Disclaimer: This post has been translated to English using a machine translation model. Please, let me know if you find any mistakes.
Neural networks were created between the 1950s and 1960s, imitating the functioning of the synapse between human neurons; in other words, neural networks mimic our neurons.
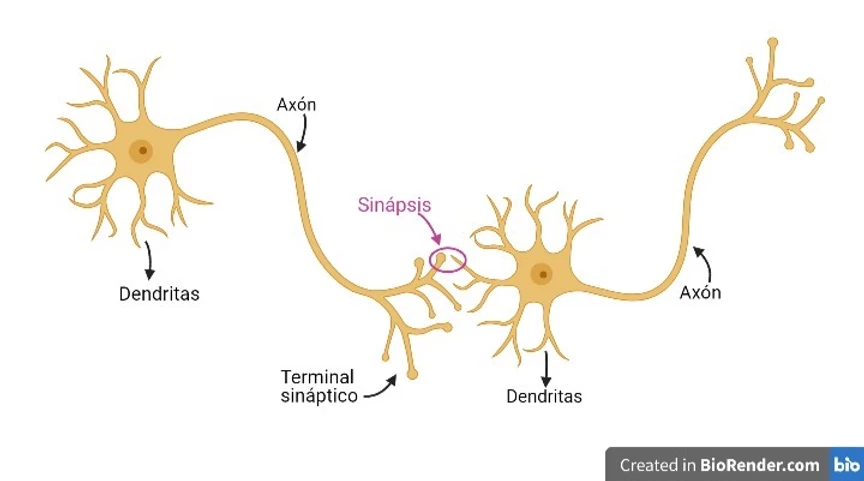
Our neurons have *dendrites* through which electrical potentials arrive, and the *axon* through which new electrical potentials exit. In this way, the *axons* of some neurons can connect with the *dendrites* of others, forming neural networks. Each neuron will receive different electrical potentials through its *dendrites*; these will process those potentials, causing a new electrical potential to exit through its *axon*.
Therefore, neurons can be understood as elements that receive signals from other neurons, process them, and send another signal to another neuron.
With this analogy, artificial neural networks were created, which are a set of elements that receive signals from other neurons, process them, and return other signals. They can be understood as units that perform calculations with the signals they receive and return another signal, that is, as processing units.
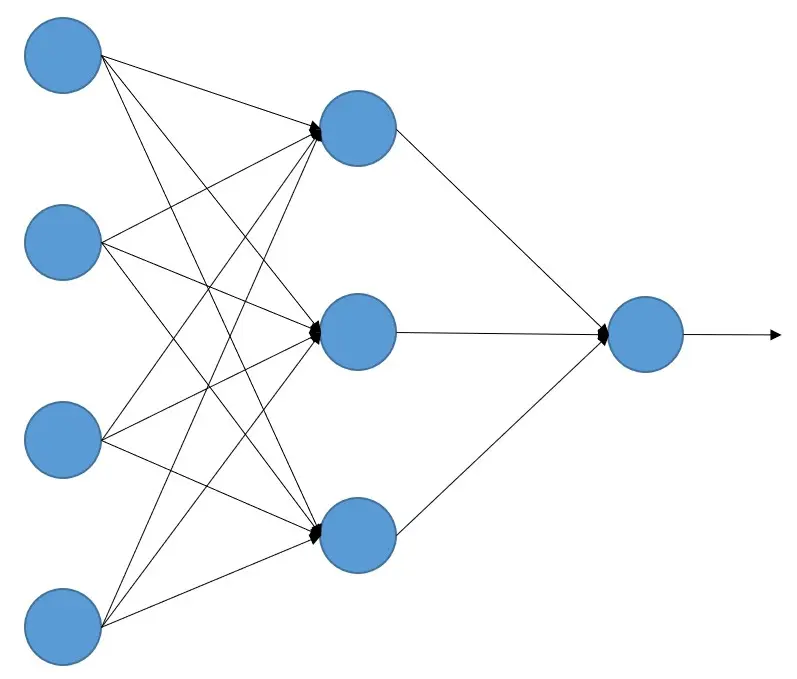
How do neural networks learn?
As we have said, artificial neural networks are a set of 'neurons' that perform a calculation of all the incoming signals, but how do we know what calculations each neuron needs to make so that an artificial neural network (from now on we will simply call them neural networks) performs the task we want?
This is done through machine learning. The neural network is given a bunch of labeled examples so it can learn. For example, if we want to make a network that distinguishes between dogs and cats, we give the network a lot of images of dogs telling it that they are dogs and a lot of images of cats telling it that they are cats.

