
Disclaimer: This post has been translated to English using a machine translation model. Please, let me know if you find any mistakes.
Paper
Language Models are Unsupervised Multitask Learners is the GPT-2 paper. This is the second version of the model GPT-1 that we have already seen.
Architecture
Before discussing the architecture of GPT-2, let's recall how the architecture of GPT-1 was.
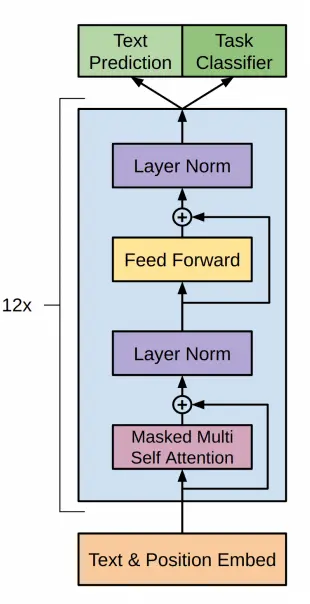
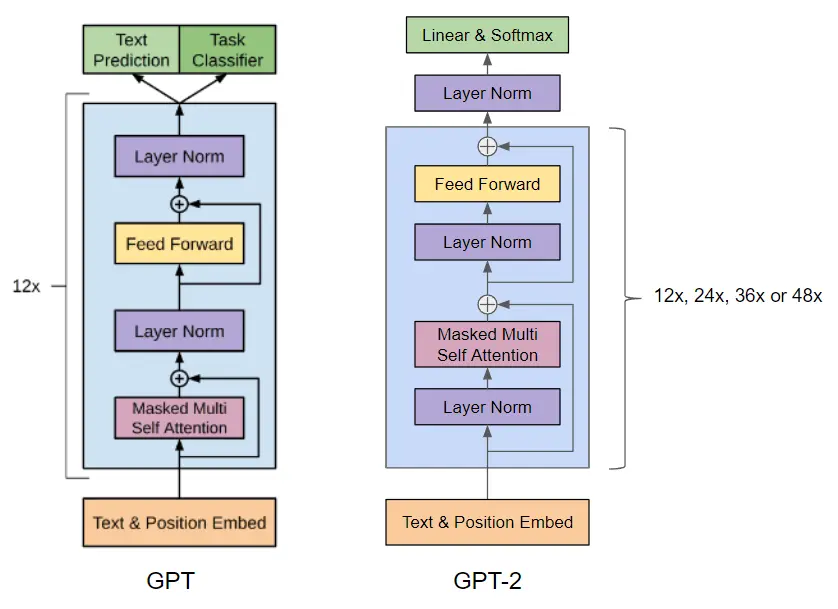
In GPT-2, a transformer-based architecture is used, just like in GPT-1, with the following sizes
| Parameters | Layers | d_model |
|---|---|---|
| 117M | 12 | 768 |
| 345M | 24 | 1024 |
| 1542M | 48 | 1600 |
The smallest model is equivalent to the original GPT, and the second smallest is equivalent to the largest BERT model. The largest model has more than an order of magnitude more parameters than GPT.
In addition, the following modifications were made to the architecture
- A normalization layer is added before the attention block. This can help stabilize the model's training and improve its ability to learn deeper representations. By normalizing the inputs of each block, variability in the outputs is reduced and model training is facilitated.
- An additional normalization has been added after the final self-attention block. This can help reduce variability in the model's outputs and improve its stability.
- In most models, the weights of the layers are initialized randomly, following a normal or uniform distribution. However, in the case of GPT-2, the authors decided to use a modified initialization that takes into account the depth of the model. The idea behind this modified initialization is that as the model becomes deeper, the signal flowing through the residual layers tends to weaken. This is because each residual layer adds to the original input, which can cause the signal to attenuate with the depth of the model. To counteract this effect, they decided to scale the weights of the residual layers during initialization by a factor of 1/√N, where N is the number of residual layers. This means that as the model becomes deeper, the weights of the residual layers become smaller. This initialization trick can help stabilize the training of the model and improve its ability to learn deeper representations. By scaling the weights of the residual layers, variability in the outputs of each layer is reduced, and the flow of the signal through the model is facilitated. In summary, the modified initialization in GPT-2 is used to counteract the attenuation effect of the signal in the residual layers, which helps stabilize the training of the model and improve its ability to learn deeper representations.
- The vocabulary size has expanded to 50,257. This means that the model can learn to represent a wider set of words and tokens.
- The context size has been increased from 512 to 1024 tokens. This allows the model to take into account a broader context when generating text.
