efecto de atenuación de la señal en las capas residuales, lo que ayuda a estabilizar el entrenamiento del modelo y a mejorar su capacidad para aprender representaciones más profundas.
- El tamaño del vocabulario se ha expandido a 50,257. Esto significa que el modelo puede aprender a representar un conjunto más amplio de palabras y tokens.
- El tamaño del contexto se ha aumentado de 512 a 1024 tokens. Esto permite que el modelo tenga en cuenta un contexto más amplio al generar texto.
Resumen del paper
Las ideas más interesantes del paper son:
- Para el preentrenamiento del modelo pensaron usar una fuente de texto diverso y casi ilimitado, web scraping como Common Crawl. Sin embargo encontraron que había texto casi de muy mala calidad. Así que usaron el dataset WebText, que provenía también de web scraping pero con un filtro de calidad, como la cantidad de enlaces de salida de redit, etc. Además quitaron el texto proveniente de la wikipedia, ya que podía estar repetido en otras páginas.
- Utilizaron un tokenizador BPE que ya explicamos en un post anterior
Generación de texto
Vamos a ver cómo generar texto con un GPT-2 preentrenado
Para generar texto vamos a utilizar el modelo desde el repositorio de GPT-2 de Hugging Face.
Generación de texto con pipeline
Con este modelo ya podemos usar el pipeline de transformers
InputPythonfrom transformers import pipelinecheckpoints = "openai-community/gpt2-xl"generator = pipeline('text-generation', model=checkpoints)output = generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)for i, o in enumerate(output):print(f"Output {i+1}: {o['generated_text']}")Copied
Truncation was not explicitly activated but `max_length` is provided a specific value, please use `truncation=True` to explicitly truncate examples to max length. Defaulting to 'longest_first' truncation strategy. If you encode pairs of sequences (GLUE-style) with the tokenizer you can select this strategy more precisely by providing a specific strategy to `truncation`.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Output 1: Hello, I'm a language model, and I want to change the way you readA little in today's post I want to talk aboutOutput 2: Hello, I'm a language model, with two roles: the language model and the lexicographer-semantics expert. The language models are goingOutput 3: Hello, I'm a language model, and this is your brain. Here is your brain, and all this data that's stored in there, thatOutput 4: Hello, I'm a language model, and I like to talk... I want to help you talk to your customersAre you using language modelOutput 5: Hello, I'm a language model, I'm gonna tell you about what type of language you're using. We all know a language like this,
Generación de texto con automodel
Pero si queremos utilizar Automodel, podemos hacer lo siguiente
InputPythonimport torchfrom transformers import GPT2Tokenizer, AutoTokenizercheckpoints = "openai-community/gpt2-xl"tokenizer = GPT2Tokenizer.from_pretrained(checkpoints)auto_tokenizer = AutoTokenizer.from_pretrained(checkpoints)Copied
Al igual que con GPT-1 podemos importar GPT2Tokenizer y AutoTokenizer. Esto es porque en la model card de GPT-2 se indica que se use GPT2Tokenizer, pero en el post de la librería transformers explicamos que se debe usar AutoTokenizer para cargar el tokenizador. Así que vamos a probar los dos
InputPythoncheckpoints = "openai-community/gpt2-xl"tokenizer = GPT2Tokenizer.from_pretrained(checkpoints)auto_tokenizer = AutoTokenizer.from_pretrained(checkpoints)input_tokens = tokenizer("Hello, I'm a language model,", return_tensors="pt")input_auto_tokens = auto_tokenizer("Hello, I'm a language model,", return_tensors="pt")print(f"input tokens: {input_tokens}")print(f"input auto tokens: {input_auto_tokens}")Copied
