La librería datasets de Hugging Face es una librería muy útil para trabajar con datasets, tanto con todos los que hay en el hub como con datasets propios.
Instalación
Para usar la librería datasets de Hugging Face, primero debemos instalarla con pip
pip install datasetso con Conda
conda install -c huggingface -c conda-forge datasetsCargar un dataset desde el hub
Hugging Face tiene un hub con una gran cantidad de datasets, clasificados por tareas o tasks
Obtener la información del dataset
Antes de descargar un dataset conviene obtener la información de este. Lo mejor es entrar en el hub y ver su información, pero si no se puede, se puede obtener la información primero hay que cargar un generador de un dataset con la función load_dataset_builder, lo cual no conlleva la descarga y luego obtener su información con el método info.
InputPythonfrom datasets import load_dataset_builderds_builder = load_dataset_builder("yelp_review_full")info = ds_builder.infoinfoCopied
DatasetInfo(description='', citation='', homepage='', license='', features={'label': ClassLabel(names=['1 star', '2 star', '3 stars', '4 stars', '5 stars'], id=None), 'text': Value(dtype='string', id=None)}, post_processed=None, supervised_keys=None, task_templates=None, builder_name='parquet', dataset_name='yelp_review_full', config_name='yelp_review_full', version=0.0.0, splits={'train': SplitInfo(name='train', num_bytes=483811554, num_examples=650000, shard_lengths=None, dataset_name=None), 'test': SplitInfo(name='test', num_bytes=37271188, num_examples=50000, shard_lengths=None, dataset_name=None)}, download_checksums=None, download_size=322952369, post_processing_size=None, dataset_size=521082742, size_in_bytes=None)
Se pueden ver por ejemplo las clases
InputPythoninfo.featuresCopied
{'label': ClassLabel(names=['1 star', '2 star', '3 stars', '4 stars', '5 stars'], id=None),'text': Value(dtype='string', id=None)}
Descarga del dataset
Si estamos contentos con el dataset que hemos elegido podemos descargarlo con la función load_dataset
InputPythonfrom datasets import load_datasetds = load_dataset("yelp_review_full")dsCopied
DatasetDict({train: Dataset({features: ['label', 'text'],num_rows: 650000})test: Dataset({features: ['label', 'text'],num_rows: 50000})})
Splits
Como se puede ver, cuando hemos descargado el dataset hemos visto que se ha bajado el conjunto de train y el de test. Si queremos saber qué conjuntos tiene un dataset, podemos usar la función get_dataset_split_names
InputPythonfrom datasets import get_dataset_split_namessplit_names = get_dataset_split_names("yelp_review_full")split_namesCopied
['train', 'test']
Hay datasets que también tienen un conjunto de validation
InputPythonfrom datasets import get_dataset_split_namessplit_names = get_dataset_split_names("rotten_tomatoes")split_namesCopied
['train', 'validation', 'test']
Como los datasets tienen conjuntos de datos, podemos descargar solo uno de ellos con el argumento split
InputPythonfrom datasets import load_datasetds = load_dataset("yelp_review_full", split="train")dsCopied
Dataset({features: ['label', 'text'],num_rows: 650000})
Configuraciones
Algunos datasets tienen subconjuntos de datasets, para ver los subconjuntos de un dataset podemos usar la función get_dataset_config_names
InputPythonfrom datasets import get_dataset_config_namesconfigs = get_dataset_config_names("opus100")configsCopied
['af-en','am-en','an-en','ar-de','ar-en','ar-fr','ar-nl','ar-ru','ar-zh','as-en','az-en','be-en','bg-en','bn-en','br-en','bs-en','ca-en','cs-en','cy-en','da-en',...'en-yi','en-yo','en-zh','en-zu','fr-nl','fr-ru','fr-zh','nl-ru','nl-zh','ru-zh']
Este dataset tiene subconjuntos de traducciones de un idioma a otro
Si solo se quiere descargar un subconjunto de un dataset, solo hay que especificarlo
InputPythonfrom datasets import load_datasetopus100en_es = load_dataset("opus100", "en-es")opus100en_esCopied
DatasetDict({test: Dataset({features: ['translation'],num_rows: 2000})train: Dataset({features: ['translation'],num_rows: 1000000})validation: Dataset({features: ['translation'],num_rows: 2000})})
Código remoto
Todos los archivos y códigos cargados en Hub se analizan en busca de malware, se ejecuta un script para comprobarlos. Pero si quieres descargarlos más rápido sin que se ejecute ese script debes poner el parámetro trust_remote_code=True. Esto solo es aconsejable en un dataset en el que confíes, o si quieres hacer esa comprobación tú mismo.
