En mi post anterior expliqué cómo usar LangGraph para crear agentes.
Así que en este vamos a ver los diferentes patrones de agentes que podemos construir y lo haremos con LangGraph.
**Nota**: Vamos a partir desde el modelo más básico que consiste en un chatbot con un LLM hasta llegar a arquitecturas más complejas.
**Nota**: Siempre que sea posible, vamos a usar
Qwen2-72B-Instructpara poder usarlo gratis con Hugging Face.
Respondedor de prompts (chain block)

Es el modelo más básico, al LLM le entra un prompt y él devuelve una respuesta.
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom huggingface_hub import loginfrom IPython.display import Image, displayimport osos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracingimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")# Stateclass State(TypedDict):messages: Annotated[list, add_messages]# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Functiondef chatbot_function(state: State):return {"messages": [llm.invoke(state["messages"])]}# Start to build the graphgraph_builder = StateGraph(State)# Add nodes to the graphgraph_builder.add_node("chatbot_node", chatbot_function)# Add edgesgraph_builder.add_edge(START, "chatbot_node")graph_builder.add_edge("chatbot_node", END)# Compile the graphgraph = graph_builder.compile()# Display the graphtry:display(Image(graph.get_graph().draw_mermaid_png()))except Exception as e:print(f"Error al visualizar el grafo: {e}")Copied
<IPython.core.display.Image object>
Vamos a probarlo
from langchain_core.messages import HumanMessagemessages = [HumanMessage(content="Hello, how are you?")]result = graph.invoke({"messages": messages})result["messages"][-1].pretty_print()Copied
================================== Ai Message ==================================Hello! I'm doing well, thank you for asking. How about you? How can I assist you today?
Cadena de bloques (chain of blocks)

Cuando una tarea se puede dividir en varias subtareas, podemos usar una cadena de bloques. Por ejemplo, si queremos resumir y traducir un texto, podemos hacerlo en dos pasos:
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom langchain_core.messages import SystemMessagefrom huggingface_hub import loginfrom IPython.display import Image, displayimport osos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracingimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")# Stateclass State(TypedDict):messages: Annotated[list, add_messages]# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Functiondef summary(state: State):input_text = state["messages"][-1].contentprompt = f"Summarize the following text: {input_text}"llm_response = llm.invoke(prompt)return {"messages": [llm_response]}def translate(state: State):input_text = state["messages"][-1].contentprompt = f"Translate the following text to Spanish: {input_text}"llm_response = llm.invoke(prompt)return {"messages": [llm_response]}# Start to build the graphgraph_builder = StateGraph(State)# Add nodes to the graphgraph_builder.add_node("summary", summary)graph_builder.add_node("translate", translate)# Add edgesgraph_builder.add_edge(START, "summary")graph_builder.add_edge("summary", "translate")graph_builder.add_edge("translate", END)# Compile the graphgraph = graph_builder.compile()# Display the graphtry:display(Image(graph.get_graph().draw_mermaid_png()))except Exception as e:print(f"Error al visualizar el grafo: {e}")Copied
<IPython.core.display.Image object>
from langchain_core.messages import HumanMessagetext = """Large language models are powerful AI systems trained on vast amounts of text data.They can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in an informative way."""messages = [HumanMessage(content=text)]result = graph.invoke({"messages": messages})for message in result["messages"]:message.pretty_print()Copied
================================ Human Message =================================Large language models are powerful AI systems trained on vast amounts of text data.They can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in an informative way.================================== Ai Message ==================================Large language models are advanced AI systems trained on extensive text data, enabling them to produce human-like text, translate languages, create various types of creative content, and provide informative answers to questions.================================== Ai Message ==================================Los modelos de lenguaje grandes son sistemas de IA avanzados entrenados con extensos datos de texto, lo que les permite producir texto similar al humano, traducir idiomas, crear diversos tipos de contenido creativo y proporcionar respuestas informativas a preguntas.
Enrutamiento (routing)
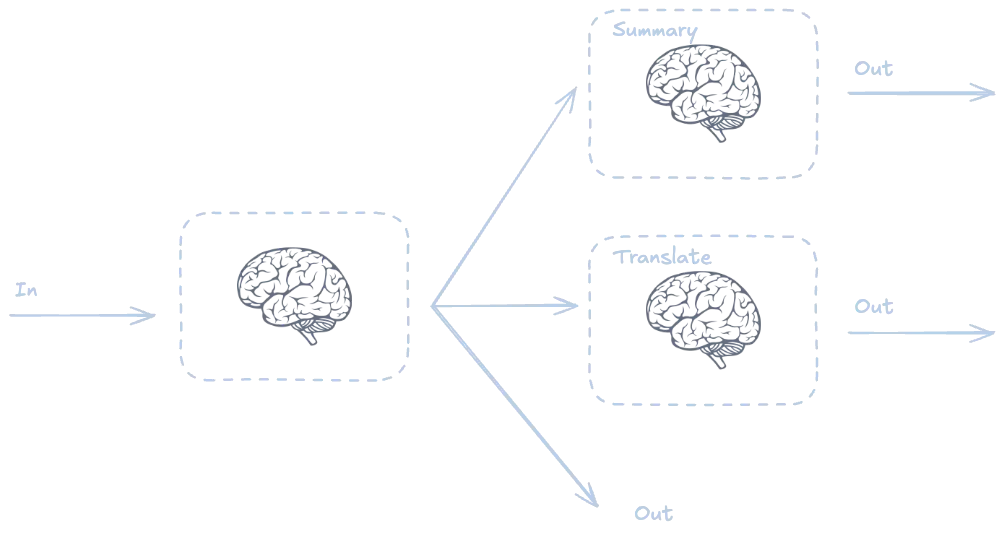
Otra cosa que podemos hacer es crear varias rutas en función del problema y elegir la que mejor se adapte a nuestro problema. Vamos a ver un ejemplo en el que el usuario puede elegir entre resumir o traducir un texto.
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom langchain_core.messages import SystemMessage, HumanMessagefrom huggingface_hub import loginfrom IPython.display import Image, displayimport osos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracingimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")# Stateclass State(TypedDict):messages: Annotated[list, add_messages]# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Functiondef chatbot_function(state: State):return {"messages": [llm.invoke(state["messages"])]}def summary(state: State):input_text = state["messages"][-1].contentprompt = f"Summarize the following text: {input_text}"llm_response = llm.invoke(prompt)return {"messages": [llm_response]}def translate(state: State):input_text = state["messages"][-1].contentprompt = f"Translate the following text to Spanish: {input_text}"llm_response = llm.invoke(prompt)return {"messages": [llm_response]}# Decision function for conditional edgesdef decide_next_step(state: State) -> str:"""Decides the next step after the chatbot_node.It checks the user's last message for keywords like 'summarize' or 'translate'."""# Filter out human messages from the stateuser_messages = [msg for msg in state["messages"] if isinstance(msg, HumanMessage)]if not user_messages:# If there are no human messages, default to ending the processreturn "end"# Get the content of the last human messagelast_user_message_content = user_messages[-1].content.lower()if "summarize" in last_user_message_content or "resumir" in last_user_message_content:# If the user asked to summarizereturn "summary"elif "translate" in last_user_message_content or "traducir" in last_user_message_content:# If the user asked to translatereturn "translate"else:# Otherwise, end the processreturn "end"# Start to build the graphgraph_builder = StateGraph(State)# Add nodes to the graphgraph_builder.add_node("chatbot_node", chatbot_function)graph_builder.add_node("summary", summary)graph_builder.add_node("translate", translate)# Add edgesgraph_builder.add_edge(START, "chatbot_node")# Add conditional edges from chatbot_node# The decide_next_step function will determine which path to takegraph_builder.add_conditional_edges("chatbot_node", # The node where the decision is madedecide_next_step, # The function that makes the decision{ # A dictionary mapping decision outcomes to next nodes"summary": "summary", # If decide_next_step returns "summary", go to the "summary" node"translate": "translate", # If decide_next_step returns "translate", go to the "translate" node"end": END # If decide_next_step returns "end", end the graph})# Add edges to end the graph after summary or translategraph_builder.add_edge("summary", END)graph_builder.add_edge("translate", END)# Compile the graphgraph = graph_builder.compile()# Display the graphtry:display(Image(graph.get_graph().draw_mermaid_png()))except Exception as e:print(f"Error al visualizar el grafo: {e}")Copied
<IPython.core.display.Image object>
from langchain_core.messages import HumanMessagetext = """Large language models are powerful AI systems trained on vast amounts of text data.They can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in an informative way."""prompt = f"Summarize the following text: {text}"messages = [HumanMessage(content=prompt)]result = graph.invoke({"messages": messages})for message in result["messages"]:message.pretty_print()Copied
================================ Human Message =================================Summarize the following text: Large language models are powerful AI systems trained on vast amounts of text data.They can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in an informative way.================================== Ai Message ==================================Large language models are advanced AI systems trained on extensive text data, enabling them to produce human-like text, translate languages, create various types of creative content, and provide informative answers to questions.================================== Ai Message ==================================Large language models are sophisticated AI systems trained on vast amounts of text data, which allows them to generate human-like text, translate languages, produce creative content, and answer questions informatively.
from langchain_core.messages import HumanMessagetext = """Large language models are powerful AI systems trained on vast amounts of text data.They can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in an informative way."""prompt = f"Translate the following text to Spanish: {text}"messages = [HumanMessage(content=prompt)]result = graph.invoke({"messages": messages})for message in result["messages"]:message.pretty_print()Copied
================================ Human Message =================================Translate the following text to Spanish: Large language models are powerful AI systems trained on vast amounts of text data.They can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in an informative way.================================== Ai Message ==================================Los modelos de lenguaje grandes son sistemas de IA potentes entrenados en enormes cantidades de datos de texto. Pueden generar texto similar al humano, traducir idiomas, escribir diversos tipos de contenido creativo y responder a tus preguntas de manera informativa.================================== Ai Message ==================================Los grandes modelos de lenguaje son sistemas de IA potentes entrenados en enormes cantidades de datos de texto. Pueden generar texto similar al humano, traducir idiomas, escribir diversos tipos de contenido creativo y responder a tus preguntas de manera informativa.