input tokens:{'input_ids': tensor([[15496, 11, 314, 1101, 257, 3303, 2746, 11]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1]])}input auto tokens:{'input_ids': tensor([[15496, 11, 314, 1101, 257, 3303, 2746, 11]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1]])}
Como se puede ver con los dos tokenizadores se obtienen los mismos tokens. Así que para que el código sea más general, de manera que si se cambian los checkpoints, no haya que cambiar el código, vamos a utilizar AutoTokenizer
Creamos entonces el device, el tokenizador y el modelo
InputPythonimport torchfrom transformers import AutoTokenizer, GPT2LMHeadModeldevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")checkpoints = "openai-community/gpt2-xl"tokenizer = AutoTokenizer.from_pretrained(checkpoints)model = GPT2LMHeadModel.from_pretrained(checkpoints).to(device)Copied
Como hemos instanciado el modelo, vamos a ver cuántos parámetros tiene
InputPythonparams = sum(p.numel() for p in model.parameters())print(f"Number of parameters: {round(params/1e6)}M")Copied
Number of parameters: 1558M
Como vemos hemos cargado el modelo de 1.5B de parámetros, pero si quisiésemos cargar los otros modelos tendríamos que hacer
InputPythoncheckpoints_small = "openai-community/gpt2"model_small = GPT2LMHeadModel.from_pretrained(checkpoints_small)print(f"Number of parameters of small model: {round(sum(p.numel() for p in model_small.parameters())/1e6)}M")checkpoints_medium = "openai-community/gpt2-medium"model_medium = GPT2LMHeadModel.from_pretrained(checkpoints_medium)print(f"Number of parameters of medium model: {round(sum(p.numel() for p in model_medium.parameters())/1e6)}M")checkpoints_large = "openai-community/gpt2-large"model_large = GPT2LMHeadModel.from_pretrained(checkpoints_large)print(f"Number of parameters of large model: {round(sum(p.numel() for p in model_large.parameters())/1e6)}M")checkpoints_xl = "openai-community/gpt2-xl"model_xl = GPT2LMHeadModel.from_pretrained(checkpoints_xl)print(f"Number of parameters of xl model: {round(sum(p.numel() for p in model_xl.parameters())/1e6)}M")Copied
Number of parameters of small model: 124MNumber of parameters of medium model: 355MNumber of parameters of large model: 774MNumber of parameters of xl model: 1558M
Creamos los tokens de entrada al modelo
InputPythoninput_sentence = "Hello, I'm a language model,"input_tokens = tokenizer(input_sentence, return_tensors="pt").to(device)input_tokensCopied
{'input_ids': tensor([[15496, 11, 314, 1101, 257, 3303, 2746, 11]],device='cuda:0'), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1]], device='cuda:0')}
Se los pasamos al modelo para generar los tokens de salida
InputPythonoutput_tokens = model.generate(**input_tokens)print(f"output tokens: {output_tokens}")Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation./home/wallabot/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/generation/utils.py:1178: UserWarning: Using the model-agnostic default `max_length` (=20) to control the generation length. We recommend setting `max_new_tokens` to control the maximum length of the generation.warnings.warn(
output tokens:tensor([[15496, 11, 314, 1101, 257, 3303, 2746, 11, 290, 314,1101, 1016, 284, 1037, 345, 351, 534, 1917, 13, 198]],device='cuda:0')
Decodificamos los tokens para obtener la sentencia de salida
InputPythondecoded_output = tokenizer.decode(output_tokens[0], skip_special_tokens=True)print(f"decoded output: {decoded_output}")Copied
decoded output:Hello, I'm a language model, and I'm going to help you with your problem.