Summary of the paper
The most interesting ideas from the paper are:
- For the pre-training of the model, they considered using a diverse and almost unlimited source of text, such as web scraping from Common Crawl. However, they found that there was text of very poor quality. So they used the WebText dataset, which also came from web scraping but with a quality filter, such as the number of outbound links from Reddit, etc. They also removed text coming from Wikipedia, as it could be duplicated on other pages.* They used a BPE tokenizer that we already explained in a post previously
Text Generation
Let's see how to generate text with a pretrained GPT-2
To generate text, we will use the model from the GPT-2 repository of Hugging Face.
Text Generation with Pipeline
With this model, we can already use the transformers pipeline
from transformers import pipelinecheckpoints = "openai-community/gpt2-xl"generator = pipeline('text-generation', model=checkpoints)output = generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)for i, o in enumerate(output):print(f"Output {i+1}: {o['generated_text']}")Copied
Truncation was not explicitly activated but `max_length` is provided a specific value, please use `truncation=True` to explicitly truncate examples to max length. Defaulting to 'longest_first' truncation strategy. If you encode pairs of sequences (GLUE-style) with the tokenizer you can select this strategy more precisely by providing a specific strategy to `truncation`.Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
Output 1: Hello, I'm a language model, and I want to change the way you readA little in today's post I want to talk aboutOutput 2: Hello, I'm a language model, with two roles: the language model and the lexicographer-semantics expert. The language models are goingOutput 3: Hello, I'm a language model, and this is your brain. Here is your brain, and all this data that's stored in there, thatOutput 4: Hello, I'm a language model, and I like to talk... I want to help you talk to your customersAre you using language modelOutput 5: Hello, I'm a language model, I'm gonna tell you about what type of language you're using. We all know a language like this,
Text Generation with Automodel
But if we want to use Automodel, we can do the following
import torchfrom transformers import GPT2Tokenizer, AutoTokenizercheckpoints = "openai-community/gpt2-xl"tokenizer = GPT2Tokenizer.from_pretrained(checkpoints)auto_tokenizer = AutoTokenizer.from_pretrained(checkpoints)Copied
Just like with GPT-1 we can import GPT2Tokenizer and AutoTokenizer. This is because in the GPT-2 model card it is indicated that GPT2Tokenizer should be used, but in the post about the transformers library we explain that AutoTokenizer should be used to load the tokenizer. So let's try both.
checkpoints = "openai-community/gpt2-xl"tokenizer = GPT2Tokenizer.from_pretrained(checkpoints)auto_tokenizer = AutoTokenizer.from_pretrained(checkpoints)input_tokens = tokenizer("Hello, I'm a language model,", return_tensors="pt")input_auto_tokens = auto_tokenizer("Hello, I'm a language model,", return_tensors="pt")print(f"input tokens: {input_tokens}")print(f"input auto tokens: {input_auto_tokens}")Copied
input tokens:{'input_ids': tensor([[15496, 11, 314, 1101, 257, 3303, 2746, 11]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1]])}input auto tokens:{'input_ids': tensor([[15496, 11, 314, 1101, 257, 3303, 2746, 11]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1]])}
As can be seen with the two tokenizers, the same tokens are obtained. So, to make the code more general, so that if the checkpoints change, the code doesn't have to be changed, we will use AutoTokenizer
We then create the device, the tokenizer, and the model
import torchfrom transformers import AutoTokenizer, GPT2LMHeadModeldevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")checkpoints = "openai-community/gpt2-xl"tokenizer = AutoTokenizer.from_pretrained(checkpoints)model = GPT2LMHeadModel.from_pretrained(checkpoints).to(device)Copied
Now that we have instantiated the model, let's see how many parameters it has
params = sum(p.numel() for p in model.parameters())print(f"Number of parameters: {round(params/1e6)}M")Copied
Number of parameters: 1558M
As we can see, we have loaded the model with 1.5B parameters, but if we wanted to load the other models, we would have to do