Paralelización (parallelization)
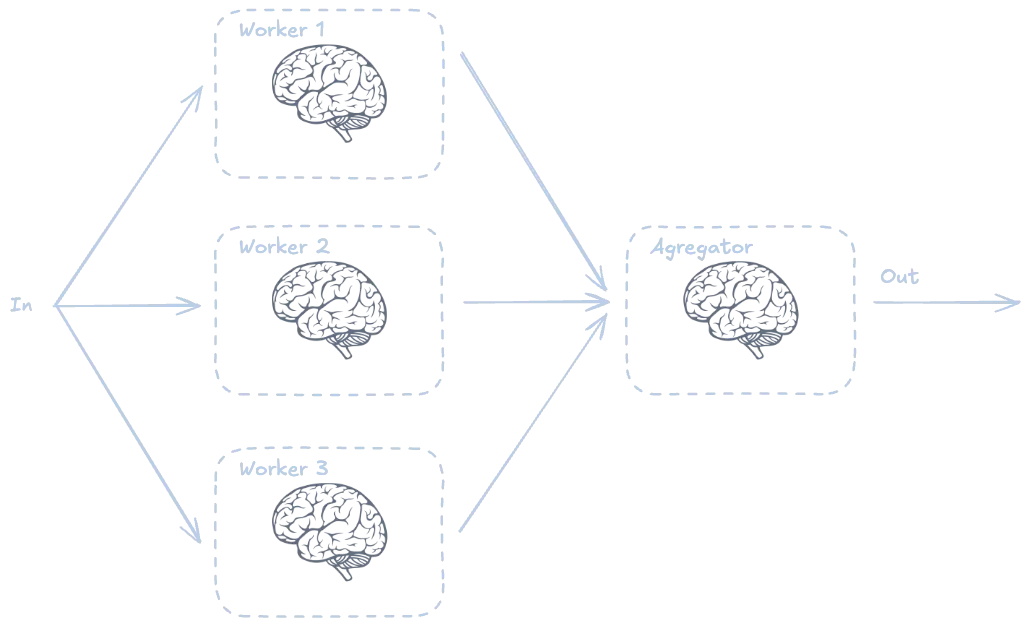
Cuando una tarea es muy importante o compleja podemos paralelizarla para que la ejecuten diferentes LLMs. Después le pasamos el resultado a un LLM para que pueda combinarlos. Vamos a ver un ejemplo en el que tenemos tres LLMs que resumen un texto de manera diferente y luego lo combinamos.
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom langchain_core.messages import SystemMessage, HumanMessagefrom huggingface_hub import loginfrom IPython.display import Image, displayimport osos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracingimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")# Stateclass State(TypedDict):messages: Annotated[list, add_messages]tiny_summary: strnormal_summary: strextended_summary: str# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Functiondef tiny_summary(state: State):input_text = state["messages"][-1].contentprompt = f"Summarize the following text in 10 words: {input_text}"llm_response = llm.invoke(prompt)return {"messages": [llm_response], "tiny_summary": llm_response.content}def normal_summary(state: State):input_text = state["messages"][-1].contentprompt = f"Summarize the following text: {input_text}"llm_response = llm.invoke(prompt)return {"messages": [llm_response], "normal_summary": llm_response.content}def extended_summary(state: State):input_text = state["messages"][-1].contentprompt = f"Summarize the following text in 100 words: {input_text}"llm_response = llm.invoke(prompt)return {"messages": [llm_response], "extended_summary": llm_response.content}def aggregate(state: State):prompt = f"Combine the following summaries into a single one: {state['tiny_summary']}, {state['normal_summary']}, {state['extended_summary']}"llm_response = llm.invoke(prompt)return {"messages": [llm_response]}# Start to build the graphgraph_builder = StateGraph(State)# Add nodes to the graphgraph_builder.add_node("tiny_summary_node", tiny_summary)graph_builder.add_node("normal_summary_node", normal_summary)graph_builder.add_node("extended_summary_node", extended_summary)graph_builder.add_node("aggregate_node", aggregate)# Add edgesgraph_builder.add_edge(START, "tiny_summary_node")graph_builder.add_edge(START, "normal_summary_node")graph_builder.add_edge(START, "extended_summary_node")graph_builder.add_edge("tiny_summary_node", "aggregate_node")graph_builder.add_edge("normal_summary_node", "aggregate_node")graph_builder.add_edge("extended_summary_node", "aggregate_node")graph_builder.add_edge("aggregate_node", END)# Compile the graphgraph = graph_builder.compile()# Display the graphtry:display(Image(graph.get_graph().draw_mermaid_png()))except Exception as e:print(f"Error al visualizar el grafo: {e}")Copied
<IPython.core.display.Image object>
from langchain_core.messages import HumanMessagetext = """Large language models are powerful AI systems trained on vast amounts of text data.They can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in an informative way."""messages = [HumanMessage(content=text)]result = graph.invoke({"messages": messages})for message in result["messages"]:message.pretty_print()Copied
================================ Human Message =================================Large language models are powerful AI systems trained on vast amounts of text data.They can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in an informative way.================================== Ai Message ==================================Large language models are advanced AI systems trained on extensive text data, enabling them to produce human-like text, translate languages, create diverse content, and provide informative answers to questions. These models leverage their vast training data to understand context and generate responses that are often indistinguishable from those written by humans, making them useful in various applications such as writing, translation, and customer service.================================== Ai Message ==================================Large language models are advanced AI systems trained on extensive text data, enabling them to produce human-like text, translate languages, create various types of creative content, and provide informative answers to questions.================================== Ai Message ==================================AI models trained on text data generate human-like responses, translations, and content.================================== Ai Message ==================================Large language models are advanced AI systems trained on extensive text data, enabling them to produce human-like text, translate languages, create diverse and creative content, and provide informative answers to questions. These models leverage their vast training data to understand context and generate responses that are often indistinguishable from those written by humans, making them useful in various applications such as writing, translation, and customer service.
Evaluador-optimizador (reflection pattern)

Otra manera de resolver tareas complejas es tener un LLM para resolver la tarea y otro LLM para evaluar el resultado, de manera que se ejecutan en bucle, hasta que el evaluador considera que el trabajo ha finalizado correctamente. Vamos a ver un ejemplo en el que un LLM suma 1 a un número y otro comprueba si el número es 10.
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom langchain_core.messages import SystemMessage, HumanMessage, AIMessagefrom huggingface_hub import loginfrom IPython.display import Image, displayimport osos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracingimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")# Stateclass State(TypedDict):messages: Annotated[list, add_messages]number: intevaluator: str# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Functiondef agregate_1(state: State):if state.get("number", None) is None:input_text = state["messages"][-1].contentprompt = f"Get the number from the following text: {input_text}. Respond only with the number."number_str = llm.invoke(prompt)number = int(number_str.content)state["number"] = numbernumber_state = state["number"]number_plus_1 = number_state + 1response = AIMessage(content=f"[Agregator] --> The number is {number_state} and the next number is {number_plus_1}")return {"messages": [response], "number": number_plus_1, "evaluator": "no"}def evaluator(state: State):prompt = f"Is the following number {state['number']} equal to 10? Respond only with 'yes' or 'no'."result = llm.invoke(prompt)number_state = state["number"]response = AIMessage(content=f"[Evaluator] --> Is the following number {number_state} equal to 10? Result: {result.content}")return {"messages": [response], "evaluator": result.content, "number": number_state}def decide_next_step(state: State):if state["evaluator"] == "yes":return ENDelse:return "agregate_1_node"# Start to build the graphgraph_builder = StateGraph(State)# Add nodes to the graphgraph_builder.add_node("agregate_1_node", agregate_1)graph_builder.add_node("evaluator_node", evaluator)# Add edgesgraph_builder.add_edge(START, "agregate_1_node")graph_builder.add_edge("agregate_1_node", "evaluator_node")graph_builder.add_conditional_edges("evaluator_node",decide_next_step,{"agregate_1_node": "agregate_1_node",END: END})# Compile the graphgraph = graph_builder.compile()# Display the graphtry:display(Image(graph.get_graph().draw_mermaid_png()))except Exception as e:print(f"Error al visualizar el grafo: {e}")Copied
<IPython.core.display.Image object>
from langchain_core.messages import HumanMessageprompt = "Start the process with the number 1"messages = [HumanMessage(content=prompt)]result = graph.invoke({"messages": messages}, {"number": None})for message in result["messages"]:message.pretty_print()Copied