Ya hemos conseguido generar texto con GPT-2
Generar texto token a token
Greedy search
Hemos usado model.generate para generar los tokens de salida de golpe, pero vamos a ver cómo generarlos uno a uno. Para ello, en vez de usar model.generate vamos a usar model, que en realidad lo que hace es llamar al método model.forward
InputPythonoutputs = model(**input_tokens)outputsCopied
CausalLMOutputWithCrossAttentions(loss=None, logits=tensor([[[ 6.6288, 5.1421, -0.8002, ..., -6.3998, -4.4113, 1.8240],[ 2.7250, 1.9371, -1.2293, ..., -5.0979, -5.1617, 2.2694],[ 2.6891, 4.3089, -1.6074, ..., -7.6321, -2.0448, 0.4042],...,[ 6.0513, 3.8020, -2.8080, ..., -6.7754, -8.3176, 1.1541],[ 6.8402, 5.6952, 0.2002, ..., -9.1281, -6.7818, 2.7576],[ 1.0255, -0.2201, -2.5484, ..., -6.2137, -7.2322, 0.1665]]],device='cuda:0', grad_fn=<UnsafeViewBackward0>), past_key_values=((tensor([[[[ 0.4779, 0.7671, -0.7532, ..., -0.3551, 0.4590, 0.3073],[ 0.2034, -0.6033, 0.2484, ..., 0.7760, -0.3546, 0.0198],[-0.1968, -0.9029, 0.5570, ..., 0.9985, -0.5028, -0.3508],...,[-0.5007, -0.4009, 0.1604, ..., -0.3693, -0.1158, 0.1320],[-0.4854, -0.1369, 0.7377, ..., -0.8043, -0.1054, 0.0871],[ 0.1610, -0.8358, -0.5534, ..., 0.9951, -0.3085, 0.4574]],[[ 0.6288, -0.1374, -0.3467, ..., -1.0003, -1.1518, 0.3114],[-1.7269, 1.2920, -0.0734, ..., 1.0572, 1.4698, -2.0412],[ 0.2714, -0.0670, -0.4769, ..., 0.6305, 0.6890, -0.8158],...,[-0.0499, -0.0721, 0.4580, ..., 0.6797, 0.2331, 0.0210],[-0.1894, 0.2077, 0.6722, ..., 0.6938, 0.2104, -0.0574],[ 0.3661, -0.0218, 0.2618, ..., 0.8750, 1.2205, -0.6103]],[[ 0.5964, 1.1178, 0.3604, ..., 0.8426, 0.4881, -0.4094],[ 0.3186, -0.3953, 0.2687, ..., -0.1110, -0.5640, 0.5900],...,[ 0.2092, 0.3898, -0.6061, ..., -0.2859, -0.3136, -0.1002],[ 0.0539, 0.8941, 0.3423, ..., -0.6326, -0.1053, -0.6679],[ 0.5628, 0.6687, -0.2720, ..., -0.1073, -0.9792, -0.0302]]]],device='cuda:0', grad_fn=<PermuteBackward0>))), hidden_states=None, attentions=None, cross_attentions=None)
Vemos que saca muchos datos, primero vamos a ver las keys de la salida
InputPythonoutputs.keys()Copied
odict_keys(['logits', 'past_key_values'])
En este caso solo tenemos los logits del modelo, vamos a ver su tamaño
InputPythonlogits = outputs.logitslogits.shapeCopied
torch.Size([1, 8, 50257])
Vamos a ver cuántos tokens teníamos a la entrada
InputPythoninput_tokens.input_ids.shapeCopied
torch.Size([1, 8])
Vaya, a la salida tenemos el mismo número de logits que a la entrada. Esto es normal
Obtenemos los logits de la última posición de la salida
InputPythonnex_token_logits = logits[0,-1]nex_token_logits.shapeCopied
torch.Size([50257])
Hay un total de 50257 logits, es decir, hay un vocabulario de 50257 tokens y tenemos que ver cuál es el token con mayor probabilidad, para ello primero calculamos la softmax
InputPythonsoftmax_logits = torch.softmax(nex_token_logits, dim=0)softmax_logits.shapeCopied
torch.Size([50257])
Una vez hemos calculado la softmax obtenemos el token más probable buscando el que tenga mayor probabilidad, es decir, el que tenga el mayor valor después de la softmax
InputPythonnext_token_prob, next_token_id = torch.max(softmax_logits, dim=0)next_token_prob, next_token_idCopied
(tensor(0.1732, device='cuda:0', grad_fn=<MaxBackward0>),tensor(290, device='cuda:0'))
Hemos obtenido el siguiente token, ahora lo decodificamos
InputPythontokenizer.decode(next_token_id.item())Copied
' and'
Hemos obtenido el siguiente token mediante el método greedy, es decir, el token con mayor probabilidad. Pero ya vimos en el post de la librería transformers las formas de generar textos que se puede hacer sampling, top-k, top-p, etc.