InputPythonfrom datasets import load_datasetopus100 = load_dataset("opus100", "en-es", trust_remote_code=True)opus100Copied
DatasetDict({test: Dataset({features: ['translation'],num_rows: 2000})train: Dataset({features: ['translation'],num_rows: 1000000})validation: Dataset({features: ['translation'],num_rows: 2000})})
Conociendo los conjuntos de datos
En Hugging Face existen dos conjuntos de datos, los conjuntos de datos normales y los conjuntos de datos iterables, que son conjuntos de datos que no necesitan ser cargados enteros. Esto qué quiere decir, supongamos que tenemos un dataset tan grande que no entre en la memoria del disco, pues con un conjunto de datos iterable no hace falta descargárselo entero ya que se irán descargando partes a medida que se vayan necesitando
Conjuntos de datos normales
Como su nombre indica, en un conjunto de datos hay muchos datos, por lo que podemos hacer una indexación
InputPythonfrom datasets import load_datasetopus100 = load_dataset("opus100", "en-es", split="train")Copied
InputPythonopus100[1]Copied
{'translation': {'en': "I'm out of here.", 'es': 'Me voy de aquí.'}}
InputPythonopus100[1:10]Copied
{'translation': [{'en': "I'm out of here.", 'es': 'Me voy de aquí.'},{'en': 'One time, I swear I pooped out a stick of chalk.','es': 'Una vez, juro que cagué una barra de tiza.'},{'en': 'And I will move, do you understand me?','es': 'Y prefiero mudarme, ¿Entiendes?'},{'en': '- Thank you, my lord.', 'es': '- Gracias.'},{'en': 'You have to help me.', 'es': 'Debes ayudarme.'},{'en': 'Fuck this!', 'es': '¡Por la mierda!'},{'en': 'The safety and efficacy of MIRCERA therapy in other indications has not been established.','es': 'No se ha establecido la seguridad y eficacia del tratamiento con MIRCERA en otras indicaciones.'},{'en': 'You can stay if you want.','es': 'Así lo decidí, pueden quedarse si quieren.'},{'en': "Of course, when I say 'translating an idiom,' I do not mean literal translation, rather an equivalent idiomatic expression in the target language, or any other means to convey the meaning.",'es': "Por supuesto, cuando digo 'traducir un idioma', no me refiero a la traducción literal, más bien a una expresión equivalente idiomática de la lengua final, o cualquier otro medio para transmitir el significado."}]}
Hay que remarcar que hemos descargado el conjunto de datos de train, ya que si lo hubiésemos descargado todo nos daría un error
InputPythonfrom datasets import load_datasetopus100_all = load_dataset("opus100", "en-es")Copied
InputPythonopus100_all[1]Copied
---------------------------------------------------------------------------KeyError Traceback (most recent call last)Cell In[12], line 1----> 1 opus100_all[1]File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/datasets/dataset_dict.py:80, in DatasetDict.__getitem__(self, k)76 available_suggested_splits = [77 split for split in (Split.TRAIN, Split.TEST, Split.VALIDATION) if split in self78 ]79 suggested_split = available_suggested_splits[0] if available_suggested_splits else list(self)[0]---> 80 raise KeyError(81 f"Invalid key: {k}. Please first select a split. For example: "82 f"`my_dataset_dictionary['{suggested_split}'][{k}]`. "83 f"Available splits: {sorted(self)}"84 )KeyError: "Invalid key: 1. Please first select a split. For example: `my_dataset_dictionary['train'][1]`. Available splits: ['test', 'train', 'validation']"
Como vemos, nos dice que primero tenemos que elegir un split, así que en este caso que nos hemos descargado todo, se tendría que haber hecho así
InputPythonopus100_all["train"][1]Copied
{'translation': {'en': "I'm out of here.", 'es': 'Me voy de aquí.'}}
También podemos indexar por alguna de las features, primero veamos cuáles son
InputPythonfeatures = opus100.featuresfeaturesCopied
{'translation': Translation(languages=['en', 'es'], id=None)}
Vemos que es translation
InputPythonopus100["translation"]Copied