================================ Human Message =================================Start the process with the number 1================================== Ai Message ==================================[Agregator] --> The number is 1 and the next number is 2================================== Ai Message ==================================[Evaluator] --> Is the following number 2 equal to 10? Result: no================================== Ai Message ==================================[Agregator] --> The number is 2 and the next number is 3================================== Ai Message ==================================[Evaluator] --> Is the following number 3 equal to 10? Result: no================================== Ai Message ==================================[Agregator] --> The number is 3 and the next number is 4================================== Ai Message ==================================[Evaluator] --> Is the following number 4 equal to 10? Result: no================================== Ai Message ==================================[Agregator] --> The number is 4 and the next number is 5================================== Ai Message ==================================[Evaluator] --> Is the following number 5 equal to 10? Result: no================================== Ai Message ==================================[Agregator] --> The number is 5 and the next number is 6================================== Ai Message ==================================[Evaluator] --> Is the following number 6 equal to 10? Result: no================================== Ai Message ==================================[Agregator] --> The number is 6 and the next number is 7================================== Ai Message ==================================[Evaluator] --> Is the following number 7 equal to 10? Result: no================================== Ai Message ==================================[Agregator] --> The number is 7 and the next number is 8================================== Ai Message ==================================[Evaluator] --> Is the following number 8 equal to 10? Result: no================================== Ai Message ==================================[Agregator] --> The number is 8 and the next number is 9================================== Ai Message ==================================[Evaluator] --> Is the following number 9 equal to 10? Result: no================================== Ai Message ==================================[Agregator] --> The number is 9 and the next number is 10================================== Ai Message ==================================[Evaluator] --> Is the following number 10 equal to 10? Result: yes
Agente con herramientas (ReAct pattern)
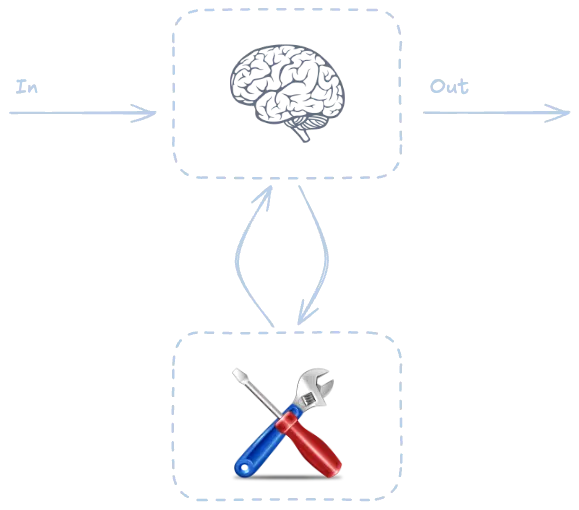
**Nota**: Este patrón lo voy a tener que resolver con Sonnet
Otra posibilidad es poder darle herramientas al agente
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langgraph.prebuilt import ToolNode, tools_conditionfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom langchain_anthropic import ChatAnthropicfrom langchain_core.messages import SystemMessage, HumanMessage, AIMessagefrom langchain_core.tools import toolfrom huggingface_hub import loginfrom IPython.display import Image, displayimport osos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracingimport dotenvdotenv.load_dotenv()ANTHROPIC_TOKEN = os.getenv("ANTHROPIC_LANGGRAPH_API_KEY")# Stateclass State(TypedDict):messages: Annotated[list, add_messages]# Tools@tooldef multiply(a: int, b: int) -> int:"""Multiply a and b.Args:a: first intb: second intReturns:The product of a and b."""return a * btools_list = [multiply]# Create the LLM modelllm = ChatAnthropic(model="claude-3-7-sonnet-20250219", api_key=ANTHROPIC_TOKEN)llm_with_tools = llm.bind_tools(tools_list)# Functiondef chatbot_function(state: State):system_message = "You are a helpful assistant that can use tools to answer questions. Once you have the result of a tool, provide a final answer without calling more tools."messages = [SystemMessage(content=system_message)] + state["messages"]return {"messages": [llm_with_tools.invoke(messages)]}# Start to build the graphgraph_builder = StateGraph(State)# Add nodes to the graphgraph_builder.add_node("chatbot_node", chatbot_function)tool_node = ToolNode(tools=tools_list)graph_builder.add_node("tools", tool_node)# Add edgesgraph_builder.add_edge(START, "chatbot_node")graph_builder.add_conditional_edges("chatbot_node", tools_condition)graph_builder.add_edge("tools", "chatbot_node")graph_builder.add_edge("chatbot_node", END)# Compile the graphgraph = graph_builder.compile()# Display the graphtry:display(Image(graph.get_graph().draw_mermaid_png()))except Exception as e:print(f"Error al visualizar el grafo: {e}")Copied
<IPython.core.display.Image object>
from langchain_core.messages import HumanMessageprompt = "Multiply 2 and 3"messages = [HumanMessage(content=prompt)]result = graph.invoke({"messages": messages}, {"number": None})for message in result["messages"]:message.pretty_print()Copied
================================ Human Message =================================Multiply 2 and 3================================== Ai Message ==================================[{'text': "I'll calculate the product of 2 and 3 for you using the multiply function.", 'type': 'text'}, {'id': 'toolu_01BEDxEjrJX51kGLfYENBEot', 'input': {'a': 2, 'b': 3}, 'name': 'multiply', 'type': 'tool_use'}]Tool Calls:multiply (toolu_01BEDxEjrJX51kGLfYENBEot)Call ID: toolu_01BEDxEjrJX51kGLfYENBEotArgs:a: 2b: 3================================= Tool Message =================================Name: multiply6================================== Ai Message ==================================The product of 2 and 3 is 6.
Planning pattern
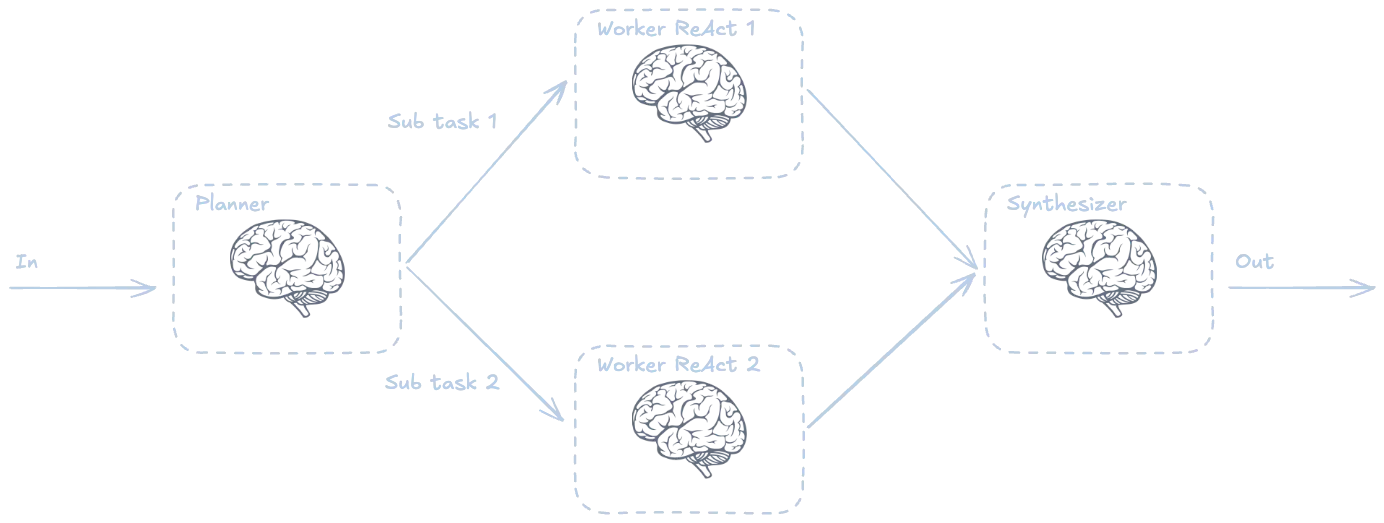
En este caso un LLM divide el problema en varias tareas y se las asigna a otros agentes, después otro LLM combina las respuestas de los agentes para dar una respuesta final. Vamos a ver el problema de resumir y traducir un texto.
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom langchain_core.messages import SystemMessage, HumanMessagefrom huggingface_hub import loginfrom IPython.display import Image, displayimport osos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracingimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")# Stateclass State(TypedDict):messages: Annotated[list, add_messages]text_to_summarize: strtext_to_translate: strsummary: strtranslation: str# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Functiondef planner_function(state: State):input_text = state["messages"][-1].contenttext_to_summarize = f"Summarize the following text: {input_text}"text_to_translate = f"Translate the following text to Spanish: {input_text}"return {"text_to_summarize": text_to_summarize,"text_to_translate": text_to_translate}def summary_function(state: State):input_text = state["text_to_summarize"]llm_response = llm.invoke(input_text)summary = llm_response.contentreturn {"messages": [llm_response], "summary": summary}def translate_function(state: State):input_text = state["text_to_translate"]llm_response = llm.invoke(input_text)translation = llm_response.contentreturn {"messages": [llm_response], "translation": translation}def aggregate_function(state: State):prompt = f"""Combine the following summary and translation into a single one:SUMMARY: {state['summary']}TRANSLATION: {state['translation']}"""llm_response = llm.invoke(prompt)return {"messages": [llm_response]}# Start to build the graphgraph_builder = StateGraph(State)# Add nodes to the graphgraph_builder.add_node("planner_node", planner_function)graph_builder.add_node("summary_node", summary_function)graph_builder.add_node("translate_node", translate_function)graph_builder.add_node("aggregate_node", aggregate_function)# Add edgesgraph_builder.add_edge(START, "planner_node")graph_builder.add_edge("planner_node", "summary_node")graph_builder.add_edge("planner_node", "translate_node")graph_builder.add_edge("summary_node", "aggregate_node")graph_builder.add_edge("translate_node", "aggregate_node")graph_builder.add_edge("aggregate_node", END)# Compile the graphgraph = graph_builder.compile()# Display the graphtry:display(Image(graph.get_graph().draw_mermaid_png()))except Exception as e:print(f"Error al visualizar el grafo: {e}")Copied
<IPython.core.display.Image object>
from langchain_core.messages import HumanMessagetext = """Large language models are powerful AI systems trained on vast amounts of text data.They can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in an informative way."""messages = [HumanMessage(content=text)]result = graph.invoke({"messages": messages})for message in result["messages"]:message.pretty_print()Copied
================================ Human Message =================================Large language models are powerful AI systems trained on vast amounts of text data.They can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in an informative way.================================== Ai Message ==================================Large language models are advanced AI systems trained on extensive text data. These models can produce text that resembles human writing, translate between languages, create various types of creative content, and provide informative answers to questions.================================== Ai Message ==================================Los grandes modelos de lenguaje son potentes sistemas de IA entrenados con enormes cantidades de datos de texto. Pueden generar texto similar al humano, traducir idiomas, escribir diversos tipos de contenido creativo y responder tus preguntas de manera informativa.================================== Ai Message ==================================Los grandes modelos de lenguaje son potentes sistemas de IA entrenados con enormes cantidades de datos de texto. Estos modelos pueden generar texto similar al humano, traducir entre idiomas, crear diversos tipos de contenido creativo y proporcionar respuestas informativas a tus preguntas.