Vamos a meter todo en una función y ver qué sale si generamos unos cuantos tokens
InputPythondef generate_next_greedy_token(input_sentence, tokenizer, model, device):input_tokens = tokenizer(input_sentence, return_tensors="pt").to(device)outputs = model(**input_tokens)logits = outputs.logitsnex_token_logits = logits[0,-1]softmax_logits = torch.softmax(nex_token_logits, dim=0)next_token_prob, next_token_id = torch.max(softmax_logits, dim=0)return next_token_prob, next_token_idCopied
InputPythondef generate_greedy_text(input_sentence, tokenizer, model, device, max_length=20):generated_text = input_sentencefor _ in range(max_length):next_token_prob, next_token_id = generate_next_greedy_token(generated_text, tokenizer, model, device)generated_text += tokenizer.decode(next_token_id.item())return generated_textCopied
Ahora generamos texto
InputPythongenerate_greedy_text("Hello, I'm a language model,", tokenizer, model, device)Copied
"Hello, I'm a language model, and I'm going to help you with your problem. I'm going to help you"
La salida es bastante repetitiva como ya se vio en las formas de generar textos. Pero aun así, es mejor salida que la que obteníamos con GPT-1
Arquitectura de los modelos disponibles en Hugging Face
Si nos vamos a la documentación de Hugging Face de GPT2 podemos ver que tenemos las opciones GPT2Model, GPT2LMHeadModel, GPT2ForSequenceClassification, GPT2ForQuestionAnswering, GPT2ForTokenClassification. Vamos a verlos
InputPythonimport torchckeckpoints = "openai-community/gpt2"Copied
GPT2Model
Este es el modelo base, es decir, el decodificador del transformer
InputPythonfrom transformers import GPT2Modelmodel = GPT2Model.from_pretrained(ckeckpoints)modelCopied
GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))
Como se puede ver a la salida un tensor de dimensión 768, que es la dimensión de los embeddings del modelo pequeño. Si hubiésemos usado el modelo openai-community/gpt2-xl, hubiesemos obtenido una salida de 1600.
En función de la tarea que se quiera hacer, ahora habría que añadirle más capas.
Podemos añadirlas nosotros a mano, pero los pesos de esas capas se inicializarían aleatoriamente. Mientras que si usamos los modelos de Hugging Face con estas capas, los pesos están preentrenados
GPT2LMHeadModel
Es el que hemos utilizado antes para generar texto
InputPythonfrom transformers import GPT2LMHeadModelmodel = GPT2LMHeadModel.from_pretrained(ckeckpoints)modelCopied
GPT2LMHeadModel((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(lm_head): Linear(in_features=768, out_features=50257, bias=False))
Como se puede ver es el mismo modelo que antes, solo que al final se ha añadido una capa lineal con una entrada de 768 (los embeddings) y una salida de 50257, que corresponde al tamaño del vocabulario
GPT2ForSequenceClassification
Esta opción es para clasificar secuencias de texto, en este caso tenemos que especificarle con num_labels el número de clases que queremos clasificar.
InputPythonfrom transformers import GPT2ForSequenceClassificationmodel = GPT2ForSequenceClassification.from_pretrained(ckeckpoints, num_labels=5)modelCopied
Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
GPT2ForSequenceClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(score): Linear(in_features=768, out_features=5, bias=False))
Ahora, en vez de tener una salida de 50257, tenemos una salida de 5, que es el número que le hemos introducido en num_labels y es el número de clases que queremos clasificar
GPT2ForQuestionAnswering
En el post de transformers explicamos que, en este modo, se le pasa un contexto al modelo y una pregunta sobre el contexto y te devuelve la respuesta
InputPythonfrom transformers import GPT2ForQuestionAnsweringmodel = GPT2ForQuestionAnswering.from_pretrained(ckeckpoints)modelCopied
Some weights of GPT2ForQuestionAnswering were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['qa_outputs.bias', 'qa_outputs.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
GPT2ForQuestionAnswering((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(qa_outputs): Linear(in_features=768, out_features=2, bias=True))
Vemos que a la salida nos da un tensor de dos dimensiones
GPT2ForTokenClassification