checkpoints_small = "openai-community/gpt2"model_small = GPT2LMHeadModel.from_pretrained(checkpoints_small)print(f"Number of parameters of small model: {round(sum(p.numel() for p in model_small.parameters())/1e6)}M")checkpoints_medium = "openai-community/gpt2-medium"model_medium = GPT2LMHeadModel.from_pretrained(checkpoints_medium)print(f"Number of parameters of medium model: {round(sum(p.numel() for p in model_medium.parameters())/1e6)}M")checkpoints_large = "openai-community/gpt2-large"model_large = GPT2LMHeadModel.from_pretrained(checkpoints_large)print(f"Number of parameters of large model: {round(sum(p.numel() for p in model_large.parameters())/1e6)}M")checkpoints_xl = "openai-community/gpt2-xl"model_xl = GPT2LMHeadModel.from_pretrained(checkpoints_xl)print(f"Number of parameters of xl model: {round(sum(p.numel() for p in model_xl.parameters())/1e6)}M")Copied
Number of parameters of small model: 124MNumber of parameters of medium model: 355MNumber of parameters of large model: 774MNumber of parameters of xl model: 1558M
We create the input tokens for the model
input_sentence = "Hello, I'm a language model,"input_tokens = tokenizer(input_sentence, return_tensors="pt").to(device)input_tokensCopied
{'input_ids': tensor([[15496, 11, 314, 1101, 257, 3303, 2746, 11]],device='cuda:0'), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1]], device='cuda:0')}
We pass it to the model to generate the output tokens
output_tokens = model.generate(**input_tokens)print(f"output tokens: {output_tokens}")Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation./home/wallabot/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/generation/utils.py:1178: UserWarning: Using the model-agnostic default `max_length` (=20) to control the generation length. We recommend setting `max_new_tokens` to control the maximum length of the generation.warnings.warn(
output tokens:tensor([[15496, 11, 314, 1101, 257, 3303, 2746, 11, 290, 314,1101, 1016, 284, 1037, 345, 351, 534, 1917, 13, 198]],device='cuda:0')
We decode the tokens to obtain the output sentence
decoded_output = tokenizer.decode(output_tokens[0], skip_special_tokens=True)print(f"decoded output: {decoded_output}")Copied
decoded output:Hello, I'm a language model, and I'm going to help you with your problem.
We have already managed to generate text with GPT-2
Generate Text Token by Token
Greedy search
We have used model.generate to generate the output tokens all at once, but let's see how to generate them one by one. For this, instead of using model.generate, we will use model, which actually calls the model.forward method.
outputs = model(**input_tokens)outputsCopied
CausalLMOutputWithCrossAttentions(loss=None, logits=tensor([[[ 6.6288, 5.1421, -0.8002, ..., -6.3998, -4.4113, 1.8240],[ 2.7250, 1.9371, -1.2293, ..., -5.0979, -5.1617, 2.2694],[ 2.6891, 4.3089, -1.6074, ..., -7.6321, -2.0448, 0.4042],...,[ 6.0513, 3.8020, -2.8080, ..., -6.7754, -8.3176, 1.1541],[ 6.8402, 5.6952, 0.2002, ..., -9.1281, -6.7818, 2.7576],[ 1.0255, -0.2201, -2.5484, ..., -6.2137, -7.2322, 0.1665]]],device='cuda:0', grad_fn=<UnsafeViewBackward0>), past_key_values=((tensor([[[[ 0.4779, 0.7671, -0.7532, ..., -0.3551, 0.4590, 0.3073],[ 0.2034, -0.6033, 0.2484, ..., 0.7760, -0.3546, 0.0198],[-0.1968, -0.9029, 0.5570, ..., 0.9985, -0.5028, -0.3508],...,[-0.5007, -0.4009, 0.1604, ..., -0.3693, -0.1158, 0.1320],[-0.4854, -0.1369, 0.7377, ..., -0.8043, -0.1054, 0.0871],[ 0.1610, -0.8358, -0.5534, ..., 0.9951, -0.3085, 0.4574]],[[ 0.6288, -0.1374, -0.3467, ..., -1.0003, -1.1518, 0.3114],[-1.7269, 1.2920, -0.0734, ..., 1.0572, 1.4698, -2.0412],[ 0.2714, -0.0670, -0.4769, ..., 0.6305, 0.6890, -0.8158],...,[-0.0499, -0.0721, 0.4580, ..., 0.6797, 0.2331, 0.0210],[-0.1894, 0.2077, 0.6722, ..., 0.6938, 0.2104, -0.0574],[ 0.3661, -0.0218, 0.2618, ..., 0.8750, 1.2205, -0.6103]],[[ 0.5964, 1.1178, 0.3604, ..., 0.8426, 0.4881, -0.4094],[ 0.3186, -0.3953, 0.2687, ..., -0.1110, -0.5640, 0.5900],...,[ 0.2092, 0.3898, -0.6061, ..., -0.2859, -0.3136, -0.1002],[ 0.0539, 0.8941, 0.3423, ..., -0.6326, -0.1053, -0.6679],[ 0.5628, 0.6687, -0.2720, ..., -0.1073, -0.9792, -0.0302]]]],device='cuda:0', grad_fn=<PermuteBackward0>))), hidden_states=None, attentions=None, cross_attentions=None)
We see that it outputs a lot of data, let's first look at the keys of the output.
outputs.keys()Copied
odict_keys(['logits', 'past_key_values'])
In this case we only have the logits of the model, let's check their size
logits = outputs.logitslogits.shapeCopied
torch.Size([1, 8, 50257])
Let's see how many tokens we had at the input
input_tokens.input_ids.shapeCopied
torch.Size([1, 8])
Well, at the output we have the same number of logits as at the input. This is normal.