[{'en': "It was the asbestos in here, that's what did it!",'es': 'Fueron los asbestos aquí. ¡Eso es lo que ocurrió!'},{'en': "I'm out of here.", 'es': 'Me voy de aquí.'},{'en': 'One time, I swear I pooped out a stick of chalk.','es': 'Una vez, juro que cagué una barra de tiza.'},{'en': 'And I will move, do you understand me?','es': 'Y prefiero mudarme, ¿Entiendes?'},{'en': '- Thank you, my lord.', 'es': '- Gracias.'},{'en': 'You have to help me.', 'es': 'Debes ayudarme.'},{'en': 'Fuck this!', 'es': '¡Por la mierda!'},{'en': 'The safety and efficacy of MIRCERA therapy in other indications has not been established.','es': 'No se ha establecido la seguridad y eficacia del tratamiento con MIRCERA en otras indicaciones.'},{'en': 'You can stay if you want.','es': 'Así lo decidí, pueden quedarse si quieren.'},{'en': "Of course, when I say 'translating an idiom,' I do not mean literal translation, rather an equivalent idiomatic expression in the target language, or any other means to convey the meaning.",'es': "Por supuesto, cuando digo 'traducir un idioma', no me refiero a la traducción literal, más bien a una expresión equivalente idiomática de la lengua final, o cualquier otro medio para transmitir el significado."},{'en': 'Norman.', 'es': 'Norman.'},{'en': "- I'm not stupid.", 'es': '- Yo no soy estúpido.'},{'en': 'Sorry, a weird gas bubble for a sec.','es': 'Perdón, he tenido una burbuja de gas extraño un momentito'},...'es': '- ¿Qué parte no entiendes?'},{'en': 'Is it anything like your last Christmas letter?', 'es': 'Sí, bueno.'},{'en': 'Mike.', 'es': 'Mike.'},{'en': 'The haemoglobin should be measured every one or two weeks until it is stable.','es': 'La hemoglobina se medirá cada una o dos semanas hasta que se estabilice.'},{'en': 'Yeah, buddy!', 'es': '- ¡Sí, amigo!'},{'en': "That's not it.", 'es': 'No se trata de eso.'},{'en': 'Come on.', 'es': 'Vamos.'},{'en': 'I knew this would happen.', 'es': 'Sabía que esto sucedería.'},...]
Como vemos obtenemos una lista con muchos pares de traducciones entre inglés y español, por lo que si quisiésemos la primera podríamos estar tentados de hacer opus100["translation"][0], pero hagamos unas mediciones de tiempo
InputPythonfrom time import timet0 = time()opus100["translation"][0]t = time()print(f"Tiempo indexando primero por feature y luego por posición: {t-t0} segundos")t0 = time()opus100[0]["translation"]t = time()print(f"Tiempo indexando primero por posición y luego por feature: {t-t0} segundos")Copied
Tiempo indexando primero por feature y luego por posición: 6.145161390304565 segundosTiempo indexando primero por posición y luego por feature: 0.00044727325439453125 segundos
Como se puede ver es mucho más rápido indexar primero por posición y luego por feature, esto es porque si hacemos opus100["translation"] obtenemos todos los pares de traducciones del dataset y luego nos quedamos con el primero, mientras que si hacemos opus100[0] obtenemos el primer elemento del dataset y luego ya solo nos quedamos con la feature que queramos.
Por eso es importante indexar primero por posición y luego por feature
Veamos ahora un ejemplo de un par de traducciones
InputPythonopus100[0]["translation"]Copied
{'en': "It was the asbestos in here, that's what did it!",'es': 'Fueron los asbestos aquí. ¡Eso es lo que ocurrió!'}
Conjuntos de datos iterables (streaming)
Como hemos dicho, el conjunto de datos iterable se va descargando a medida que vamos necesitando los datos y no todos de una vez, para poder hacer esto hay que añadir el parámetro streaming=True a la función load_dataset

InputPythonfrom datasets import load_datasetiterable_dataset = load_dataset("food101", split="train", streaming=True)for example in iterable_dataset:print(example)breakCopied
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=384x512 at 0x7F9878371AD0>, 'label': 6}
A diferencia de los conjuntos de datos normales, con los conjuntos de datos iterables no se puede hacer indexaciones ni slicing, ya que, como no lo tenemos cargado en memoria, no podemos coger partes del conjunto
Para ir iterando por un conjunto de datos iterable se tiene que hacer con un for como hemos hecho antes, pero cuando solo se quiere coger el siguiente elemento se tiene que hacer con las funciones next() e iter() de Python.