También en el post de transformers contamos lo que era token classification, explicamos que clasificaba a qué categoría correspondía cada token. Tenemos que pasarle el número de clases que queremos clasificar con num_labels
InputPythonfrom transformers import GPT2ForTokenClassificationmodel = GPT2ForTokenClassification.from_pretrained(ckeckpoints, num_labels=5)modelCopied
Some weights of GPT2ForTokenClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['classifier.bias', 'classifier.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
GPT2ForTokenClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(dropout): Dropout(p=0.1, inplace=False)(classifier): Linear(in_features=768, out_features=5, bias=True))
A la salida obtenemos las cinco clases que le hemos especificado con num_labels
Fine tuning GPT-2
Fine tuning for text generation
Primero vamos a ver cómo se haría el entrenamiento con puro Pytorch
Cálculo de la loss
Antes de empezar a hacer el fine tuning de GPT-2 vamos a ver una cosa. Antes, cuando obteníamos la salida del modelo, hacíamos esto
InputPythonoutputs = model(**input_tokens)outputsCopied
CausalLMOutputWithCrossAttentions(loss=None, logits=tensor([[[ 6.6288, 5.1421, -0.8002, ..., -6.3998, -4.4113, 1.8240],[ 2.7250, 1.9371, -1.2293, ..., -5.0979, -5.1617, 2.2694],[ 2.6891, 4.3089, -1.6074, ..., -7.6321, -2.0448, 0.4042],...,[ 6.0513, 3.8020, -2.8080, ..., -6.7754, -8.3176, 1.1541],[ 6.8402, 5.6952, 0.2002, ..., -9.1281, -6.7818, 2.7576],[ 1.0255, -0.2201, -2.5484, ..., -6.2137, -7.2322, 0.1665]]],device='cuda:0', grad_fn=<UnsafeViewBackward0>), past_key_values=((tensor([[[[ 0.4779, 0.7671, -0.7532, ..., -0.3551, 0.4590, 0.3073],[ 0.2034, -0.6033, 0.2484, ..., 0.7760, -0.3546, 0.0198],[-0.1968, -0.9029, 0.5570, ..., 0.9985, -0.5028, -0.3508],...,[-0.5007, -0.4009, 0.1604, ..., -0.3693, -0.1158, 0.1320],[-0.4854, -0.1369, 0.7377, ..., -0.8043, -0.1054, 0.0871],[ 0.1610, -0.8358, -0.5534, ..., 0.9951, -0.3085, 0.4574]],[[ 0.6288, -0.1374, -0.3467, ..., -1.0003, -1.1518, 0.3114],[-1.7269, 1.2920, -0.0734, ..., 1.0572, 1.4698, -2.0412],[ 0.2714, -0.0670, -0.4769, ..., 0.6305, 0.6890, -0.8158],...,[-0.0499, -0.0721, 0.4580, ..., 0.6797, 0.2331, 0.0210],[-0.1894, 0.2077, 0.6722, ..., 0.6938, 0.2104, -0.0574],[ 0.3661, -0.0218, 0.2618, ..., 0.8750, 1.2205, -0.6103]],[[ 0.5964, 1.1178, 0.3604, ..., 0.8426, 0.4881, -0.4094],[ 0.3186, -0.3953, 0.2687, ..., -0.1110, -0.5640, 0.5900],...,[ 0.2092, 0.3898, -0.6061, ..., -0.2859, -0.3136, -0.1002],[ 0.0539, 0.8941, 0.3423, ..., -0.6326, -0.1053, -0.6679],[ 0.5628, 0.6687, -0.2720, ..., -0.1073, -0.9792, -0.0302]]]],device='cuda:0', grad_fn=<PermuteBackward0>))), hidden_states=None, attentions=None, cross_attentions=None)
Se puede ver que obtenemos loss=None
InputPythonprint(outputs.loss)Copied
None
Como vamos a necesitar la loss para hacer el fine tuning, vamos a ver cómo obtenerla.
Si nos vamos a la documentación del método forward de GPT2LMHeadModel, podemos ver que dice que a la salida devuelve un objeto de tipo transformers.modeling_outputs.CausalLMOutputWithCrossAttentions, así que si nos vamos a la documentación de transformers.modeling_outputs.CausalLMOutputWithCrossAttentions, podemos ver que dice que devuelve loss si se le pasa labels al método forward.
Si nos vamos a la fuente del código del método forward, vemos este bloque de código
loss = None
if labels is not None:
# move labels to correct device to enable model parallelism
labels = labels.to(lm_logits.device)
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
loss_fct = CrossEntropyLoss()
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))Es decir, la loss se calcula de la siguiente manera
- Shift de logits y labels: La primera parte es desplazar los logits (
lm_logits) y las etiquetas (labels) para que lostokens < npredigann, es decir, desde una posiciónnse predice el siguiente token a partir de los anteriores. - CrossEntropyLoss: Se crea una instancia de la función de pérdida
CrossEntropyLoss(). - Flatten tokens: A continuación, se aplanan los logits y las etiquetas utilizando
view(-1, shift_logits.size(-1))yview(-1), respectivamente. Esto se hace para que los logits y las etiquetas tengan la misma forma para la función de pérdida. - Cálculo de la pérdida: Finalmente, se calcula la pérdida utilizando la función de pérdida
CrossEntropyLoss()con los logits aplanados y las etiquetas aplanadas como entradas.