Multi agent pattern
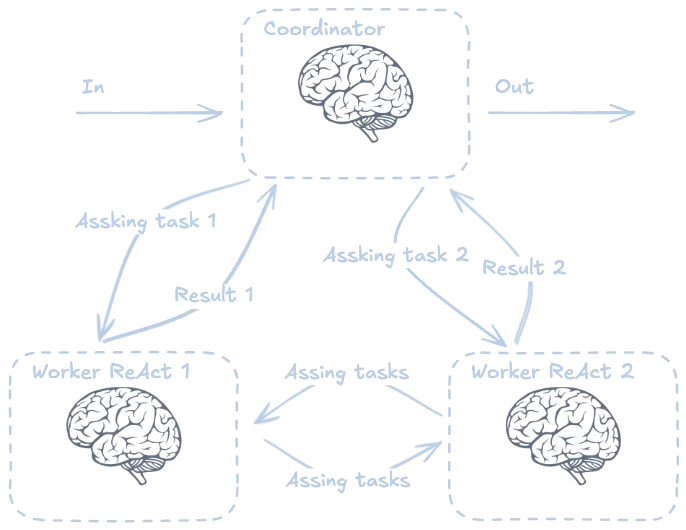
En este caso tenemos un agente coordinador que se encarga de asignar tareas a los agentes. Además, los agentes se pueden pedir tareas entre ellos
Este sería un posible flujo de trabajo:
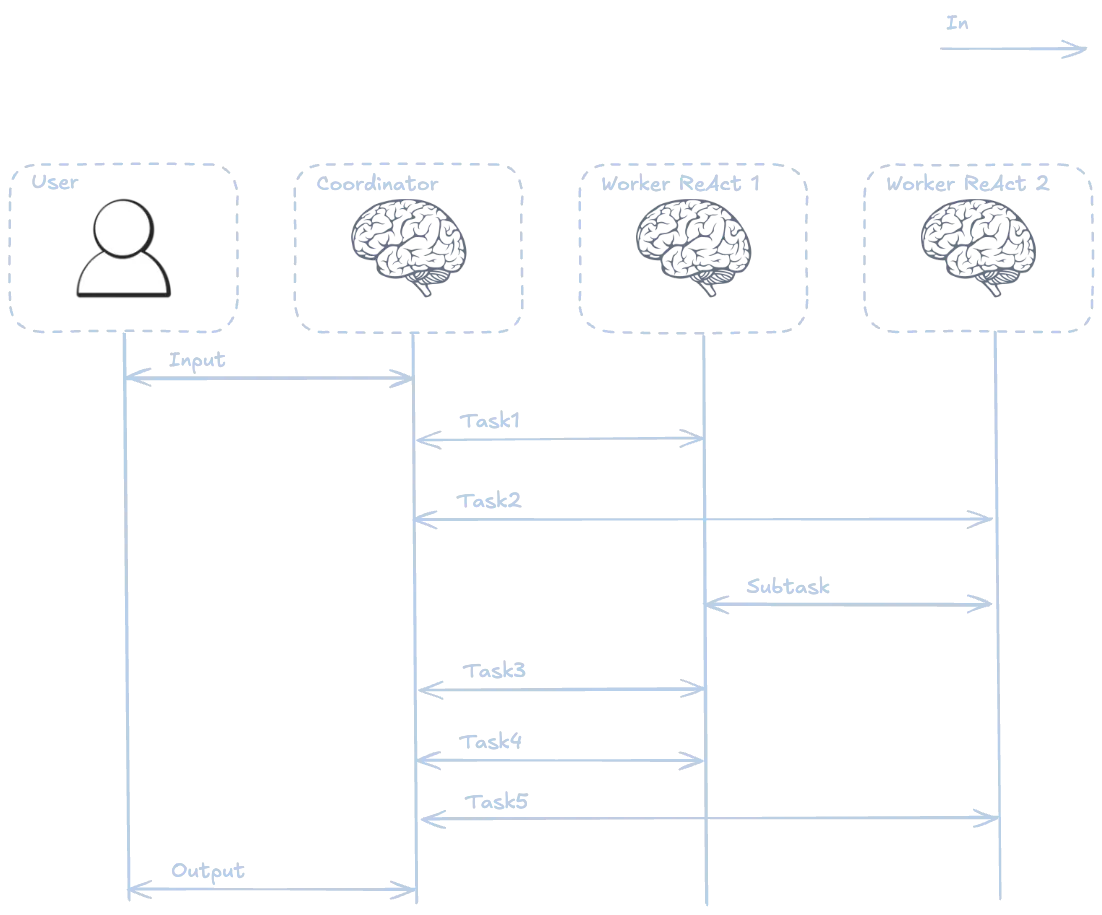
Vamos a hacer un pequeño deep researcher
Worker 1: Agente buscador de noticias
Creamos el primer worker, un agente que se encarga de buscar en internet y generar amplios informes, le pido más de 200 palabras. Además, le voy a crear un checkpoint, para que tenga contexto de lo que ya ha buscado.
from typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom huggingface_hub import loginfrom langchain_community.utilities.tavily_search import TavilySearchAPIWrapperfrom langchain_community.tools.tavily_search import TavilySearchResultsfrom langchain_core.messages import SystemMessage, ToolMessagefrom langgraph.prebuilt import ToolNode, tools_conditionfrom langgraph.checkpoint.memory import MemorySaverfrom IPython.display import Image, displayimport osos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracingimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")TAVILY_API_KEY = os.getenv("TAVILY_LANGGRAPH_API_KEY")# Stateclass State_searcher(TypedDict):messages: Annotated[list, add_messages]# Toolswrapper = TavilySearchAPIWrapper(tavily_api_key=TAVILY_API_KEY)tool_search = TavilySearchResults(api_wrapper=wrapper, max_results=10)tools_searcher_list = [tool_search]# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model_searcher = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm_searcher = ChatHuggingFace(llm=model_searcher)# Create the LLM with toolsllm_searcher_with_tools = llm_searcher.bind_tools(tools_searcher_list)# Tool nodetool_searcher_node = ToolNode(tools=tools_searcher_list)# Functionsdef searcher_function(state: State_searcher):# Check if the last message is a ToolMessageif state["messages"] and isinstance(state["messages"][-1], ToolMessage):# If it is, it means the tool has run, so we pass the messages as they are.return {"messages": state["messages"]}system_prompt = """You are a helpful assistant.Your task is to decide if you need to search the web for information based on the user's query.If you need to search the web, invoke the available search tool.Do NOT process or summarize the search results. Simply return the raw output from the search tool.If you don't need to search, respond to the user directly.The document must to have more than 200 words."""messages = [SystemMessage(content=system_prompt)] + state["messages"]return {"messages": [llm_searcher_with_tools.invoke(messages)]}# Start to build the graphgraph_searcher = StateGraph(State_searcher)# Add nodes to the graphgraph_searcher.add_node("searcher_node", searcher_function)graph_searcher.add_node("tools", tool_searcher_node)# Add edgesgraph_searcher.add_edge(START, "searcher_node")graph_searcher.add_conditional_edges( "searcher_node", tools_condition)graph_searcher.add_edge("tools", "searcher_node")# Compile the graphmemory_searcher = MemorySaver()graph_searcher_compiled = graph_searcher.compile(checkpointer=memory_searcher)# Display the graphtry:display(Image(graph_searcher_compiled.get_graph().draw_mermaid_png()))except Exception as e:print(f"Error al visualizar el grafo: {e}")Copied
<IPython.core.display.Image object>
Vamos a probarlo, le voy a pedir los finalistas de la Champions League de este año (2025), que lógicamente no está en el conocimiento del LLM
from langchain_core.messages import HumanMessageUSER1_THREAD_ID = "1"config_USER1 = {"configurable": {"thread_id": USER1_THREAD_ID}}prompt = "Who are the Champions League 2025 finalists?"messages = [HumanMessage(content=prompt)]result_searcher = graph_searcher_compiled.invoke({"messages": messages}, config=config_USER1)for message in result_searcher["messages"]:message.pretty_print()Copied
================================ Human Message =================================Who are the Champions League 2025 finalists?================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: Champions League 2025 finalists================================= Tool Message =================================Name: tavily_search_results_json[{"title": "2025 UEFA Champions League final: Munich Football Arena", "url": "https://www.uefa.com/uefachampionsleague/news/0283-186742eb3c74-d5eb4afca229-1000--2025-uefa-champions-league-final-munich-football-arena/", "content": "2024/25 Champions League final date The 2025 Champions League final between Paris and Inter takes place on Saturday 31 May 2025. It will be culmination of the 70th season of Europe's elite club competition and the 33rd since it was renamed the UEFA Champions League. What do the Champions League winners get? [...] MoreTeamsNew formatNewsFinalHistorySeasonsAll-time statsVideoTeamsMost titlesAboutStore Favourite team UEFA Champions League - 2025 UEFA Champions League final: Munich Football Arena - News Go back 2025 UEFA Champions League final: Munich Football Arena Wednesday, May 7, 2025 Article summary The 2024/25 UEFA Champions League final between Paris and Inter will take place at the Munich Football Arena. Article top media content [...] Your custom access to: and much more! Your custom access to: and much more! We Care About Your Privacy", "score": 0.8825193}, {"title": "2025 UEFA Champions League final: All you need to know", "url": "https://www.uefa.com/uefachampionsleague/news/0296-1d2ab6f54da7-c43a66bc7b77-1000--2025-uefa-champions-league-final-all-you-need-to-know/", "content": "UEFA.com works better on other browsers For the best possible experience, we recommend using Chrome, Firefox or Microsoft Edge. Skip to main content UEFA Champions League Favourite team UEFA Champions League - 2025 UEFA Champions League final: All you need to know - News 2025 UEFA Champions League final: All you need to know Wednesday, May 7, 2025 Article summary The 2024/25 UEFA Champions League final between Paris and Inter will take place at the Munich Football Arena. [...] Paris will face Inter in the final. Inter were the first side to book their place in the decider courtesy of their incredible 7-6 aggregate victory over Barcelona in the semi-finals. The following night, Paris joined them thanks to a 3-1 overall success against Arsenal. Barcelona vs Inter: Every goal from the epic semi-final Where is the 2025 Champions League final? [...] Live 09/05/2025 Olympiacos earn automatic place in 2025/26 league phase thanks to Champions League rebalancing ---------------------------------------------------------------------------------------------- Olympiacos have earned a league phase spot next season since UEFA Champions League finalists Paris and Inter have already qualified via their domestic league position. Who will perform before the Champions League final?", "score": 0.82694983}, {"title": "Champions League final: Paris vs Inter – meet the teams - UEFA.com", "url": "https://www.uefa.com/uefachampionsleague/news/0299-1db3ed7babb3-e6227af6104f-1000--champions-league-final-paris-vs-inter-meet-the-teams/", "content": "MoreTeamsNew formatNewsFinalHistorySeasonsAll-time statsVideoTeamsMost titlesAboutStore Favourite team UEFA Champions League - Champions League final: Paris vs Inter – meet the teams - News Go back Champions League final: Paris vs Inter – meet the teams Wednesday, May 7, 2025 Article summary Pivotal players, season so far, key stats; all you need to know about 2024/25 UEFA Champions League finalists Paris and Inter. Article top media content [...] Published Time: 5/7/2025 9:51:00 PM +00:00 Champions League final: Paris vs Inter – meet the teams | UEFA Champions League | UEFA.com Champions League Official Live football scores & Fantasy Get UEFA.com works better on other browsers For the best possible experience, we recommend using Chrome, Firefox or Microsoft Edge. Skip to main content UEFA.com Home About National associations Running competitions Development Sustainability News & media [...] Paris are the third French team to reach the final of the European Cup/UEFA Champions League more than once after Reims (1955/56, 1958/59) and Marseille (1990/91, 1992/93). All Paris' 2024/25 Champions