Con la función next() convertimos el conjunto de datos en un tipo de dato iterable de Python. Y con la función next() obtenemos el siguiente elemento del tipo de dato iterable. Todo esto está explicado mejor en el post de Introducción a Python
InputPythonnext(iter(iterable_dataset))Copied
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=384x512>,'label': 6}
Sin embargo, si lo que queremos es obtener varios elementos nuevos del dataset lo hacemos mediante la función list() y el método take()
Con el método take() le decimos al conjunto de datos iterable cuántos elementos nuevos queremos. Mientras que con la función list() convertimos esos datos en una lista
InputPythonlist(iterable_dataset.take(3))Copied
[{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=384x512>,'label': 6},{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=512x512>,'label': 6},{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=512x383>,'label': 6}]
Preprocesado de los datos
Cuando tenemos un dataset normalmente hay que hacer un preprocesamiento de los datos, por ejemplo a veces tenemos que quitar caracteres inválidos, etc. La librería dataset da esa funcionalidad mediante el método map
Primero vamos a instanciar un dataset y un tokenizador preentrenado, para instanciar el tokenizador usamos la librería transformers y no la librería tokenizers, ya que con la librería transformers podemos instanciar un tokenizador preentrenado y con la librería tokenizers tendríamos que crear el tokenizador desde cero
InputPythonfrom transformers import AutoTokenizerfrom datasets import load_datasettokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")dataset = load_dataset("rotten_tomatoes", split="train")Copied
Vamos a ver las keys del dataset
InputPythondataset[0].keys()Copied
dict_keys(['text', 'label'])
Ahora veamos un ejemplo del dataset
InputPythondataset[0]Copied
{'text': 'the rock is destined to be the 21st century's new " conan " and that he's going to make a splash even greater than arnold schwarzenegger , jean-claud van damme or steven segal .','label': 1}
Tokenicemos el texto
InputPythontokenizer(dataset[0]["text"])Copied
{'input_ids': [101, 1996, 2600, 2003, 16036, 2000, 2022, 1996, 7398, 2301, 1005, 1055, 2047, 1000, 16608, 1000, 1998, 2008, 2002, 1005, 1055, 2183, 2000, 2191, 1037, 17624, 2130, 3618, 2084, 7779, 29058, 8625, 13327, 1010, 3744, 1011, 18856, 19513, 3158, 5477, 4168, 2030, 7112, 16562, 2140, 1012, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
Cuando vamos a entrenar un modelo de lenguaje hemos visto que no le podemos pasar el texto, sino los tokens, por lo que vamos a hacer un preprocesado del dataset tokenizando todos los textos
Primero creamos una función que tokenice un texto de entrada
InputPythondef tokenization(example):return tokenizer(example["text"])Copied
Ahora, como hemos dicho, con el método map podemos aplicar una función a todos los elementos de un dataset. Además usamos la variable batched=True para que se aplique la función a batches de texto y no de uno en uno para ir más rápido
InputPythondataset = dataset.map(tokenization, batched=True)Copied
Veamos ahora las keys del dataset
InputPythondataset[0].keys()Copied
dict_keys(['text', 'label', 'input_ids', 'token_type_ids', 'attention_mask'])
Como vemos se han añadido nuevas keys al dataset, que son las que se han añadido al tokenizar el texto
Volvamos a ver el mismo ejemplo de antes
InputPythondataset[0]Copied
{'text': 'the rock is destined to be the 21st century's new " conan " and that he's going to make a splash even greater than arnold schwarzenegger , jean-claud van damme or steven segal .','label': 1,'input_ids': [101,1996,2600,2003,16036,2000,2022,1996,7398,2301,1005,1055,2047,1000,16608,1000,1998,2008,...1,1,1,1,1,1,1,1,1,1]}
Es mucho más extenso que antes
Formateo del dataset
Hemos realizado la tokenización para poder usar el dataset con un modelo de lenguaje, pero si nos fijamos, el tipo de dato de cada key es una lista
InputPythontype(dataset[0]["text"]), type(dataset[0]["label"]), type(dataset[0]["input_ids"]), type(dataset[0]["token_type_ids"]), type(dataset[0]["attention_mask"])Copied
(str, int, list, list, list)
Sin embargo, para entrenar necesitamos que sean tensores, así que datasets ofrece un método para asignar el formato de los datos de los datasets, que es el método set_format
InputPythondataset.set_format(type="torch", columns=["input_ids", "token_type_ids", "attention_mask", "label"])dataset.format['type']Copied
'torch'
Volvamos a ver las keys del dataset
InputPythondataset[0].keys()Copied
dict_keys(['label', 'input_ids', 'token_type_ids', 'attention_mask'])
Como vemos, al hacer el formateo, ya no tenemos la key text, y realmente no la necesitamos
Ahora vemos el tipo de dato de cada key
InputPythontype(dataset[0]["label"]), type(dataset[0]["input_ids"]), type(dataset[0]["token_type_ids"]), type(dataset[0]["attention_mask"])Copied
(torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor)
Todos son tensores, perfecto para entrenar
En este punto podríamos guardar el dataset para no tener que hacer siempre este preprocesamiento
Crear un dataset
A la hora de crear un dataset huggingface nos da tres opciones, a través de carpetas, pero a la hora de escribir este post, el hacerlo por carpetas solo es válido para datasets de imagen o audio.
