Está claro que el mayor hub de modelos de inteligencia artificial es Hugging Face. Y ahora están dando la posibilidad de hacer inferencia de alguno de sus modelos en proveedores de GPUs serverless
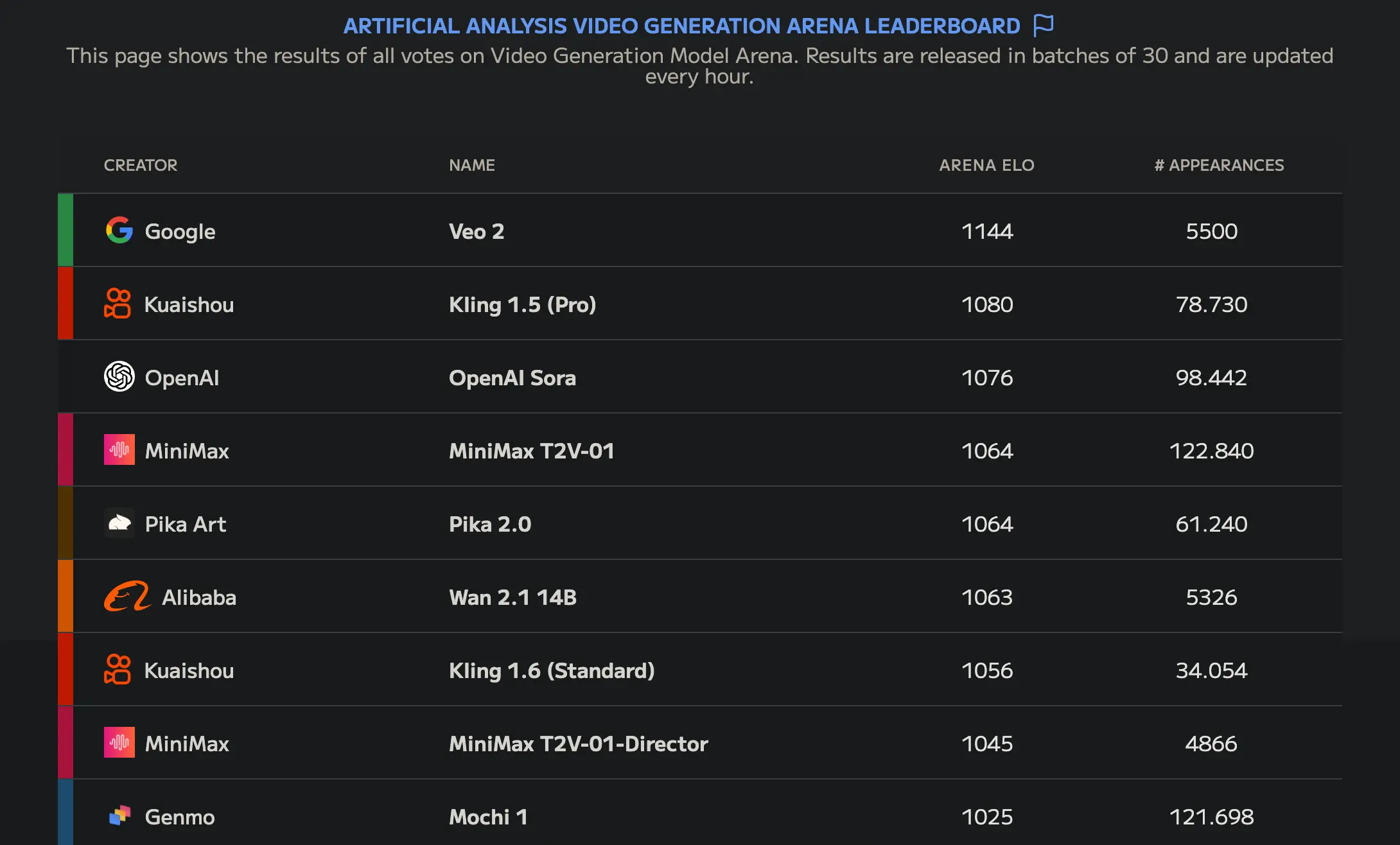
Uno de esos modelos es Wan-AI/Wan2.1-T2V-14B que a día de escribir este post es el mejor modelo de generación de vídeo open source, como se puede ver en la Artificial Analysis Video Generation Arena Leaderboard
Si nos fijamos en su modelcard podemos ver a la derecha un botón que pone Replicate.