League goals © 1998-2025 UEFA. All rights reserved. Last updated: Wednesday, May 7, 2025 UEFA Champions League", "score": 0.8190992}, {"title": "2025 Champions League semi-finals: matchups, bracket and dates ...", "url": "https://en.as.com/soccer/2025-champions-league-semi-finals-matchups-bracket-and-dates-of-the-games-n/", "content": "3:00 p.m. ET: Arsenal vs Paris Saint-Germain Wednesday, April 30: 3:00 p.m. ET: Barcelona vs Inter Milan Second legs: Tuesday, May 6: 3:00 p.m. ET: Inter Milan vs Barcelona Wednesday, May 7: 3:00 p.m. ET: Paris Saint-Germain vs Arsenal When and where is the 2025 Champions League final? The final is to be played at the Allianz Arena in Munich, Germany, on May 31. Related stories [...] Aston Villa 3-2 Paris Saint-Germain (4-5 on aggregate) Borussia Dortmund 3-1 Barcelona (3-5 on aggregate) Inter Milan 2-2 Bayern Munich (4-3 on aggregate) Real Madrid 1-2 Arsenal (1-5 on aggregate) Champions League bracket: When are the UCL semi-finals? The first legs of the Champions League semi-finals are due to be played on April 29 and 30. The second legs are scheduled for May 6 and 7. UCL semi-finals - schedule in full: First legs: Tuesday, April 29: [...] Fútbol Champions League Arsenal FC FC Barcelona PSG Inter Milan Comments0Rules Comments Rules Sign in to commentAlready have an account Complete your personal details to comment Complete data Your opinion will be published with first and last names We recommend these for you in Soccer", "score": 0.8051581}, {"title": "2025 UEFA Champions League final - Simple Wikipedia", "url": "https://simple.wikipedia.org/wiki/2025_UEFA_Champions_League_final", "content": "The 2025 UEFA Champions League final will be a match of the 2024–25 season, Europe's top club football tournament. It's the 70th season, and they changed the name to UEFA Champions League 33 seasons ago. The final will happen on May 31, 2025, at Allianz Arena in Munich, Germany.[1] It's the first final with the new Swiss-system format.[2] The winners will face the Europa League winners in the 2025 UEFA Super Cup. Match [change | change source] Details [change | change source] [...] Appearance move to sidebar hide From Simple English Wikipedia, the free encyclopedia 2025 UEFA Champions League finalThe Allianz Arena in Germany will host the final.Event2024–25 UEFA Champions LeagueDate31 May 2025 (2025-05-31)VenueAllianz Arena, Munich← 20242026 → [...] Contents move to sidebar hide Beginning 1 MatchToggle Match subsection 1.1 Details 2 References 3 Other websites Toggle the table of contents 2025 UEFA Champions League final 22 languages العربية বাংলা Cymraeg Dansk English Español فارسی Français Bahasa Indonesia עברית Қазақша Bahasa Melayu 日本語 Português Română Русский Српски / srpski ไทย Türkçe Українська Tiếng Việt 中文 Change links Page Talk English Read Change Change source View history", "score": 0.8005209}, {"title": "UEFA Women's Champions League 2025 Final Full Match - YouTube", "url": "https://www.youtube.com/watch?v=xlf3HrJ35R4", "content": "May 24, 2025 -- Arsenal vs. Barcelona | UEFA Women's Champions League Final 2025. DAZN is proud to present a New Deal for women's football!", "score": 0.7206637}, {"title": "Europe's top soccer leagues: Titles, cup finals, UCL, relegation - ESPN", "url": "https://www.espn.com/soccer/story/_/id/44835154/europe-top-soccer-leagues-whats-was-decided-premier-league-laliga-bundesliga-serie-ligue-1", "content": "| GP | PTS | GD 1 - Liverpool | 38 | 84 | +45 2 - Arsenal | 38 | 74 | +35 3 - Man City | 38 | 71 | +28 4 - Chelsea | 38 | 69 | +21 5 - Newcastle | 38 | 66 | +21 6 - Aston Villa | 38 | 66 | +7 7 - Nottm Forest | 38 | 65 | +12 In 2025-26, the Premier League has been allocated five teams in the Champions League due to the performance of its clubs in Europe this season, meaning the top five will qualify for the UCL. Liverpool and Arsenal (71) have booked two of them.", "score": 0.6496014}]
Nos ha devuelto una lista de resultados de la búsqueda, ahora vamos a sintetizarla.
Worker 2: agente sintetizador de noticias
Ahora creamos el segundo worker, un agente que se encarga de sintetizar la información de los informes de los otros agentes.
# Stateclass State_summarizer(TypedDict):messages: Annotated[list, add_messages]decision: str# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model_summarizer = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm_summarizer = ChatHuggingFace(llm=model_summarizer)# Functionsdef summarizer_function(state: State_summarizer):system_prompt = """You are an advanced AI assistant specialized in summarizing complex information from multiple documents.Your task is to process a list of provided documents (typically search results) and generate a comprehensive yet concise summary.Key objectives for your summary:1. **Accuracy:** Ensure all information is derived strictly from the provided documents. Do not infer or add external knowledge.2. **Relevance:** Focus on the most important facts, findings, and answers related to the core topic of the documents.3. **Clarity:** Write in clear, precise, and easily understandable language. Define any jargon if present in the source and necessary for understanding.4. **Structure:** Organize the summary logically. Use paragraphs to separate distinct ideas. If helpful for the content, consider using bullet points for lists of key facts or findings.5. **Conciseness:** Be thorough but avoid unnecessary repetition or overly verbose phrasing. Capture the essence efficiently.6. **Neutrality:** Maintain an objective tone.Synthesize the information into a coherent piece that gives a full picture of what the documents collectively state about the topic.""" # End of the new system_promptmessages = [SystemMessage(content=system_prompt)] + state["messages"]summarizer_result = llm_summarizer.invoke(messages)return {"messages": [summarizer_result]}def check_summarizer_result(state: State_summarizer):system_prompt = """You are a critical reviewer AI, tasked with validating text summaries against specific quality criteria.You will receive an original text and a summary generated from it. The summary was intended to meet the following objectives:- Accuracy (derived strictly from the original, no external knowledge).- Relevance (focus on most important facts related to the core topic).- Clarity (clear, precise, easily understandable language).- Good Structure (logically organized, paragraphs/bullets if appropriate).- Conciseness (thorough but not verbose).- Neutrality (objective tone).Carefully compare the summary against the original text.If the summary successfully meets ALL the above objectives, return the single word "good".If the summary fails to meet one or more of these objectives adequately, return the single word "bad".Provide only "good" or "bad" as your response.""" # End of new system_prompttext_to_summarize = state["messages"][-2].contentsummarizer_result = state["messages"][-1].contentprompt = f"""Here is the summary:{summarizer_result}And here is the original text:{text_to_summarize}Please, return only one word, "good" or "bad"."""messages = [SystemMessage(content=system_prompt)] + [HumanMessage(content=prompt)]decision = llm_summarizer.invoke(messages)return {"decision": decision.content}# Start to build the graphgraph_summarizer = StateGraph(State_summarizer)# Add nodes to the graphgraph_summarizer.add_node("summarizer_node", summarizer_function)graph_summarizer.add_node("check_summarizer_result", check_summarizer_result)# Add edgesgraph_summarizer.add_edge(START, "summarizer_node")graph_summarizer.add_edge("summarizer_node", "check_summarizer_result")graph_summarizer.add_conditional_edges(source="check_summarizer_result",path=lambda state: state["decision"],path_map={"good": END,"bad": "summarizer_node"})# Compile the graphmemory_summarizer = MemorySaver()graph_summarizer_compiled = graph_summarizer.compile(checkpointer=memory_summarizer)# Display the graphtry:display(Image(graph_summarizer_compiled.get_graph().draw_mermaid_png()))except Exception as e:print(f"Error al visualizar el grafo: {e}")Copied
<IPython.core.display.Image object>
Vamos a probarlo, le voy a pasar el resultado del primer worker para ver cómo lo sintetiza.