We obtain the logits from the last position of the output
nex_token_logits = logits[0,-1]nex_token_logits.shapeCopied
torch.Size([50257])
There is a total of 50257 logits, meaning there is a vocabulary of 50257 tokens and we need to determine which token has the highest probability. To do this, we first calculate the softmax.
softmax_logits = torch.softmax(nex_token_logits, dim=0)softmax_logits.shapeCopied
torch.Size([50257])
Once we have calculated the softmax, we obtain the most likely token by finding the one with the highest probability, that is, the one with the highest value after the softmax.
next_token_prob, next_token_id = torch.max(softmax_logits, dim=0)next_token_prob, next_token_idCopied
(tensor(0.1732, device='cuda:0', grad_fn=<MaxBackward0>),tensor(290, device='cuda:0'))
We have obtained the following token, now we decode it
tokenizer.decode(next_token_id.item())Copied
' and'
We obtained the following token using the greedy method, that is, the token with the highest probability. But we already saw in the post about the transformers library the ways to generate text that can be done sampling, top-k, top-p, etc.
Let's put everything into a function and see what comes out if we generate a few tokens
def generate_next_greedy_token(input_sentence, tokenizer, model, device):input_tokens = tokenizer(input_sentence, return_tensors="pt").to(device)outputs = model(**input_tokens)logits = outputs.logitsnex_token_logits = logits[0,-1]softmax_logits = torch.softmax(nex_token_logits, dim=0)next_token_prob, next_token_id = torch.max(softmax_logits, dim=0)return next_token_prob, next_token_idCopied
def generate_greedy_text(input_sentence, tokenizer, model, device, max_length=20):generated_text = input_sentencefor _ in range(max_length):next_token_prob, next_token_id = generate_next_greedy_token(generated_text, tokenizer, model, device)generated_text += tokenizer.decode(next_token_id.item())return generated_textCopied
Now we generate text
generate_greedy_text("Hello, I'm a language model,", tokenizer, model, device)Copied
"Hello, I'm a language model, and I'm going to help you with your problem. I'm going to help you"
The output is quite repetitive as was already seen in the ways of generating texts. However, it is still a better output than what we obtained with GPT-1
Architecture of the models available in Hugging Face
If we go to the Hugging Face documentation for GPT2 we can see that we have the options GPT2Model, GPT2LMHeadModel, GPT2ForSequenceClassification, GPT2ForQuestionAnswering, GPT2ForTokenClassification. Let's take a look at them.
import torchckeckpoints = "openai-community/gpt2"Copied
GPT2Model
This is the base model, that is, the transformer decoder.
from transformers import GPT2Modelmodel = GPT2Model.from_pretrained(ckeckpoints)modelCopied
GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))
As can be seen from the output, a tensor of dimension 768, which is the dimension of the embeddings for the small model. If we had used the model openai-community/gpt2-xl, we would have obtained an output of 1600.
Depending on the task you want to perform, you would now need to add more layers.
We can add them manually, but the weights of those layers would be initialized randomly. Whereas if we use Hugging Face models with these layers, the weights are pretrained.
GPT2LMHeadModel
It is the one we used before to generate text
from transformers import GPT2LMHeadModelmodel = GPT2LMHeadModel.from_pretrained(ckeckpoints)modelCopied
GPT2LMHeadModel((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(lm_head): Linear(in_features=768, out_features=50257, bias=False))
As can be seen, it is the same model as before, only at the end a linear layer has been added with an input of 768 (the embeddings) and an output of 50257, which corresponds to the vocabulary size.
GPT2ForSequenceClassification
This option is for classifying text sequences, in this case we have to specify with num_labels the number of classes we want to classify.
from transformers import GPT2ForSequenceClassificationmodel = GPT2ForSequenceClassification.from_pretrained(ckeckpoints, num_labels=5)modelCopied
Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
GPT2ForSequenceClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(score): Linear(in_features=768, out_features=5, bias=False))
Now, instead of having an output of 50257, we have an output of 5, which is the number we introduced in num_labels and is the number of classes we want to classify.