En resumen, la loss se calcula como la pérdida de entropía cruzada entre los logits desplazados y aplanados y las etiquetas desplazadas y aplanadas.
Por tanto, si al método forward le pasamos los labels, nos devolverá la loss
InputPythonoutputs = model(**input_tokens, labels=input_tokens.input_ids)outputs.lossCopied
tensor(3.8028, device='cuda:0', grad_fn=<NllLossBackward0>)
Dataset
Para el entrenamiento vamos a usar un dataset de chistes en inglés short-jokes-dataset, que es un dataset con 231 mil chistes en inglés.
Reiniciamos el notebook para que no haya problemas con la memoria de la GPU
Descargamos el dataset
InputPythonfrom datasets import load_datasetjokes = load_dataset("Maximofn/short-jokes-dataset")jokesCopied
DatasetDict({train: Dataset({features: ['ID', 'Joke'],num_rows: 231657})})
Vamos a verlo un poco
InputPythonjokes["train"][0]Copied
{'ID': 1,'Joke': '[me narrating a documentary about narrators] "I can't hear what they're saying cuz I'm talking"'}
Instancia del modelo
Para poder usar el modelo xl, es decir, el de 1.5B de parámetros, lo paso a FP16 para no quedarme sin memoria
InputPythonimport torchfrom transformers import AutoTokenizer, GPT2LMHeadModeldevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")ckeckpoints = "openai-community/gpt2-xl"tokenizer = AutoTokenizer.from_pretrained(ckeckpoints)model = GPT2LMHeadModel.from_pretrained(ckeckpoints)model = model.half().to(device)Copied
Pytorch dataset
Creamos una clase Dataset de Pytorch
InputPythonfrom torch.utils.data import Datasetclass JokesDataset(Dataset):def __init__(self, dataset, tokenizer):self.dataset = datasetself.joke = "JOKE: "self.end_of_text_token = "<|endoftext|>"self.tokenizer = tokenizerdef __len__(self):return len(self.dataset["train"])def __getitem__(self, item):sentence = self.joke + self.dataset["train"][item]["Joke"] + self.end_of_text_tokentokens = self.tokenizer(sentence, return_tensors="pt")return sentence, tokensCopied
La instanciamos
InputPythondataset = JokesDataset(jokes, tokenizer=tokenizer)Copied
Vemos un ejemplo
InputPythonsentence, tokens = dataset[5]print(sentence)tokens.input_ids.shape, tokens.attention_mask.shapeCopied
JOKE: Why can't Barbie get pregnant? Because Ken comes in a different box. Heyooooooo<|endoftext|>
(torch.Size([1, 22]), torch.Size([1, 22]))
Dataloader
Creamos ahora un DataLoader de Pytorch
InputPythonfrom torch.utils.data import DataLoaderBS = 1joke_dataloader = DataLoader(dataset, batch_size=BS, shuffle=True)Copied
Vemos un batch
InputPythonsentences, tokens = next(iter(joke_dataloader))len(sentences), tokens.input_ids.shape, tokens.attention_mask.shapeCopied
(1, torch.Size([1, 1, 36]), torch.Size([1, 1, 36]))
Training
InputPythonfrom transformers import AdamW, get_linear_schedule_with_warmupimport tqdmBATCH_SIZE = 32EPOCHS = 5LEARNING_RATE = 3e-6WARMUP_STEPS = 5000MAX_SEQ_LEN = 500optimizer = AdamW(model.parameters(), lr=LEARNING_RATE)scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=WARMUP_STEPS, num_training_steps=-1)proc_seq_count = 0batch_count = 0tmp_jokes_tens = Nonelosses = []lrs = []for epoch in range(EPOCHS):print(f"EPOCH {epoch} started" + '=' * 30)progress_bar = tqdm.tqdm(joke_dataloader, desc="Training")for sample in progress_bar:sentence, tokens = sample#################### "Fit as many joke sequences into MAX_SEQ_LEN sequence as possible" logic start ####joke_tens = tokens.input_ids[0].to(device)# Skip sample from dataset if it is longer than MAX_SEQ_LENif