search_result = result_searcher["messages"][-1].contentmessages = [HumanMessage(content=search_result)]result_sumarizer = graph_summarizer_compiled.invoke({"messages": messages}, config=config_USER1)for message in result_sumarizer["messages"]:message.pretty_print()print(" Decision on Summary:")decision = result_sumarizer.get("decision")if decision:print(decision)else:print("No decision was found.")print("--- End of Summarizer Graph Output ---")Copied
================================ Human Message =================================[{"title": "2025 UEFA Champions League final: Munich Football Arena", "url": "https://www.uefa.com/uefachampionsleague/news/0283-186742eb3c74-d5eb4afca229-1000--2025-uefa-champions-league-final-munich-football-arena/", "content": "2024/25 Champions League final date The 2025 Champions League final between Paris and Inter takes place on Saturday 31 May 2025. It will be culmination of the 70th season of Europe's elite club competition and the 33rd since it was renamed the UEFA Champions League. What do the Champions League winners get? [...] MoreTeamsNew formatNewsFinalHistorySeasonsAll-time statsVideoTeamsMost titlesAboutStore Favourite team UEFA Champions League - 2025 UEFA Champions League final: Munich Football Arena - News Go back 2025 UEFA Champions League final: Munich Football Arena Wednesday, May 7, 2025 Article summary The 2024/25 UEFA Champions League final between Paris and Inter will take place at the Munich Football Arena. Article top media content [...] Your custom access to: and much more! Your custom access to: and much more! We Care About Your Privacy", "score": 0.8825193}, {"title": "2025 UEFA Champions League final: All you need to know", "url": "https://www.uefa.com/uefachampionsleague/news/0296-1d2ab6f54da7-c43a66bc7b77-1000--2025-uefa-champions-league-final-all-you-need-to-know/", "content": "UEFA.com works better on other browsers For the best possible experience, we recommend using Chrome, Firefox or Microsoft Edge. Skip to main content UEFA Champions League Favourite team UEFA Champions League - 2025 UEFA Champions League final: All you need to know - News 2025 UEFA Champions League final: All you need to know Wednesday, May 7, 2025 Article summary The 2024/25 UEFA Champions League final between Paris and Inter will take place at the Munich Football Arena. [...] Paris will face Inter in the final. Inter were the first side to book their place in the decider courtesy of their incredible 7-6 aggregate victory over Barcelona in the semi-finals. The following night, Paris joined them thanks to a 3-1 overall success against Arsenal. Barcelona vs Inter: Every goal from the epic semi-final Where is the 2025 Champions League final? [...] Live 09/05/2025 Olympiacos earn automatic place in 2025/26 league phase thanks to Champions League rebalancing ---------------------------------------------------------------------------------------------- Olympiacos have earned a league phase spot next season since UEFA Champions League finalists Paris and Inter have already qualified via their domestic league position. Who will perform before the Champions League final?", "score": 0.82694983}, {"title": "Champions League final: Paris vs Inter – meet the teams - UEFA.com", "url": "https://www.uefa.com/uefachampionsleague/news/0299-1db3ed7babb3-e6227af6104f-1000--champions-league-final-paris-vs-inter-meet-the-teams/", "content": "MoreTeamsNew formatNewsFinalHistorySeasonsAll-time statsVideoTeamsMost titlesAboutStore Favourite team UEFA Champions League - Champions League final: Paris vs Inter – meet the teams - News Go back Champions League final: Paris vs Inter – meet the teams Wednesday, May 7, 2025 Article summary Pivotal players, season so far, key stats; all you need to know about 2024/25 UEFA Champions League finalists Paris and Inter. Article top media content [...] Published Time: 5/7/2025 9:51:00 PM +00:00 Champions League final: Paris vs Inter – meet the teams | UEFA Champions League | UEFA.com Champions League Official Live football scores & Fantasy Get UEFA.com works better on other browsers For the best possible experience, we recommend using Chrome, Firefox or Microsoft Edge. Skip to main content UEFA.com Home About National associations Running competitions Development Sustainability News & media [...] Paris are the third French team to reach the final of the European Cup/UEFA Champions League more than once after Reims (1955/56, 1958/59) and Marseille (1990/91, 1992/93). All Paris' 2024/25 Champions League goals © 1998-2025 UEFA. All rights reserved. Last updated: Wednesday, May 7, 2025 UEFA Champions League", "score": 0.8190992}, {"title": "2025 Champions League semi-finals: matchups, bracket and dates ...", "url": "https://en.as.com/soccer/2025-champions-league-semi-finals-matchups-bracket-and-dates-of-the-games-n/", "content": "3:00 p.m. ET: Arsenal vs Paris Saint-Germain Wednesday, April 30: 3:00 p.m. ET: Barcelona vs Inter Milan Second legs: Tuesday, May 6: 3:00 p.m. ET: Inter Milan vs Barcelona Wednesday, May 7: 3:00 p.m. ET: Paris Saint-Germain vs Arsenal When and where is the 2025 Champions League final? The final is to be played at the Allianz Arena in Munich, Germany, on May 31. Related stories [...] Aston Villa 3-2 Paris Saint-Germain (4-5 on aggregate) Borussia Dortmund 3-1 Barcelona (3-5 on aggregate) Inter Milan 2-2 Bayern Munich (4-3 on aggregate) Real Madrid 1-2 Arsenal (1-5 on aggregate) Champions League bracket: When are the UCL semi-finals? The first legs of the Champions League semi-finals are due to be played on April 29 and 30. The second legs are scheduled for May 6 and 7. UCL semi-finals - schedule in full: First legs: Tuesday, April 29: [...] Fútbol Champions League Arsenal FC FC Barcelona PSG Inter Milan Comments0Rules Comments Rules Sign in to commentAlready have an account Complete your personal details to comment Complete data Your opinion will be published with first and last names We recommend these for you in Soccer", "score": 0.8051581}, {"title": "2025 UEFA Champions League final - Simple Wikipedia", "url": "https://simple.wikipedia.org/wiki/2025_UEFA_Champions_League_final", "content": "The 2025 UEFA Champions League final will be a match of the 2024–25 season, Europe's top club football tournament. It's the 70th season, and they changed the name to UEFA Champions League 33 seasons ago. The final will happen on May 31, 2025, at Allianz Arena in Munich, Germany.[1] It's the first final with the new Swiss-system format.[2] The winners will face the Europa League winners in the 2025 UEFA Super Cup. Match [change | change source] Details [change | change source] [...] Appearance move to sidebar hide From Simple English Wikipedia, the free encyclopedia 2025 UEFA Champions League finalThe Allianz Arena in Germany will host the final.Event2024–25 UEFA Champions LeagueDate31 May 2025 (2025-05-31)VenueAllianz Arena, Munich← 20242026 → [...] Contents move to sidebar hide Beginning 1 MatchToggle Match subsection 1.1 Details 2 References 3 Other websites Toggle the table of contents 2025 UEFA Champions League final 22 languages العربية বাংলা Cymraeg Dansk English Español فارسی Français Bahasa Indonesia עברית Қазақша Bahasa Melayu 日本語 Português Română Русский Српски / srpski ไทย Türkçe Українська Tiếng Việt 中文 Change links Page Talk English Read Change Change source View history", "score": 0.8005209}, {"title": "UEFA Women's Champions League 2025 Final Full Match - YouTube", "url": "https://www.youtube.com/watch?v=xlf3HrJ35R4", "content": "May 24, 2025 -- Arsenal vs. Barcelona | UEFA Women's Champions League Final 2025. DAZN is proud to present a New Deal for women's football!", "score": 0.7206637}, {"title": "Europe's top soccer leagues: Titles, cup finals, UCL, relegation - ESPN", "url": "https://www.espn.com/soccer/story/_/id/44835154/europe-top-soccer-leagues-whats-was-decided-premier-league-laliga-bundesliga-serie-ligue-1", "content": "| GP | PTS | GD 1 - Liverpool | 38 | 84 | +45 2 - Arsenal | 38 | 74 | +35 3 - Man City | 38 | 71 | +28 4 - Chelsea | 38 | 69 | +21 5 - Newcastle | 38 | 66 | +21 6 - Aston Villa | 38 | 66 | +7 7 - Nottm Forest | 38 | 65 | +12 In 2025-26, the Premier League has been allocated five teams in the Champions League due to the performance of its clubs in Europe this season, meaning the top five will qualify for the UCL. Liverpool and Arsenal (71) have booked two of them.", "score": 0.6496014}]================================== Ai Message ==================================### Summary of the 2025 UEFA Champions League Final#### Final Details- **Date:** Saturday, 31 May 2025- **Venue:** Allianz Arena, Munich, Germany- **Teams:** Paris Saint-Germain (Paris) vs. Inter Milan (Inter)- **Significance:** This will be the culmination of the 70th season of Europe's elite club competition and the 33rd since it was renamed the UEFA Champions League. It will also be the first final under the new Swiss-system format.#### Path to the Final- **Semi-final Matches:**- **First Legs:**- Tuesday, April 29: Barcelona vs. Inter Milan- Wednesday, April 30: Arsenal vs. Paris Saint-Germain- **Second Legs:**- Tuesday, May 6: Inter Milan vs. Barcelona- Wednesday, May 7: Paris Saint-Germain vs. Arsenal- **Semi-final Results:**- **Inter Milan:** Aggregated 7-6 victory over Barcelona- **Paris Saint-Germain:** Aggregated 3-1 victory over Arsenal#### Team Backgrounds- **Paris Saint-Germain:**- Third French team to reach the final of the European Cup/UEFA Champions League more than once, following Reims and Marseille.- Had a strong run, defeating Arsenal convincingly in the semi-finals.- **Inter Milan:**- Booked their place in the final with an epic 7-6 aggregate victory over Barcelona.- Known for their resilience and attacking prowess.#### Additional Information- **Pre-Final Performances:**- Inter's victory over Barcelona included a dramatic comeback, highlighting their strength and determination.- Paris Saint-Germain's consistent performance and tactical discipline were key in their semi-final win.- **Impact on European Leagues:**- Due to the performance of clubs in Europe, the Premier League has been allocated five teams in the 2025-26 UEFA Champions League, with Liverpool and Arsenal securing two of the spots.- **Pre-Final Event:**- There will be a performance before the Champions League final, though the artist or act has not been specified as of the latest update.This final promises to be an exciting culmination of the season, showcasing the best of European club football.Decision on Summary:good--- End of Summarizer Graph Output ---
Vemos que ha hecho un resumen de las noticias
Grafo principal
Una vez tenemos los dos workers, podemos construir el grafo principal.
