
Ahora que están en auge los LLMs, no paramos de escuchar el número de tokens que admite cada modelo, pero ¿qué son los tokens? Son las unidades mínimas de representación de las palabras
Para explicar qué son los tokens, primero veámoslo con un ejemplo práctico, vamos a usar el tokenizador de OpenAI, llamado tiktoken.
Así que, primero instalamos el paquete:
pip install tiktokenUna vez instalado creamos un tokenizador usando el modelo cl100k_base, que en el notebook de ejemplo How to count tokens with tiktoken explica que es el usado por los modelos gpt-4, gpt-3.5-turbo y text-embedding-ada-002
import tiktokenencoder = tiktoken.get_encoding("cl100k_base")Copied
Ahora creamos una palabra de ejemplo para tokenizarla
example_word = "breakdown"Copied
Y la tokenizamos
tokens = encoder.encode(example_word)tokensCopied
[9137, 2996]
Se ha dividido la palabra en 2 tokens, el 9137 y el 2996. Vamos a ver a qué palabras corresponden
word1 = encoder.decode([tokens[0]])word2 = encoder.decode([tokens[1]])word1, word2Copied
('break', 'down')
El tokenizador de OpenAI ha dividido la palabra breakdown en las palabras break y down. Es decir, ha dividido la palabra en 2 más sencillas.
Esto es importante, ya que cuando se dice que un LLM admite x tokens no se refiere a que admite x palabras, sino a que admite x unidades mínimas de representación de las palabras.
Si tienes un texto y quieres ver el número de tokens que tiene para el tokenizador de OpenAI, puedes verlo en la página Tokenizer, que muestra cada token en un color diferente
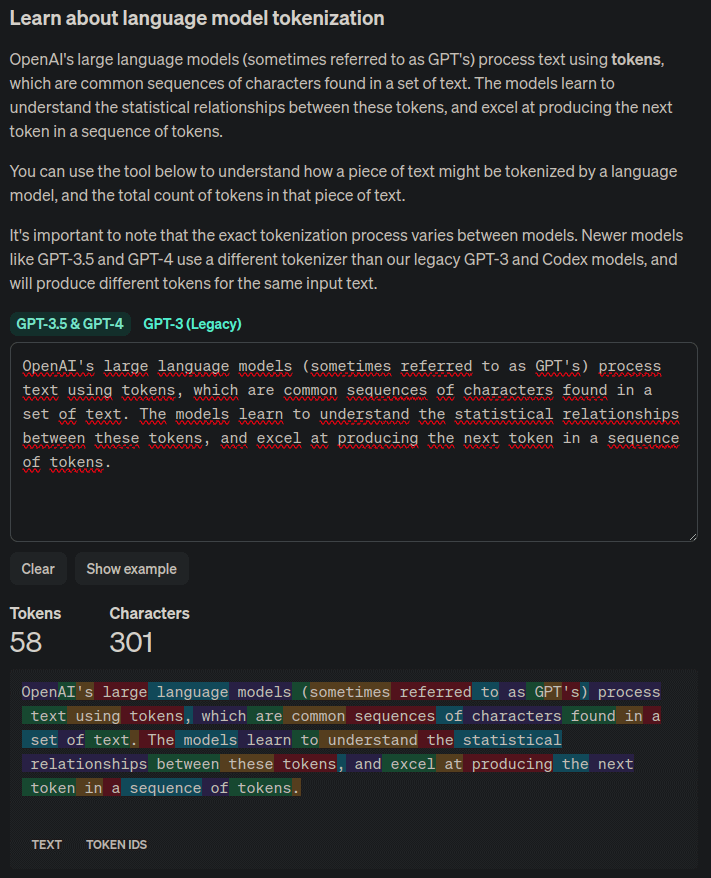
Hemos visto el tokenizador de OpenAI, pero cada LLM podrá usar otro
Como hemos dicho, los tokens son las unidades mínimas de representación de las palabras, así que vamos a ver cuántos tokens distintos tiene tiktoken
n_vocab = encoder.n_vocabprint(f"Vocab size: {n_vocab}")Copied
Vocab size: 100277
Vamos a ver cómo tokeniza otro tipo de palabras
def encode_decode(word):tokens = encoder.encode(word)decode_tokens = []for token in tokens:decode_tokens.append(encoder.decode([token]))return tokens, decode_tokensCopied
word = "dog"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "tomorrow..."tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "artificial intelligence"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "Python"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "12/25/2023"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "😊"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")Copied
Word: dog ==> tokens: [18964], decode_tokens: ['dog']Word: tomorrow... ==> tokens: [38501, 7924, 1131], decode_tokens: ['tom', 'orrow', '...']Word: artificial intelligence ==> tokens: [472, 16895, 11478], decode_tokens: ['art', 'ificial', ' intelligence']Word: Python ==> tokens: [31380], decode_tokens: ['Python']Word: 12/25/2023 ==> tokens: [717, 14, 914, 14, 2366, 18], decode_tokens: ['12', '/', '25', '/', '202', '3']Word: 😊 ==> tokens: [76460, 232], decode_tokens: ['�', '�']
Por último vamos a verlo con palabras en otro idioma
word = "perro"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "perra"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "mañana..."tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "inteligencia artificial"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "Python"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "12/25/2023"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")word = "😊"tokens, decode_tokens = encode_decode(word)print(f"Word: {word} ==> tokens: {tokens}, decode_tokens: {decode_tokens}")Copied
Word: perro ==> tokens: [716, 299], decode_tokens: ['per', 'ro']Word: perra ==> tokens: [79, 14210], decode_tokens: ['p', 'erra']Word: mañana... ==> tokens: [1764, 88184, 1131], decode_tokens: ['ma', 'ñana', '...']Word: inteligencia artificial ==> tokens: [396, 39567, 8968, 21075], decode_tokens: ['int', 'elig', 'encia', ' artificial']Word: Python ==> tokens: [31380], decode_tokens: ['Python']Word: 12/25/2023 ==> tokens: [717, 14, 914, 14, 2366, 18], decode_tokens: ['12', '/', '25', '/', '202', '3']Word: 😊 ==> tokens: [76460, 232], decode_tokens: ['�', '�']
Podemos ver para palabras similares, en español se generan más tokens que en inglés, por lo que para un mismo texto, con un número similar de palabras, el número de tokens será mayor en español que en inglés
