joke_tens.size()[1] > MAX_SEQ_LEN:continue# The first joke sequence in the sequenceif not torch.is_tensor(tmp_jokes_tens):tmp_jokes_tens = joke_tenscontinueelse:# The next joke does not fit in so we process the sequence and leave the last joke# as the start for next sequenceif tmp_jokes_tens.size()[1] + joke_tens.size()[1] > MAX_SEQ_LEN:work_jokes_tens = tmp_jokes_tenstmp_jokes_tens = joke_tenselse:#Add the joke to sequence, continue and try to add moretmp_jokes_tens = torch.cat([tmp_jokes_tens, joke_tens[:,1:]], dim=1)continue################## Sequence ready, process it trough the model ##################outputs = model(work_jokes_tens, labels=work_jokes_tens)loss = outputs.lossloss.backward()proc_seq_count = proc_seq_count + 1if proc_seq_count == BATCH_SIZE:proc_seq_count = 0batch_count += 1optimizer.step()scheduler.step()optimizer.zero_grad()model.zero_grad()progress_bar.set_postfix({'loss': loss.item(), 'lr': scheduler.get_last_lr()[0]})losses.append(loss.item())lrs.append(scheduler.get_last_lr()[0])if batch_count == 10:batch_count = 0Copied
/home/wallabot/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/optimization.py:429: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warningwarnings.warn(
EPOCH 0 started==============================
Training: 0%| | 0/231657 [00:00<?, ?it/s]
Training: 100%|██████████| 231657/231657 [32:29<00:00, 118.83it/s, loss=3.1, lr=2.31e-7]
EPOCH 1 started==============================
Training: 100%|██████████| 231657/231657 [32:34<00:00, 118.55it/s, loss=2.19, lr=4.62e-7]
EPOCH 2 started==============================
Training: 100%|██████████| 231657/231657 [32:36<00:00, 118.42it/s, loss=2.42, lr=6.93e-7]
EPOCH 3 started==============================
Training: 100%|██████████| 231657/231657 [32:23<00:00, 119.18it/s, loss=2.16, lr=9.25e-7]
EPOCH 4 started==============================
Training: 100%|██████████| 231657/231657 [32:22<00:00, 119.25it/s, loss=2.1, lr=1.16e-6]
InputPythonimport numpy as npimport matplotlib.pyplot as pltlosses_np = np.array(losses)lrs_np = np.array(lrs)plt.figure(figsize=(12,6))plt.plot(losses_np, label='loss')plt.plot(lrs_np, label='learning rate')plt.yscale('log')plt.legend()plt.show()Copied
<Figure size 1200x600 with 1 Axes>
Inference
Vamos a ver qué tal hace chistes el modelo
InputPythonsentence_joke = "JOKE:"input_tokens_joke = tokenizer(sentence_joke, return_tensors="pt").to(device)output_tokens_joke = model.generate(**input_tokens_joke)decoded_output_joke = tokenizer.decode(output_tokens_joke[0], skip_special_tokens=True)print(f"decoded joke: {decoded_output_joke}")Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation./home/wallabot/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/generation/utils.py:1178: UserWarning: Using the model-agnostic default `max_length` (=20) to control the generation length. We recommend setting `max_new_tokens` to control the maximum length of the generation.warnings.warn(
decoded joke:JOKE:!!!!!!!!!!!!!!!!!
Se puede ver que le pasas una secuencia con la palabra joke y te devuelve un chiste. Pero si le devuelves otra secuencia no
InputPythonsentence_joke = "My dog is cute and"input_tokens_joke = tokenizer(sentence_joke, return_tensors="pt").to(device)output_tokens_joke = model.generate(**input_tokens_joke)decoded_output_joke = tokenizer.decode(output_tokens_joke[0], skip_special_tokens=True)print(f"decoded joke: {decoded_output_joke}")Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
decoded joke:My dog is cute and!!!!!!!!!!!!!!!