Los otros dos métodos son mediante generadores y mediante diccionarios, así que vamos a verlos
Crear un dataset desde un generador
Supongamos que tenemos los siguientes pares de frases en inglés y español:
InputPythonprint("El perro ha comido hoy - The dog has eaten today")print("El gato ha dormido hoy - The cat has slept today")print("El pájaro ha volado hoy - The bird has flown today")print("El pez ha nadado hoy - The fish has swum today")print("El caballo ha galopado hoy - The horse has galloped today")print("El cerdo ha corrido hoy - The pig has run today")print("El ratón ha saltado hoy - The mouse has jumped today")print("El elefante ha caminado hoy - The elephant has walked today")print("El león ha rugido hoy - The lion has roared today")print("El tigre ha cazado hoy - The tiger has hunted today")Copied
El perro ha comido hoy - The dog has eaten todayEl gato ha dormido hoy - The cat has slept todayEl pájaro ha volado hoy - The bird has flown todayEl pez ha nadado hoy - The fish has swum todayEl caballo ha galopado hoy - The horse has galloped todayEl cerdo ha corrido hoy - The pig has run todayEl ratón ha saltado hoy - The mouse has jumped todayEl elefante ha caminado hoy - The elephant has walked todayEl león ha rugido hoy - The lion has roared todayEl tigre ha cazado hoy - The tiger has hunted today
No me juzgues, lo ha generado copilot
Podemos crear un dataset mediante un generador, para ello importamos Dataset y usamos su método from_generator.
InputPythonfrom datasets import Datasetdef generator():yield {"es": "El perro ha comido hoy", "en": "The dog has eaten today"}yield {"es": "El gato ha dormido hoy", "en": "The cat has slept today"}yield {"es": "El pájaro ha volado hoy", "en": "The bird has flown today"}yield {"es": "El pez ha nadado hoy", "en": "The fish has swum today"}yield {"es": "El caballo ha galopado hoy", "en": "The horse has galloped today"}yield {"es": "El cerdo ha corrido hoy", "en": "The pig has run today"}yield {"es": "El ratón ha saltado hoy", "en": "The mouse has jumped today"}yield {"es": "El elefante ha caminado hoy", "en": "The elephant has walked today"}yield {"es": "El león ha rugido hoy", "en": "The lion has roared today"}yield {"es": "El tigre ha cazado hoy", "en": "The tiger has hunted today"}dataset = Dataset.from_generator(generator)datasetCopied
Generating train split: 0 examples [00:00, ? examples/s]
Dataset({features: ['es', 'en'],num_rows: 10})
Lo bueno de utilizar el método from_generator es que podemos crear un conjunto de datos iterables, que como hemos visto antes, no necesitan ser cargados enteros en memoria. Para ello lo que tenemos que hacer es importar el módulo IterableDataset, en vez del módulo Dataset, y volver a usar el método from_generator
InputPythonfrom datasets import IterableDatasetdef generator():yield {"es": "El perro ha comido hoy", "en": "The dog has eaten today"}yield {"es": "El gato ha dormido hoy", "en": "The cat has slept today"}yield {"es": "El pájaro ha volado hoy", "en": "The bird has flown today"}yield {"es": "El pez ha nadado hoy", "en": "The fish has swum today"}yield {"es": "El caballo ha galopado hoy", "en": "The horse has galloped today"}yield {"es": "El cerdo ha corrido hoy", "en": "The pig has run today"}yield {"es": "El ratón ha saltado hoy", "en": "The mouse has jumped today"}yield {"es": "El elefante ha caminado hoy", "en": "The elephant has walked today"}yield {"es": "El león ha rugido hoy", "en": "The lion has roared today"}yield {"es": "El tigre ha cazado hoy", "en": "The tiger has hunted today"}iterable_dataset = IterableDataset.from_generator(generator)iterable_datasetCopied
IterableDataset({features: ['es', 'en'],n_shards: 1})
Ahora podemos ir obteniendo datos uno a uno
InputPythonnext(iter(iterable_dataset))Copied
{'es': 'El perro ha comido hoy', 'en': 'The dog has eaten today'}
O en batches
InputPythonlist(iterable_dataset.take(3))Copied
[{'es': 'El perro ha comido hoy', 'en': 'The dog has eaten today'},{'es': 'El gato ha dormido hoy', 'en': 'The cat has slept today'},{'es': 'El pájaro ha volado hoy', 'en': 'The bird has flown today'}]
Crear un dataset desde un diccionario
Puede ser que tengamos los datos guardados en un diccionario, en ese caso podemos crear un dataset importando el módulo Dataset y utilizando el método from_dict
InputPythonfrom datasets import Datasettranslations_dict = {"es": ["El perro ha comido hoy","El gato ha dormido hoy","El pájaro ha volado hoy","El pez ha nadado hoy","El caballo ha galopado hoy","El cerdo ha corrido hoy","El ratón ha saltado hoy","El elefante ha caminado hoy","El león ha rugido hoy","El tigre ha cazado hoy"],"en": ["The dog has eaten today","The cat has slept today","The bird has flown today","The fish has swum today","The horse has galloped today","The pig has run today","The mouse has jumped today","The elephant has walked today","The lion has roared today","The tiger has hunted today"]}dataset = Dataset.from_dict(translations_dict)datasetCopied
Dataset({features: ['es', 'en'],num_rows: 10})
Sin embargo, al crear un dataset desde un diccionario no podemos crear un dataset iterable
Compartir el dataset en el Hub de Hugging Face
Una vez tenemos el dataset creado podemos subirlo a nuestro espacio en el Hub de Hugging Face para que otros lo puedan usar. Para ello es necesario tener una cuenta en Hugging Face
Logging
Para poder subir el dataset primero nos tenemos que loguear.