GPT2ForQuestionAnswering
In the post of transformers we explain that, in this mode, a context is passed to the model along with a question about the context and it returns the answer.
from transformers import GPT2ForQuestionAnsweringmodel = GPT2ForQuestionAnswering.from_pretrained(ckeckpoints)modelCopied
Some weights of GPT2ForQuestionAnswering were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['qa_outputs.bias', 'qa_outputs.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
GPT2ForQuestionAnswering((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(qa_outputs): Linear(in_features=768, out_features=2, bias=True))
We see that the output gives us a two-dimensional tensor
GPT2ForTokenClassification
We also discussed in the transformers post what token classification was, explaining that it classified which category each token belonged to. We need to pass the number of classes we want to classify with num_labels.
from transformers import GPT2ForTokenClassificationmodel = GPT2ForTokenClassification.from_pretrained(ckeckpoints, num_labels=5)modelCopied
Some weights of GPT2ForTokenClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['classifier.bias', 'classifier.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
GPT2ForTokenClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(dropout): Dropout(p=0.1, inplace=False)(classifier): Linear(in_features=768, out_features=5, bias=True))
At the output, we get the five classes that we specified with num_labels
Fine tuning GPT-2
Fine tuning for text generation
First, let's see how the training would be done with pure Pytorch
Calculation of the Loss
Before starting to fine-tune GPT-2, let's look at something. Previously, when we obtained the model's output, we did this
outputs = model(**input_tokens)outputsCopied
CausalLMOutputWithCrossAttentions(loss=None, logits=tensor([[[ 6.6288, 5.1421, -0.8002, ..., -6.3998, -4.4113, 1.8240],[ 2.7250, 1.9371, -1.2293, ..., -5.0979, -5.1617, 2.2694],[ 2.6891, 4.3089, -1.6074, ..., -7.6321, -2.0448, 0.4042],...,[ 6.0513, 3.8020, -2.8080, ..., -6.7754, -8.3176, 1.1541],[ 6.8402, 5.6952, 0.2002, ..., -9.1281, -6.7818, 2.7576],[ 1.0255, -0.2201, -2.5484, ..., -6.2137, -7.2322, 0.1665]]],device='cuda:0', grad_fn=<UnsafeViewBackward0>), past_key_values=((tensor([[[[ 0.4779, 0.7671, -0.7532, ..., -0.3551, 0.4590, 0.3073],[ 0.2034, -0.6033, 0.2484, ..., 0.7760, -0.3546, 0.0198],[-0.1968, -0.9029, 0.5570, ..., 0.9985, -0.5028, -0.3508],...,[-0.5007, -0.4009, 0.1604, ..., -0.3693, -0.1158, 0.1320],[-0.4854, -0.1369, 0.7377, ..., -0.8043, -0.1054, 0.0871],[ 0.1610, -0.8358, -0.5534, ..., 0.9951, -0.3085, 0.4574]],[[ 0.6288, -0.1374, -0.3467, ..., -1.0003, -1.1518, 0.3114],[-1.7269, 1.2920, -0.0734, ..., 1.0572, 1.4698, -2.0412],[ 0.2714, -0.0670, -0.4769, ..., 0.6305, 0.6890, -0.8158],...,[-0.0499, -0.0721, 0.4580, ..., 0.6797, 0.2331, 0.0210],[-0.1894, 0.2077, 0.6722, ..., 0.6938, 0.2104, -0.0574],[ 0.3661, -0.0218, 0.2618, ..., 0.8750, 1.2205, -0.6103]],[[ 0.5964, 1.1178, 0.3604, ..., 0.8426, 0.4881, -0.4094],[ 0.3186, -0.3953, 0.2687, ..., -0.1110, -0.5640, 0.5900],...,[ 0.2092, 0.3898, -0.6061, ..., -0.2859, -0.3136, -0.1002],[ 0.0539, 0.8941, 0.3423, ..., -0.6326, -0.1053, -0.6679],[ 0.5628, 0.6687, -0.2720, ..., -0.1073, -0.9792, -0.0302]]]],device='cuda:0', grad_fn=<PermuteBackward0>))), hidden_states=None, attentions=None, cross_attentions=None)
We can see that we get loss=None
print(outputs.loss)Copied
None
Since we will need the loss to perform fine-tuning, let's see how to obtain it.