# Entry Graphclass State_agent_pattern(TypedDict):messages: Annotated[list, add_messages] # Holds all messages: user query, tool calls/results, summariesagent_decision: str # Routing: "route_to_searcher", "route_to_summarizer", "route_to_end"# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model_agent_pattern = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm_agent_pattern = ChatHuggingFace(llm=model_agent_pattern)# Functionsdef decision_function(state: State_agent_pattern) -> dict:"""Decides the next action for the agent based on the current state of messages.Updates 'agent_decision' to route to the searcher, summarizer, or end the process."""current_messages = state.get("messages", [])next_route = "route_to_searcher" # Default actionif not current_messages:print("Warning: decision_function called with empty messages. Defaulting to search.")return {"agent_decision": "route_to_searcher"}last_message = current_messages[-1]if isinstance(last_message, ToolMessage):# Search results are available (ToolMessage). Next step: summarize.next_route = "route_to_summarizer"elif isinstance(last_message, AIMessage):# AIMessage could be a direct answer from searcher or a summary from summarizer.ai_content = getattr(last_message, 'content', "").strip()if not ai_content:print("Warning: AIMessage has no content. Defaulting to search.")next_route = "route_to_searcher"else:# Use LLM to evaluate the AIMessage contentsystem_prompt_eval = """You are an expert content analyst.Analyze the provided text. The text could be a direct answer to a query or a summary.- If the text is a comprehensive and sufficient final answer, respond with "enough".- If the text seems like raw search results that were not properly captured as a ToolMessage but as an AIMessage, or requires summarization, respond with "needs_summary".- If the text is a summary, but it's insufficient and more searching/refinement is needed, respond with "search_again".Respond with only one of: "enough", "needs_summary", "search_again"."""eval_messages = [SystemMessage(content=system_prompt_eval),HumanMessage(content=ai_content)]try:llm_eval_decision_obj = llm_agent_pattern.invoke(eval_messages)eval_decision_str = llm_eval_decision_obj.content.strip().lower()if eval_decision_str == "enough":next_route = "route_to_end"elif eval_decision_str == "needs_summary":next_route = "route_to_summarizer"elif eval_decision_str == "search_again":next_route = "route_to_searcher"else:print(f"Warning: LLM in decision_function (AIMessage eval) returned: '{eval_decision_str}'. Defaulting to end.")next_route = "route_to_end" # Safer default for unrecognized LLM outputexcept Exception as e:print(f"Error during LLM call in decision_function: {e}. Defaulting to search.")next_route = "route_to_searcher"elif isinstance(last_message, HumanMessage):# Initial user query or a follow-up. Start by searching.next_route = "route_to_searcher"else:print(f"Warning: decision_function encountered an unexpected last message type: {type(last_message)}. Defaulting to search.")next_route = "route_to_searcher"return {"agent_decision": next_route}# Build the graphagent_pattern_builder = StateGraph(State_agent_pattern)# Add nodesagent_pattern_builder.add_node("decision_node", decision_function)agent_pattern_builder.add_node("searcher_node", graph_searcher.compile())agent_pattern_builder.add_node("summarizer_node", graph_summarizer.compile())# Add edgesagent_pattern_builder.add_edge(START, "decision_node")agent_pattern_builder.add_conditional_edges(source="decision_node",path=lambda state: state["agent_decision"],path_map={"route_to_searcher": "searcher_node","route_to_summarizer": "summarizer_node","route_to_end": END})# Edges to loop back to the decision node after search or summarizationagent_pattern_builder.add_edge("searcher_node", "decision_node")agent_pattern_builder.add_edge("summarizer_node", "decision_node")# Compile the graphgraph_agent_pattern = agent_pattern_builder.compile()# Setting xray to 1 will show the internal structure of the nested graphtry:display(Image(graph_agent_pattern.get_graph(xray=1).draw_mermaid_png()))except Exception as e:print(f"Error al visualizar el grafo: {e}")Copied
<IPython.core.display.Image object>
Vamos a probarlo preguntando por Jules un agente de codificación asíncrono que ha salido hace una semana (a fecha de escritura del post), por lo que obviamente no debería estar en el conocimiento del LLM.
from langchain_core.messages import HumanMessage, AIMessageUSER2_THREAD_ID = "2"config_USER2 = {"configurable": {"thread_id": USER2_THREAD_ID}}prompt = "Can you explain me what is Jules asyncronous coding agent?"messages = [HumanMessage(content=prompt)]result_agent_pattern = graph_agent_pattern.invoke({"messages": messages}, config=config_USER2)for message in result_agent_pattern["messages"]:message.pretty_print()Copied
================================ Human Message =================================Can you explain me what is Jules asyncronous coding agent?================================== Ai Message ==================================Tool Calls:tavily_search_results_json (0)Call ID: 0Args:query: Jules asynchronous coding agent================================= Tool Message =================================Name: tavily_search_results_json[{"title": "Build with Jules, your asynchronous coding agent - Google Blog", "url": "https://blog.google/technology/google-labs/jules/", "content": "Today, Jules is entering public beta, available to everyone. No waitlist. Worldwide, everywhere where the Gemini model is available. What is Jules? Jules is an asynchronous, agentic coding assistant that integrates directly with your existing repositories. It clones your codebase into a secure Google Cloud virtual machine (VM), understands the full context of your project, and performs tasks such as: [...] Google's Jules coding agent is now in public beta. Jules autonomously reads your code performs tasks like writing tests and fixing bugs. It works asynchronously in a secure cloud environment and offers features like audio changelogs and GitHub integration. Summaries were generated by Google AI. Generative AI is experimental. Share TwitterFacebookLinkedInMail Copy link [...] Subscribe Breadcrumb 1. 2. Technology 3. Google Labs Build with Jules, your asynchronous coding agent May 20, 2025 · 3 min read Share TwitterFacebookLinkedInMail Copy link Our autonomous coding agent, Jules, is now in public beta. Kathy Korevec Director, Product Management, Google Labs Read AI-generated summary General summary", "score": 0.91399205}, {"title": "Meet Jules: Google AI Coding Agent — Codex/Copilot Killer?", "url": "https://medium.com/@samarrana407/meet-jules-google-ai-coding-agent-codex-copilot-killer-bb9e38867436", "content": "The landscape of AI coding agents is currently experiencing explosive growth, with new tools emerging rapidly to assist developers. Among the latest and most intriguing entries is Google’s Jules, an AI agent they are specifically labeling as an “asynchronous coding agent.” This designation hints at a fundamental difference from some other AI tools we’ve seen, suggesting a potentially significant shift in how developers interact with AI assistants. [...] Jules, however, operates differently. It aligns more closely with the concept of autonomous coding agents like OpenAI’s Codex Agent (distinct from the model). The key distinction is the asynchronous nature. Instead of working interactively line-by-line, you assign Jules a specific, potentially complex coding task. The agent then takes ownership of that task, works on it independently in the background, and presents the completed work once it’s ready. This promises a step closer to the early [...] What Sets Jules Apart? Asynchronous vs. Interactive Agents Many developers are familiar with AI coding tools integrated directly into their IDEs, such as Cursor or Windsurf. These tools typically work alongside the developer in real-time, offering code suggestions, completing lines, or refactoring code as you type — essentially “babysitting” your IDE.", "score": 0.9051298}, {"title": "You can sign up for Google's AI coding tool Jules right now - Mashable", "url": "https://mashable.com/article/jules-google-ai-coding-tool-sign-up", "content": "According to a Google blog post, Jules is an "asynchronous, agentic coding assistant that integrates directly with your existing repositories. It clones your codebase into a secure Google Cloud virtual machine (VM), understands the full context of your project, and performs tasks." How to sign up for Jules right now To try Jules out for yourself, you can sign up at jules.google. Click "Try Jules" in the top right corner to create your own account.", "score": 0.8839694}, {"title": "Google releases its asynchronous Jules AI agent for coding - ZDNet", "url": "https://www.zdnet.com/article/google-releases-its-asynchronous-jules-ai-agent-for-coding-how-to-try-it-for-free/", "content": "Originally unveiled by Google Labs in December, Jules is positioned as a reliable, automated coding assistant that can manage a broad suite of time-consuming tasks on behalf of human users. The model is "asynchronous," which, in programming-speak, means it can start and work on tasks without having to wait for any single one of them to finish. Afterward, the model provides a full outline of the changes that were made to a user's code, providing clarity into its reasoning process. [...] Google releases its asynchronous Jules AI agent for coding - how to try it for free The race to deploy AI agents is heating up. At its annual I/O developer conference yesterday, Google announced that Jules, its new AI coding assistant, is now available worldwide in public beta. [...] As such, Jules offers some advanced coding capabilities. It can work directly within a user's codebase, for example, absorbing a project's full context and making decisions without the need for a sandbox (that is, a separate and controlled testing environment). It also integrates directly with GitHub, eliminating the need for developers to manually switch back and forth between coding platforms. Also: Gemini Pro 2.5 is a stunningly capable coding assistant - and a big threat to ChatGPT", "score": 0.86981434}, {"title": "Google Jules - Is this the end of Coding ? - YouTube", "url": "https://www.youtube.com/watch?v=2MjN1LpO60k", "content": "Google's new AI tool, Jules, is set to transform the coding landscape. As an asynchronous coding agent, Jules can autonomously handle tasks", "score": 0.8627572}, {"title": "Introducing Jules: An AI Coding Agent for GitHub - LinkedIn", "url": "https://www.linkedin.com/posts/shubhamsaboo_google-just-released-an-asynchronous-ai-coding-activity-7331143519350231040-JIyG", "content": "Google just released an Asynchronous AI Coding Agent...