Se puede hacer a través de la terminal con
huggingface-cli loginO a través del notebook, habiendo instalado antes la librería huggingface_hub con
pip install huggingface_hubAhora podemos loguearnos con la función notebook_login, que creará una pequeña interfaz gráfica en la que tenemos que introducir un token de Hugging Face
Para crear un token hay que ir a la página de settings/tokens de nuestra cuenta, nos aparecerá algo así
Le damos a New token y nos aparecerá una ventana para crear un nuevo token
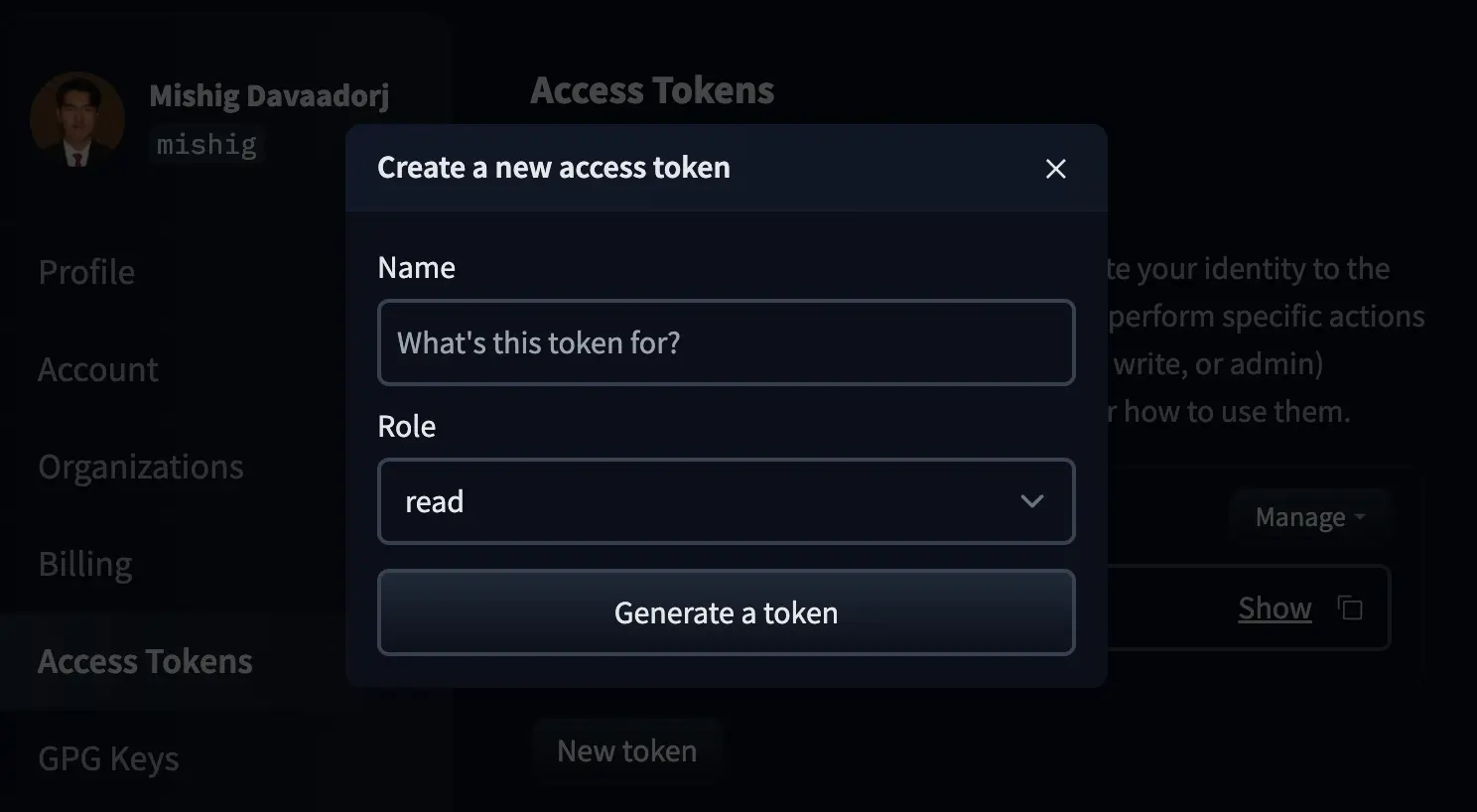
Le damos un nombre al token y lo creamos con el rol write.