Fine tuning GPT-2 for sentence classification
Ahora vamos a hacer un entrenamiento con las librerías de Hugging Face
Dataset
Vamos a usar el dataset imdb de clasificación de sentencias en positivas y negativas
InputPythonfrom datasets import load_datasetdataset = load_dataset("imdb")datasetCopied
DatasetDict({train: Dataset({features: ['text', 'label'],num_rows: 25000})test: Dataset({features: ['text', 'label'],num_rows: 25000})unsupervised: Dataset({features: ['text', 'label'],num_rows: 50000})})
Vamos a verlo un poco
InputPythondataset["train"].infoCopied
DatasetInfo(description='', citation='', homepage='', license='', features={'text': Value(dtype='string', id=None), 'label': ClassLabel(names=['neg', 'pos'], id=None)}, post_processed=None, supervised_keys=None, task_templates=None, builder_name='parquet', dataset_name='imdb', config_name='plain_text', version=0.0.0, splits={'train': SplitInfo(name='train', num_bytes=33435948, num_examples=25000, shard_lengths=None, dataset_name='imdb'), 'test': SplitInfo(name='test', num_bytes=32653810, num_examples=25000, shard_lengths=None, dataset_name='imdb'), 'unsupervised': SplitInfo(name='unsupervised', num_bytes=67113044, num_examples=50000, shard_lengths=None, dataset_name='imdb')}, download_checksums={'hf://datasets/imdb@e6281661ce1c48d982bc483cf8a173c1bbeb5d31/plain_text/train-00000-of-00001.parquet': {'num_bytes': 20979968, 'checksum': None}, 'hf://datasets/imdb@e6281661ce1c48d982bc483cf8a173c1bbeb5d31/plain_text/test-00000-of-00001.parquet': {'num_bytes': 20470363, 'checksum': None}, 'hf://datasets/imdb@e6281661ce1c48d982bc483cf8a173c1bbeb5d31/plain_text/unsupervised-00000-of-00001.parquet': {'num_bytes': 41996509, 'checksum': None}}, download_size=83446840, post_processing_size=None, dataset_size=133202802, size_in_bytes=216649642)
Vamos a ver las features que tiene este dataset
InputPythondataset["train"].info.featuresCopied
{'text': Value(dtype='string', id=None),'label': ClassLabel(names=['neg', 'pos'], id=None)}
El dataset contiene strings y clases. Además hay dos tipos de clases, pos y neg. Vamos a crear una variable con el número de clases
InputPythonnum_clases = len(dataset["train"].unique("label"))num_clasesCopied
2
Tokenizador
Creamos el tokenizador
InputPythonfrom transformers import GPT2Tokenizercheckpoints = "openai-community/gpt2"tokenizer = GPT2Tokenizer.from_pretrained(checkpoints, bos_token='<|startoftext|>', eos_token='<|endoftext|>', pad_token='<|pad|>')tokenizer.pad_token = tokenizer.eos_tokenCopied
Ahora que tenemos un tokenizador podemos tokenizar el dataset, ya que el modelo solo entiende tokens
InputPythondef tokenize_function(examples):return tokenizer(examples["text"], padding="max_length", truncation=True)tokenized_datasets = dataset.map(tokenize_function, batched=True)Copied
Modelo
Instanciamos el modelo
InputPythonfrom transformers import GPT2ForSequenceClassificationmodel = GPT2ForSequenceClassification.from_pretrained(checkpoints, num_labels=num_clases).half()model.config.pad_token_id = model.config.eos_token_idCopied
Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Evaluación
Creamos una métrica de evaluación
InputPythonimport numpy as npimport evaluatemetric = evaluate.load("accuracy")def compute_metrics(eval_pred):logits, labels = eval_predpredictions = np.argmax(logits, axis=-1)return metric.compute(predictions=predictions, references=labels)Copied
Trainer
Creamos el trainer
InputPythonfrom transformers import Trainer, TrainingArgumentstraining_args = TrainingArguments(output_dir="./results",learning_rate=2e-5,per_device_train_batch_size=16,per_device_eval_batch_size=64,num_train_epochs=3,weight_decay=0.01,)trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_datasets["train"],eval_dataset=tokenized_datasets["test"],compute_metrics=compute_metrics,)Copied
Entrenamiento
Entrenamos
InputPythontrainer.train()Copied
<IPython.core.display.HTML object>
TrainOutput(global_step=4689, training_loss=0.04045845954294626, metrics={'train_runtime': 5271.3532, 'train_samples_per_second': 14.228, 'train_steps_per_second': 0.89, 'total_flos': 3.91945125888e+16, 'train_loss': 0.04045845954294626, 'epoch': 3.0})
Inferencia
Probamos el modelo después de entrenarlo
InputPythonimport torchdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")def get_sentiment(sentence):inputs = tokenizer(sentence, return_tensors="pt").to(device)outputs = model(**inputs)prediction = outputs.logits.argmax(-1).item()return "positive" if prediction == 1 else "negative"Copied
InputPythonsentence = "I hate this movie!"print(get_sentiment(sentence))Copied
negative

