Inference providers
Si vamos a la página de configuración de los Inference providers veremos algo como esto
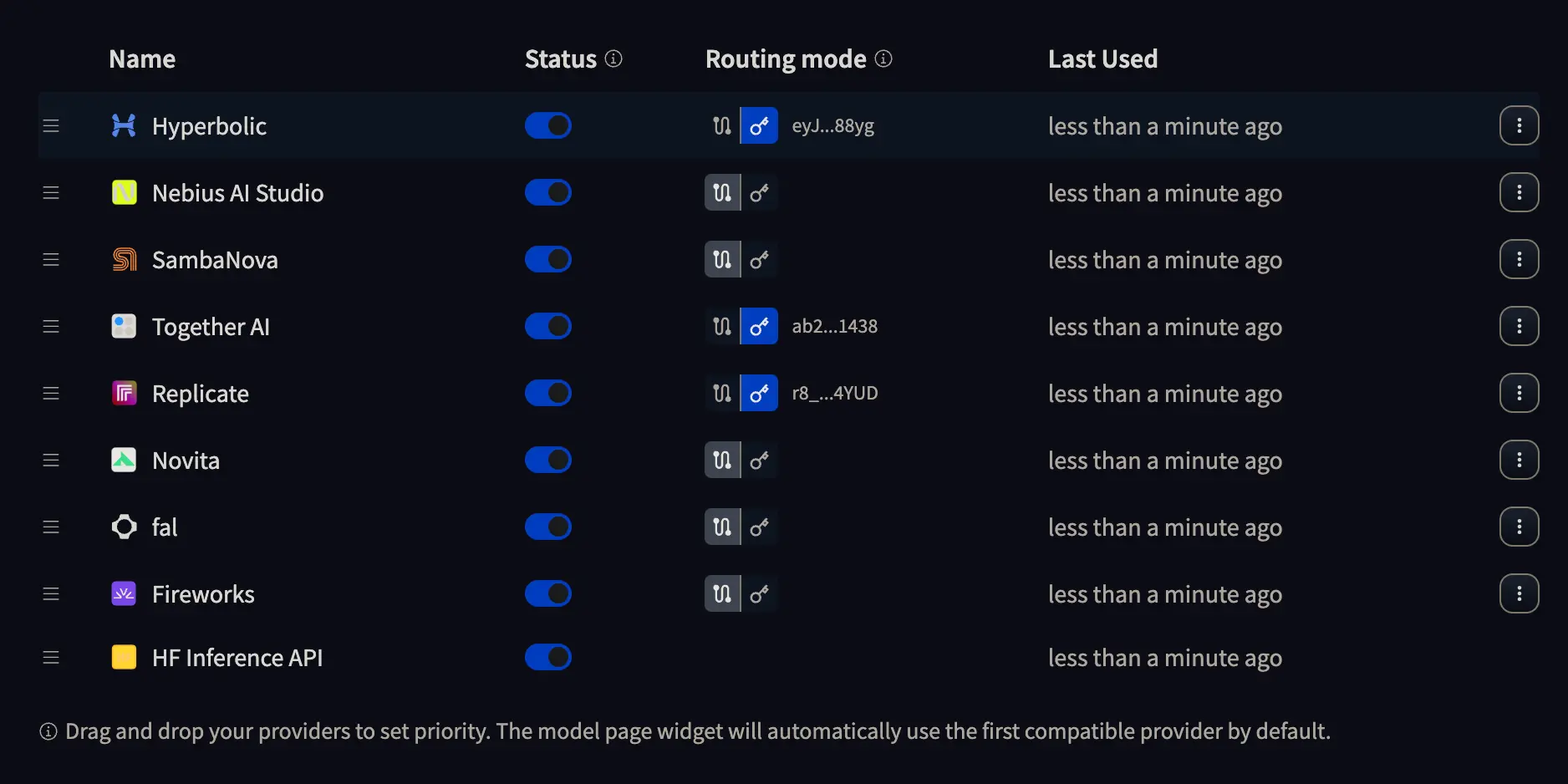
Dónde podemos darle al botón con una llave para introducir la API KEY del proveedor que queramos usar, o dejar seleccionado el camino con dos puntos. Si hacemos la primera opción será el proveedor el que nos cobre por la inferencia, mientras que en el segundo será Hugging Face quien nos cobre la inferencia. Así que haz lo que mejor te convenga
Inferencia con Replicate
En mi caso he obtenido una API KEY de Replicate y la he introducido en un archivo llamado .env que es donde guardaré las API KEYs y que no debes subir a GitHub, GitLab o el repositorio de tu proyecto.
El .env tiene que tener este formato
HUGGINGFACE_TOKEN_INFERENCE_PROVIDERS="hf_aL...AY"
REPLICATE_API_KEY="r8_Sh...UD"Donde HUGGINGFACE_TOKEN_INFERENCE_PROVIDERS es un token que tienes que obtener desde Hugging Face y REPLICATE_API_KEY es la API KEY de Replicate que puedes obtener desde Replicate.
Lectura de las API KEYs
Lo primero que tenemos que hacer es leer las API KEYs desde el archivo .env
InputPythonimport osimport dotenvdotenv.load_dotenv()REPLICATE_API_KEY = os.getenv("REPLICATE_API_KEY")HUGGINGFACE_TOKEN_INFERENCE_PROVIDERS = os.getenv("HUGGINGFACE_TOKEN_INFERENCE_PROVIDERS")Copied
Logging en el hub de Hugging Face
Para poder usar el modelo de Wan-AI/Wan2.1-T2V-14B, como está en el hub de Hugging Face, necesitamos loguearnos.
InputPythonfrom huggingface_hub import loginlogin(HUGGINGFACE_TOKEN_INFERENCE_PROVIDERS)Copied
Cliente de Inferencia
Ahora creamos un cliente de inferencia, tenemos que especificar el proveedor, la API KEY y en este caso, además, vamos a establecer un tiempo de timeout de 1000 segundos, porque por defecto es de 60 segundos y el modelo tarda bastante en generar el vídeo.
InputPythonfrom huggingface_hub import InferenceClientclient = InferenceClient(provider="replicate",api_key=REPLICATE_API_KEY,timeout=1000)Copied
Generación del vídeo
Ya tenemos todo para generar nuestro video. Usamos el método text_to_video del cliente, le pasamos el prompt y le decimos qué modelo del hub queremos usar, si no usará el que está por defecto.
InputPythonvideo = client.text_to_video("Funky dancer, dancing in a rehearsal room. She wears long hair that moves to the rhythm of her dance.",model="Wan-AI/Wan2.1-T2V-14B",)Copied
Guardando el vídeo
Por último guardamos el video, que es de tipo bytes, en un fichero en nuestro disco
InputPythonoutput_path = "output_video.mp4"with open(output_path, "wb") as f:f.write(video)print(f"Video saved to: {output_path}")Copied
Video saved to: output_video.mp4
Video generado
Este es el video generado por el modelo