Una vez creado lo copiamos
InputPythonfrom huggingface_hub import notebook_loginnotebook_login()Copied
VBox(children=(HTML(value='<center> <img src=https://huggingface.co/front/assets/huggingface_logo-noborder.sv…
Subida del dataset
Una vez nos hemos logueado, podemos subir el dataset simplemente con el método push_to_hub, dando un nombre para el dataset
InputPythondataset.push_to_hub("dataset_notebook_demo")Copied
Uploading the dataset shards: 0%| | 0/1 [00:00<?, ?it/s]
Creating parquet from Arrow format: 0%| | 0/1 [00:00<?, ?ba/s]
CommitInfo(commit_url='https://huggingface.co/datasets/Maximofn/dataset_notebook_demo/commit/71f1ad2cffd6f424f33d45fd992f817d8f76dc0e', commit_message='Upload dataset', commit_description='', oid='71f1ad2cffd6f424f33d45fd992f817d8f76dc0e', pr_url=None, pr_revision=None, pr_num=None)
Si ahora vamos a nuestro Hub podemos ver que se ha subido el dataset
Si ahora entramos a la dataset card a ver
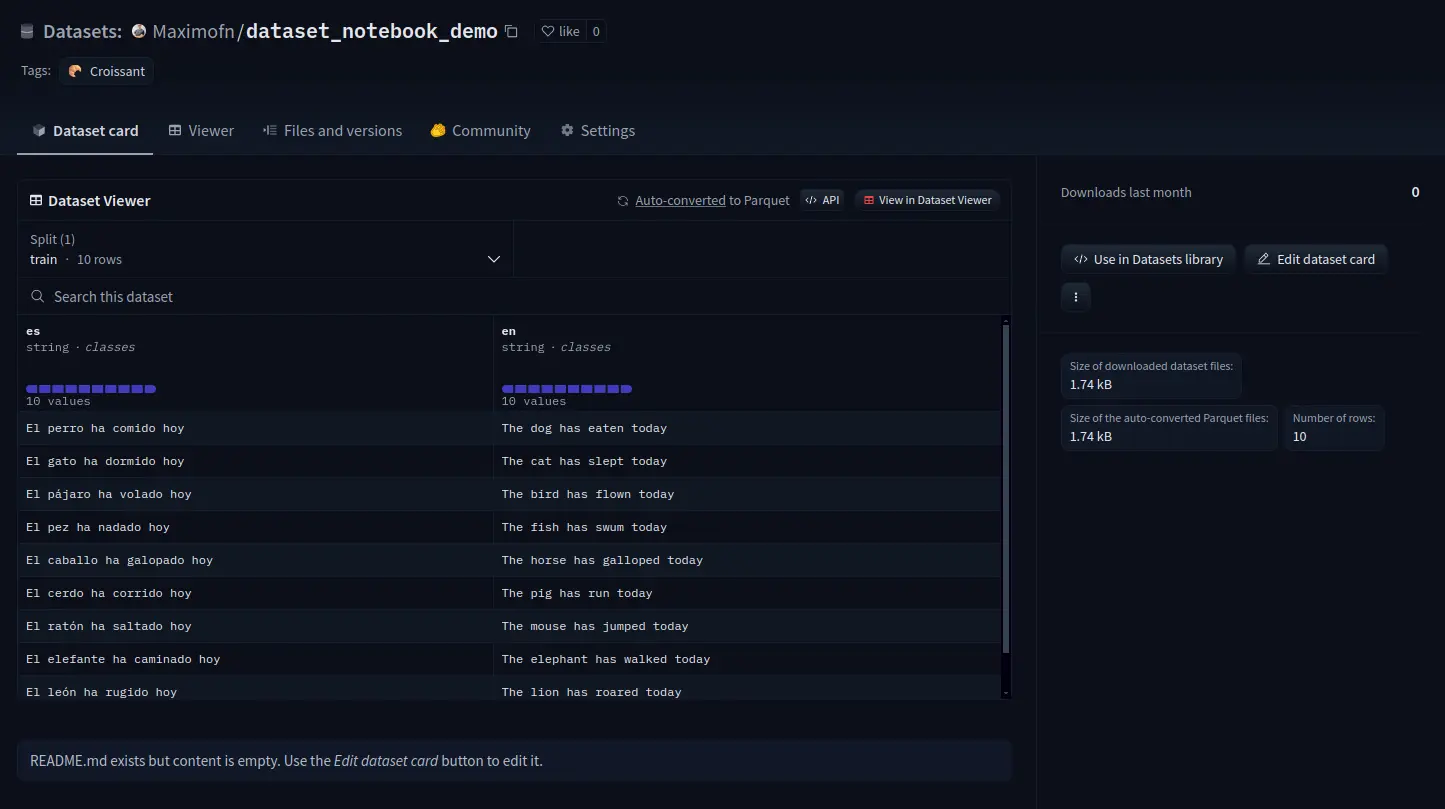
Vemos que todo está sin rellenar, así que habría que completar la información
Subida del dataset de manera privada
Si queremos que solo nosotros o la gente de nuestra organización tenga acceso al dataset, tenemos que añadir el atributo private=true al método push_to_hub
InputPythondataset.push_to_hub("dataset_notebook_demo_private", private=True)Copied
Uploading the dataset shards: 0%| | 0/1 [00:00<?, ?it/s]