If we go to the documentation of the forward method of GPT2LMHeadModel, we can see that it states that the output is an object of type transformers.modeling_outputs.CausalLMOutputWithCrossAttentions. So, if we go to the documentation of transformers.modeling_outputs.CausalLMOutputWithCrossAttentions, we can see that it states that it returns loss if labels are passed to the forward method.
If we go to the source code of the forward method, we see this block of code
loss = None
if labels is not None:
# move labels to correct device to enable model parallelism
labels = labels.to(lm_logits.device)
# Shift so that tokens < n predict n
shift_logits = lm_logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
loss_fct = CrossEntropyLoss()
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))That is, the loss is calculated as follows
- Logits and labels shift: The first part is to shift the logits (
lm_logits) and the labels (labels) so that thetokens < npredictn, meaning from positionnit predicts the next token based on the previous ones. - CrossEntropyLoss: An instance of the loss function
CrossEntropyLoss()is created. - Flatten tokens: Next, the logits and labels are flattened using
view(-1, shift_logits.size(-1))andview(-1), respectively. This is done to ensure that the logits and labels have the same shape for the loss function. - Calculation of the loss: Finally, the loss is calculated using the
CrossEntropyLoss()function with the flattened logits and flattened labels as inputs.
In summary, the loss is calculated as the cross-entropy loss between the shifted and flattened logits and the shifted and flattened labels.
Therefore, if we pass the labels to the forward method, it will return the loss.
outputs = model(**input_tokens, labels=input_tokens.input_ids)outputs.lossCopied
tensor(3.8028, device='cuda:0', grad_fn=<NllLossBackward0>)
Dataset
For the training, we are going to use an English jokes dataset short-jokes-dataset, which is a dataset with 231 thousand English jokes.
We restart the notebook to avoid issues with the GPU memory
We download the dataset
from datasets import load_datasetjokes = load_dataset("Maximofn/short-jokes-dataset")jokesCopied
DatasetDict({train: Dataset({features: ['ID', 'Joke'],num_rows: 231657})})
Let's take a look at it a bit
jokes["train"][0]Copied
{'ID': 1,'Joke': '[me narrating a documentary about narrators] "I can't hear what they're saying cuz I'm talking"'}
Model Instance
To be able to use the xl model, that is, the one with 1.5B parameters, I switch it to FP16 to avoid running out of memory.
import torchfrom transformers import AutoTokenizer, GPT2LMHeadModeldevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")ckeckpoints = "openai-community/gpt2-xl"tokenizer = AutoTokenizer.from_pretrained(ckeckpoints)model = GPT2LMHeadModel.from_pretrained(ckeckpoints)model = model.half().to(device)Copied
Pytorch dataset
We create a Dataset class in Pytorch
from torch.utils.data import Datasetclass JokesDataset(Dataset):def __init__(self, dataset, tokenizer):self.dataset = datasetself.joke = "JOKE: "self.end_of_text_token = "<|endoftext|>"self.tokenizer = tokenizerdef __len__(self):return len(self.dataset["train"])def __getitem__(self, item):sentence = self.joke + self.dataset["train"][item]["Joke"] + self.end_of_text_tokentokens = self.tokenizer(sentence, return_tensors="pt")return sentence, tokensCopied
We instantiate it
dataset = JokesDataset(jokes, tokenizer=tokenizer)Copied
We see an example
sentence, tokens = dataset[5]print(sentence)tokens.input_ids.shape, tokens.attention_mask.shapeCopied
JOKE: Why can't Barbie get pregnant? Because Ken comes in a different box. Heyooooooo<|endoftext|>
(torch.Size([1, 22]), torch.Size([1, 22]))
Dataloader
We now create a DataLoader from Pytorch
from torch.utils.data import DataLoaderBS = 1joke_dataloader = DataLoader(dataset, batch_size=BS, shuffle=True)Copied
We see a batch
sentences, tokens = next(iter(joke_dataloader))len(sentences), tokens.input_ids.shape, tokens.attention_mask.shapeCopied
(1, torch.Size([1, 1, 36]), torch.Size([1, 1, 36]))
Training