When the network has the labeled dataset (in this case, images of dogs and cats), each image is fed to the network, which produces a result, and if it is not as expected (in this case, dog or cat), via the backpropagation algorithm (which we will study later; this is just a theoretical introduction), the calculations made by each neuron are gradually corrected. In this way, as the network is trained with many images, the neural network gets better and better until it predicts correctly (in our case, distinguishing between a dog and a cat).
If you think about it, this is the same thing that happens in our brains. Those of you who are parents have experienced it. When you have a son or daughter, you don't explain to them what a dog or a cat is; as you see dogs and cats, you say to them "*Look, a dog!*" or "*There is the cat that goes meow!*". And the boy or girl, in their brain, goes through the learning process until one day they say to you "*A woof woof!*"
The Winter of Artificial Intelligence
Well, we already have everything we need: a system that learns just like the human brain does, and algorithms that imitate it. We just need labeled data and computers to do the calculations... Well, not quite!
On the one hand, it was found that a large amount of data was necessary for neural networks to learn. Imagine the situation—as I explained before, neural networks were created between the 1950s and 1960s, and at that time there were no large databases, let alone labeled ones!
In addition, the few databases that might have existed were very small, since storage capacity was very limited. Nowadays, we can have GB of memory on our mobile phones, but at that time that was unthinkable, and until not so long ago it was still unthinkable.
It was common for there to be *analog databases*, that is, a large number of documents stored in libraries, universities, etc. But what was needed was for that data to be digitized and introduced to the networks. Put yourself in the situation again: the 1950s and 60s.
Moreover, computers were very slow at performing the number of calculations these algorithms required, so training a very simple network took a long time (days or weeks) and also did not produce very good results.
All these technical difficulties lasted for many years—back in the 90s it was still common to keep things stored on floppy disks, whose maximum capacity could reach only 2 MB!
For these reasons, these algorithms were discarded and even looked down upon within the scientific community. Anyone interested in researching them had to do so almost as a hobby and without making it too public.

Artificial Intelligence Revolution
However, in 2012 an event occurred that revolutionized everything. But let's go back a few years to put things into context.
In 2007, the first iPhone was released (and subsequently a lot of smartphones from other brands), which put into almost everyone's hands a device capable of taking increasingly high-quality photos, writing texts, music, audio recordings, etc. And all with increasing storage capacity. As a result, in just a few years, it became possible to create large, digitized, and labeled databases.
So we already had 2 out of the 3 problems solved. We had great capacity to generate digital format data, label it, and store it.
On the other hand, around that time, due to the growing world of video games, graphics cards or GPUs were becoming increasingly powerful because of the ever-expanding market. And it so happened that the calculations performed by these GPUs were very similar to those required by neural network algorithms.
So we already had devices that were capable of performing the necessary calculations in an acceptable amount of time.
We already had everything, it was only a matter of time before someone put it all together.
ImageNet Competition
In 2010, a computer image recognition competition called ILSVRC (ImageNet Large Scale Visual Recognition Challenge) was launched. It contains more than 14 million images classified into 1,000 different categories. The team with the lowest error rate wins.
In the first two years, 2010 and 2011, winners achieved a similar error rate, between 25% and 30%, but in 2012 a team won the competition with a neural network called AlexNet and achieved an error rate just above 15%, that is, a difference of 10 points. From then on, every year the winning teams used better neural networks until the moment was reached when the human error rate, which is 5%, was surpassed.
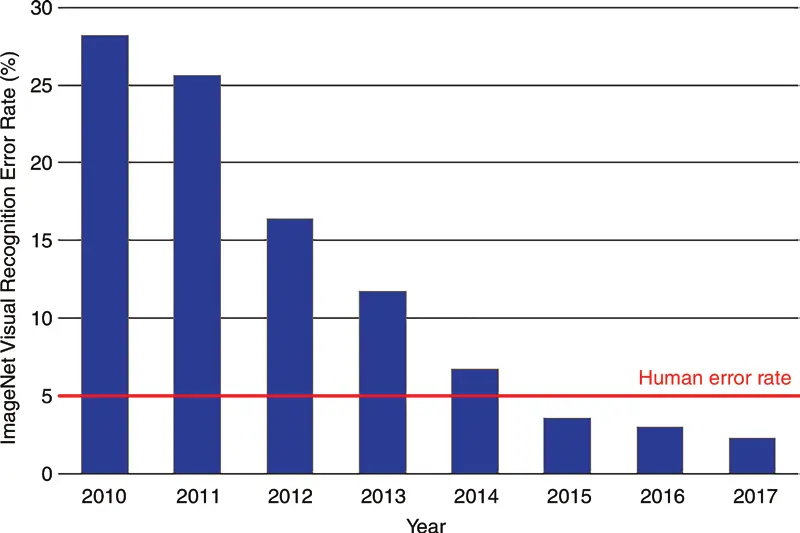
That milestone in the competition in 2012 made the scientific community realize that neural networks worked and the great power they had. Since then, research has not stopped, resulting in huge advances from one year to the next.
Examples of Neural Networks
It can be seen how the generation of face images using a neural network architecture called GAN has improved significantly since 2014.

We can go to the website this person does not exist, where each time we visit it will show us the image of a person who does not exist and has been generated by a neural network. Or we can go to the website this X does not exist, where it shows us pages that do the same thing but with other themes.
OpenAI has created Dall-e 2, which is a network that you can ask to draw something for you, such as an astronaut relaxing at a tropical resort in a photorealistic style.

Nvidia has created GauGan2, which can turn a poorly drawn sketch into a beautiful landscape.

We can see how, thanks to neural networks, Tesla has managed to create its autopilot

And how can you not be left speechless by deepfakes
More and more astonishing examples keep appearing, and probably, by the time you are watching this course, the examples I have included will already be quite old and there will be much newer and more amazing ones.