Creating parquet from Arrow format: 0%| | 0/1 [00:00<?, ?ba/s]
CommitInfo(commit_url='https://huggingface.co/datasets/Maximofn/dataset_notebook_demo_private/commit/c90525f6aa5f1c8c44da3cde2b9599828abd8233', commit_message='Upload dataset', commit_description='', oid='c90525f6aa5f1c8c44da3cde2b9599828abd8233', pr_url=None, pr_revision=None, pr_num=None)
Si ahora vamos a nuestro Hub podemos ver que se ha subido el dataset
Si ahora entramos a la dataset card a ver
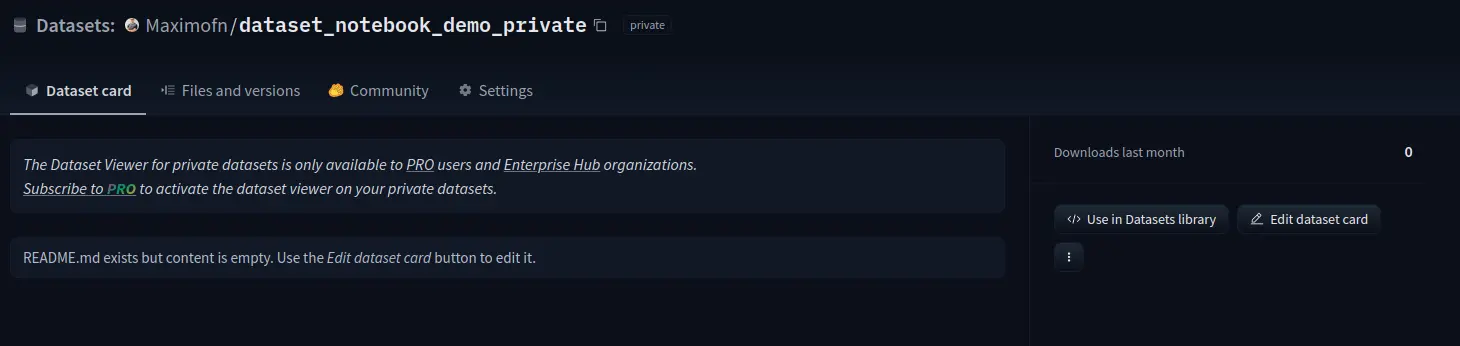
Vemos que todo está sin rellenar, así que habría que completar la información. También podemos ver que en los datasets privados no se pueden ver los datos
Hub como repositorio Git
En Hugging Face tanto los modelos, como los espacios, como los datasets son repositorios de git, por lo que se puede trabajar con ellos como eso. Es decir, puedes clonar, hacer forks, pull requests, etc.
Pero otra gran ventaja de esto es que puedes usar un dataset en una versión determinada
InputPythonfrom datasets import load_datasetds = load_dataset("yelp_review_full", revision="393e083")Copied
config.json: 0%| | 0.00/433 [00:00<?, ?B/s]
pytorch_model.bin: 0%| | 0.00/436M [00:00<?, ?B/s]
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['classifier.bias', 'classifier.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.