🤯 Powered by Gemini, it works on your GitHub Repos while you sleep. Submit a task. Go grab coffee. Come back to completed code. Jules doesn't just write code snippets. It's an Autonomous AI Agent that: ↳ Clones your entire GitHub repo ↳ Understands your full codebase context ↳ Fixes bugs and builds features independently ↳ Works on multiple tasks simultaneously ↳ Creates branches and prepares PRs for you The best part? You give it a task [...] and walk away. Jules runs in a secure cloud VM, handling everything while you focus on strategy, meetings, or other priorities. When it's done, you get: → A complete plan with reasoning → Code diffs showing exactly what changed → Real-time activity logs → Ready-to-review PRs Jules is like having a dedicated developer on your team. → One that never sleeps. → One that understands your project inside and out. → One that can juggle multiple features while you focus on strategy. The asynchronous", "score": 0.8252664}, {"title": "Jules - An Asynchronous Coding Agent", "url": "https://jules.google/", "content": "Jules does coding tasks you don't want to do. Jules does coding tasks you don't want to do. More time for the code you want to write, and everything else. Select your GitHub repository and branch. Write a detailed prompt for Jules. *coming soon* use "assign-to-jules" label in an issue to assign a task directly in GitHub. Jules fetches your repository, clones it to a Cloud VM, and develops a plan utilizing the latest Gemini 2.5 Pro model. Here is my plan: [...] I plan to update the following files to the new app directory structure. Jules provides a diff of the changes. Quickly browse and approve code edits. Jules creates a PR of the changes. Approve the PR, merge it to your branch, and publish it on GitHub. Also, you can get caught up fast. Jules creates an audio summary of the changes.", "score": 0.7771143}, {"title": "Jules - An Asynchronous Coding Agent (New Codex alternative from ...", "url": "https://www.reddit.com/r/ChatGPTCoding/comments/1kqompk/jules_an_asynchronous_coding_agent_new_codex/", "content": "It's 5 tasks per day. A task can have many separate messages.", "score": 0.6991933}, {"title": "Jules: An asynchronous coding agent | Hacker News", "url": "https://news.ycombinator.com/item?id=44034918", "content": "So, you can assign github issues to this thing, and it can handle them, merge the results in, and mark the bug as fixed?", "score": 0.6638657}]================================== Ai Message ==================================### Jules: An Asynchronous Coding Agent**Overview:**Jules is an asynchronous coding assistant developed by Google Labs, now available in public beta. It integrates directly with your existing code repositories, such as GitHub, and operates in a secure Google Cloud Virtual Machine (VM). The key feature of Jules is its asynchronous nature, meaning it can work on tasks independently in the background, without constant human oversight.**Key Features:**- **Asynchronous Task Handling:** Jules takes on specific coding tasks, works on them independently, and presents the completed work once ready. This allows developers to focus on strategic tasks and reduce repetitive coding chores.- **Full Codebase Understanding:** Jules clones your entire codebase into a secure cloud VM, where it gains a comprehensive understanding of your project's context. This enables it to make informed decisions and perform tasks more effectively.- **Task Execution:** Jules can handle a variety of tasks, including writing tests, fixing bugs, and building features. It can work on multiple tasks simultaneously, enhancing productivity.- **GitHub Integration:** The tool integrates seamlessly with GitHub, allowing you to assign tasks directly from GitHub issues. Jules will create branches, prepare pull requests (PRs), and manage the entire process.- **Detailed Change Logs:** After completing a task, Jules provides a comprehensive outline of the changes made, along with reasoning and code diffs. It also offers real-time activity logs for transparency.- **Audio Summaries:** Jules can create audio summaries of the changes, helping you quickly catch up on what has been done.**How to Use Jules:**1. **Sign Up:** Visit the Jules website and click "Try Jules" to create an account.2. **Select Repository:** Choose the GitHub repository and branch you want Jules to work on.3. **Assign Tasks:** Write a detailed prompt or use the "assign-to-jules" label in a GitHub issue to assign tasks.4. **Review Changes:** Jules will provide a diff of the changes, which you can browse and approve.5. **Merge PRs:** Once you approve the changes, Jules will create a PR, which you can merge into your branch.**Advantages:**- **Increased Productivity:** By offloading repetitive and time-consuming tasks, Jules allows developers to focus on more strategic and creative aspects of their work.- **Consistent Quality:** Jules ensures that code changes are consistent and adhere to best practices.- **Scalability:** The ability to handle multiple tasks simultaneously makes Jules a valuable tool for large and complex projects.**Conclusion:**Jules represents a significant advancement in AI-assisted coding, offering a unique asynchronous approach that can significantly enhance the efficiency and effectiveness of development workflows. Its integration with GitHub and comprehensive task management features make it a powerful tool for developers looking to streamline their coding processes.
Tenemos un resumen de lo que es Jules, vamos a imprimirlo
result_agent_pattern["messages"][-1].pretty_print()Copied
================================== Ai Message ==================================### Jules: An Asynchronous Coding Agent**Overview:**Jules is an asynchronous coding assistant developed by Google Labs, now available in public beta. It integrates directly with your existing code repositories, such as GitHub, and operates in a secure Google Cloud Virtual Machine (VM). The key feature of Jules is its asynchronous nature, meaning it can work on tasks independently in the background, without constant human oversight.**Key Features:**- **Asynchronous Task Handling:** Jules takes on specific coding tasks, works on them independently, and presents the completed work once ready. This allows developers to focus on strategic tasks and reduce repetitive coding chores.- **Full Codebase Understanding:** Jules clones your entire codebase into a secure cloud VM, where it gains a comprehensive understanding of your project's context. This enables it to make informed decisions and perform tasks more effectively.- **Task Execution:** Jules can handle a variety of tasks, including writing tests, fixing bugs, and building features. It can work on multiple tasks simultaneously, enhancing productivity.- **GitHub Integration:** The tool integrates seamlessly with GitHub, allowing you to assign tasks directly from GitHub issues. Jules will create branches, prepare pull requests (PRs), and manage the entire process.- **Detailed Change Logs:** After completing a task, Jules provides a comprehensive outline of the changes made, along with reasoning and code diffs. It also offers real-time activity logs for transparency.- **Audio Summaries:** Jules can create audio summaries of the changes, helping you quickly catch up on what has been done.**How to Use Jules:**1. **Sign Up:** Visit the Jules website and click "Try Jules" to create an account.2. **Select Repository:** Choose the GitHub repository and branch you want Jules to work on.3. **Assign Tasks:** Write a detailed prompt or use the "assign-to-jules" label in a GitHub issue to assign tasks.4. **Review Changes:** Jules will provide a diff of the changes, which you can browse and approve.5. **Merge PRs:** Once you approve the changes, Jules will create a PR, which you can merge into your branch.**Advantages:**- **Increased Productivity:** By offloading repetitive and time-consuming tasks, Jules allows developers to focus on more strategic and creative aspects of their work.- **Consistent Quality:** Jules ensures that code changes are consistent and adhere to best practices.- **Scalability:** The ability to handle multiple tasks simultaneously makes Jules a valuable tool for large and complex projects.**Conclusion:**Jules represents a significant advancement in AI-assisted coding, offering a unique asynchronous approach that can significantly enhance the efficiency and effectiveness of development workflows. Its integration with GitHub and comprehensive task management features make it a powerful tool for developers looking to streamline their coding processes.
