from transformers import AdamW, get_linear_schedule_with_warmupimport tqdmBATCH_SIZE = 32EPOCHS = 5LEARNING_RATE = 3e-6WARMUP_STEPS = 5000MAX_SEQ_LEN = 500optimizer = AdamW(model.parameters(), lr=LEARNING_RATE)scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=WARMUP_STEPS, num_training_steps=-1)proc_seq_count = 0batch_count = 0tmp_jokes_tens = Nonelosses = []lrs = []for epoch in range(EPOCHS):print(f"EPOCH {epoch} started" + '=' * 30)progress_bar = tqdm.tqdm(joke_dataloader, desc="Training")for sample in progress_bar:sentence, tokens = sample#################### "Fit as many joke sequences into MAX_SEQ_LEN sequence as possible" logic start ####joke_tens = tokens.input_ids[0].to(device)# Skip sample from dataset if it is longer than MAX_SEQ_LENif joke_tens.size()[1] > MAX_SEQ_LEN:continue# The first joke sequence in the sequenceif not torch.is_tensor(tmp_jokes_tens):tmp_jokes_tens = joke_tenscontinueelse:# The next joke does not fit in so we process the sequence and leave the last joke# as the start for next sequenceif tmp_jokes_tens.size()[1] + joke_tens.size()[1] > MAX_SEQ_LEN:work_jokes_tens = tmp_jokes_tenstmp_jokes_tens = joke_tenselse:#Add the joke to sequence, continue and try to add moretmp_jokes_tens = torch.cat([tmp_jokes_tens, joke_tens[:,1:]], dim=1)continue################## Sequence ready, process it trough the model ##################outputs = model(work_jokes_tens, labels=work_jokes_tens)loss = outputs.lossloss.backward()proc_seq_count = proc_seq_count + 1if proc_seq_count == BATCH_SIZE:proc_seq_count = 0batch_count += 1optimizer.step()scheduler.step()optimizer.zero_grad()model.zero_grad()progress_bar.set_postfix({'loss': loss.item(), 'lr': scheduler.get_last_lr()[0]})losses.append(loss.item())lrs.append(scheduler.get_last_lr()[0])if batch_count == 10:batch_count = 0Copied
/home/wallabot/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/optimization.py:429: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warningwarnings.warn(
EPOCH 0 started==============================
Training: 0%| | 0/231657 [00:00<?, ?it/s]
Training: 100%|██████████| 231657/231657 [32:29<00:00, 118.83it/s, loss=3.1, lr=2.31e-7]
EPOCH 1 started==============================
Training: 100%|██████████| 231657/231657 [32:34<00:00, 118.55it/s, loss=2.19, lr=4.62e-7]
EPOCH 2 started==============================
Training: 100%|██████████| 231657/231657 [32:36<00:00, 118.42it/s, loss=2.42, lr=6.93e-7]
EPOCH 3 started==============================
Training: 100%|██████████| 231657/231657 [32:23<00:00, 119.18it/s, loss=2.16, lr=9.25e-7]
EPOCH 4 started==============================
Training: 100%|██████████| 231657/231657 [32:22<00:00, 119.25it/s, loss=2.1, lr=1.16e-6]
import numpy as npimport matplotlib.pyplot as pltlosses_np = np.array(losses)lrs_np = np.array(lrs)plt.figure(figsize=(12,6))plt.plot(losses_np, label='loss')plt.plot(lrs_np, label='learning rate')plt.yscale('log')plt.legend()plt.show()Copied
<Figure size 1200x600 with 1 Axes>
Inference
Let's see how well the model tells jokes
sentence_joke = "JOKE:"input_tokens_joke = tokenizer(sentence_joke, return_tensors="pt").to(device)output_tokens_joke = model.generate(**input_tokens_joke)decoded_output_joke = tokenizer.decode(output_tokens_joke[0], skip_special_tokens=True)print(f"decoded joke: {decoded_output_joke}")Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation./home/wallabot/miniconda3/envs/nlp/lib/python3.11/site-packages/transformers/generation/utils.py:1178: UserWarning: Using the model-agnostic default `max_length` (=20) to control the generation length. We recommend setting `max_new_tokens` to control the maximum length of the generation.warnings.warn(
decoded joke:JOKE:!!!!!!!!!!!!!!!!!
You can see that you pass it a sequence with the word joke and it returns a joke. But if you return another sequence, it does not.
sentence_joke = "My dog is cute and"input_tokens_joke = tokenizer(sentence_joke, return_tensors="pt").to(device)output_tokens_joke = model.generate(**input_tokens_joke)decoded_output_joke = tokenizer.decode(output_tokens_joke[0], skip_special_tokens=True)print(f"decoded joke: {decoded_output_joke}")Copied
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
decoded joke:My dog is cute and!!!!!!!!!!!!!!!
Fine tuning GPT-2 for sentence classification
Now we are going to do a training with the Hugging Face libraries
Dataset
We are going to use the imdb dataset for sentiment classification into positive and negative.
from datasets import load_datasetdataset = load_dataset("imdb")datasetCopied
DatasetDict({train: Dataset({features: ['text', 'label'],num_rows: 25000})test: Dataset({features: ['text', 'label'],num_rows: 25000})unsupervised: Dataset({features: ['text', 'label'],num_rows: 50000})})
Let's take a look at it a bit
dataset["train"].infoCopied
DatasetInfo(description='', citation='', homepage='', license='', features={'text': Value(dtype='string', id=None), 'label': ClassLabel(names=['neg', 'pos'], id=None)}, post_processed=None, supervised_keys=None, task_templates=None, builder_name='parquet', dataset_name='imdb', config_name='plain_text', version=0.0.0, splits={'train': SplitInfo(name='train', num_bytes=33435948, num_examples=25000, shard_lengths=None, dataset_name='imdb'), 'test': SplitInfo(name='test', num_bytes=32653810, num_examples=25000, shard_lengths=None, dataset_name='imdb'), 'unsupervised': SplitInfo(name='unsupervised', num_bytes=67113044, num_examples=50000, shard_lengths=None, dataset_name='imdb')}, download_checksums={'hf://datasets/imdb@e6281661ce1c48d982bc483cf8a173c1bbeb5d31/plain_text/train-00000-of-00001.parquet': {'num_bytes': 20979968, 'checksum': None}, 'hf://datasets/imdb@e6281661ce1c48d982bc483cf8a173c1bbeb5d31/plain_text/test-00000-of-00001.parquet': {'num_bytes': 20470363, 'checksum': None}, 'hf://datasets/imdb@e6281661ce1c48d982bc483cf8a173c1bbeb5d31/plain_text/unsupervised-00000-of-00001.parquet': {'num_bytes': 41996509, 'checksum': None}}, download_size=83446840, post_processing_size=None, dataset_size=133202802, size_in_bytes=216649642)
Let's take a look at the features this dataset has.
dataset["train"].info.featuresCopied
{'text': Value(dtype='string', id=None),'label': ClassLabel(names=['neg', 'pos'], id=None)}
The dataset contains strings and classes. Additionally, there are two types of classes, pos and neg. We will create a variable with the number of classes.
num_clases = len(dataset["train"].unique("label"))num_clasesCopied
2
Tokenizer
We create the tokenizer
from transformers import GPT2Tokenizercheckpoints = "openai-community/gpt2"tokenizer = GPT2Tokenizer.from_pretrained(checkpoints, bos_token='<|startoftext|>', eos_token='<|endoftext|>', pad_token='<|pad|>')tokenizer.pad_token = tokenizer.eos_tokenCopied
Now that we have a tokenizer, we can tokenize the dataset, since the model only understands tokens.
def tokenize_function(examples):return tokenizer(examples["text"], padding="max_length", truncation=True)tokenized_datasets = dataset.map(tokenize_function, batched=True)Copied
Model
We instantiate the model
from transformers import GPT2ForSequenceClassificationmodel = GPT2ForSequenceClassification.from_pretrained(checkpoints, num_labels=num_clases).half()model.config.pad_token_id = model.config.eos_token_idCopied
Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Evaluation
We create an evaluation metric
import numpy as npimport evaluatemetric = evaluate.load("accuracy")def compute_metrics(eval_pred):logits, labels = eval_predpredictions = np.argmax(logits, axis=-1)return metric.compute(predictions=predictions, references=labels)Copied
Trainer
We create the trainer
from transformers import Trainer, TrainingArgumentstraining_args = TrainingArguments(output_dir="./results",learning_rate=2e-5,per_device_train_batch_size=16,per_device_eval_batch_size=64,num_train_epochs=3,weight_decay=0.01,)trainer = Trainer(model=model,args=training_args,train_dataset=tokenized_datasets["train"],eval_dataset=tokenized_datasets["test"],compute_metrics=compute_metrics,)Copied
Training
We train
trainer.train()Copied
<IPython.core.display.HTML object>
TrainOutput(global_step=4689, training_loss=0.04045845954294626, metrics={'train_runtime': 5271.3532, 'train_samples_per_second': 14.228, 'train_steps_per_second': 0.89, 'total_flos': 3.91945125888e+16, 'train_loss': 0.04045845954294626, 'epoch': 3.0})
Inference
We test the model after training it.
import torchdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")def get_sentiment(sentence):inputs = tokenizer(sentence, return_tensors="pt").to(device)outputs = model(**inputs)prediction = outputs.logits.argmax(-1).item()return "positive" if prediction == 1 else "negative"Copied
sentence = "I hate this movie!"print(get_sentiment(sentence))Copied
negative
















