A biblioteca Hugging Face datasets é uma biblioteca muito útil para trabalhar com conjuntos de dados, tanto com todos os conjuntos de dados no [hub] (https://huggingface.co/datasets) quanto com seus próprios conjuntos de dados.
Este caderno foi traduzido automaticamente para torná-lo acessível a mais pessoas, por favor me avise se você vir algum erro de digitação..
Instalação
Para usar a biblioteca Hugging Face datasets, primeiro precisamos instalá-la com o pip
pip install datasetsou com conda
conda install -c huggingface -c conda-forge datasetsCarregando um conjunto de dados do hub
O Hugging Face tem um [hub] (https://huggingface.co/datasets) com um grande número de conjuntos de dados, classificados por tarefas ou tarefas.
Obter informações sobre o conjunto de dados
Antes de fazer download de um conjunto de dados, é útil obter as informações dele. A melhor maneira é entrar no hub e visualizar suas informações, mas, se não for possível, você pode obter as informações carregando primeiro um gerador de conjunto de dados com a função load_dataset_builder, que não envolve download, e depois obtendo suas informações com o método info.
InputPythonfrom datasets import load_dataset_builderds_builder = load_dataset_builder("yelp_review_full")info = ds_builder.infoinfoCopied
DatasetInfo(description='', citation='', homepage='', license='', features={'label': ClassLabel(names=['1 star', '2 star', '3 stars', '4 stars', '5 stars'], id=None), 'text': Value(dtype='string', id=None)}, post_processed=None, supervised_keys=None, task_templates=None, builder_name='parquet', dataset_name='yelp_review_full', config_name='yelp_review_full', version=0.0.0, splits={'train': SplitInfo(name='train', num_bytes=483811554, num_examples=650000, shard_lengths=None, dataset_name=None), 'test': SplitInfo(name='test', num_bytes=37271188, num_examples=50000, shard_lengths=None, dataset_name=None)}, download_checksums=None, download_size=322952369, post_processing_size=None, dataset_size=521082742, size_in_bytes=None)
Você pode ver, por exemplo, as classes
InputPythoninfo.featuresCopied
{'label': ClassLabel(names=['1 star', '2 star', '3 stars', '4 stars', '5 stars'], id=None),'text': Value(dtype='string', id=None)}
Download do conjunto de dados
Se estivermos satisfeitos com o conjunto de dados escolhido, poderemos baixá-lo com a função load_dataset.
InputPythonfrom datasets import load_datasetds = load_dataset("yelp_review_full")dsCopied
DatasetDict({train: Dataset({features: ['label', 'text'],num_rows: 650000})test: Dataset({features: ['label', 'text'],num_rows: 50000})})
Divisões
Como você pode ver, quando fizemos o download do conjunto de dados, vimos que o conjunto train e o conjunto test foram baixados. Se quisermos saber quais conjuntos um conjunto de dados tem, podemos usar a função get_dataset_split_names.
InputPythonfrom datasets import get_dataset_split_namessplit_names = get_dataset_split_names("yelp_review_full")split_namesCopied
['train', 'test']
Há conjuntos de dados que também têm um conjunto de "validação".
InputPythonfrom datasets import get_dataset_split_namessplit_names = get_dataset_split_names("rotten_tomatoes")split_namesCopied
['train', 'validation', 'test']
Como os conjuntos de dados têm conjuntos de dados, podemos fazer download de apenas um deles com o argumento split.
InputPythonfrom datasets import load_datasetds = load_dataset("yelp_review_full", split="train")dsCopied
Dataset({features: ['label', 'text'],num_rows: 650000})
Configurações
Alguns conjuntos de dados têm subconjuntos de conjuntos de dados. Para ver os subconjuntos de um conjunto de dados, podemos usar a função get_dataset_config_names.
InputPythonfrom datasets import get_dataset_config_namesconfigs = get_dataset_config_names("opus100")configsCopied
['af-en','am-en','an-en','ar-de','ar-en','ar-fr','ar-nl','ar-ru','ar-zh','as-en','az-en','be-en','bg-en','bn-en','br-en','bs-en','ca-en','cs-en','cy-en','da-en',...'en-yi','en-yo','en-zh','en-zu','fr-nl','fr-ru','fr-zh','nl-ru','nl-zh','ru-zh']
Esse conjunto de dados tem subconjuntos de traduções de um idioma para outro.
Se você quiser baixar apenas um subconjunto de um conjunto de dados, basta especificá-lo.
InputPythonfrom datasets import load_datasetopus100en_es = load_dataset("opus100", "en-es")opus100en_esCopied
DatasetDict({test: Dataset({features: ['translation'],num_rows: 2000})train: Dataset({features: ['translation'],num_rows: 1000000})validation: Dataset({features: ['translation'],num_rows: 2000})})
Código remoto
Todos os arquivos e códigos carregados no Hub são verificados quanto a malware, um script é executado para verificá-los. Mas se você quiser fazer o download mais rápido sem a execução do script, deverá definir o parâmetro trust_remote_code=True. Isso só é aconselhável em um conjunto de dados em que você confia ou se quiser fazer a verificação por conta própria.
InputPythonfrom datasets import load_datasetopus100 = load_dataset("opus100", "en-es", trust_remote_code=True)opus100Copied
DatasetDict({test: Dataset({features: ['translation'],num_rows: 2000})train: Dataset({features: ['translation'],num_rows: 1000000})validation: Dataset({features: ['translation'],num_rows: 2000})})
Conhecendo os conjuntos de dados
No hugging face, há dois conjuntos de dados: conjuntos de dados normais e conjuntos de dados iteráveis, que são conjuntos de dados que não precisam ser carregados como um todo. Isso significa que, suponhamos que você tenha um conjunto de dados tão grande que não caiba na memória do disco, com um conjunto de dados iterável você não precisa descarregar todo o conjunto de dados, pois descarregará as partes à medida que precisar delas.
Conjuntos de dados normais
Como o nome sugere, há muitos dados em um conjunto de dados, portanto, podemos fazer uma indexação
InputPythonfrom datasets import load_datasetopus100 = load_dataset("opus100", "en-es", split="train")Copied
InputPythonopus100[1]Copied
{'translation': {'en': "I'm out of here.", 'es': 'Me voy de aquí.'}}
InputPythonopus100[1:10]Copied
{'translation': [{'en': "I'm out of here.", 'es': 'Me voy de aquí.'},{'en': 'One time, I swear I pooped out a stick of chalk.','es': 'Una vez, juro que cagué una barra de tiza.'},{'en': 'And I will move, do you understand me?','es': 'Y prefiero mudarme, ¿Entiendes?'},{'en': '- Thank you, my lord.', 'es': '- Gracias.'},{'en': 'You have to help me.', 'es': 'Debes ayudarme.'},{'en': 'Fuck this!', 'es': '¡Por la mierda!'},{'en': 'The safety and efficacy of MIRCERA therapy in other indications has not been established.','es': 'No se ha establecido la seguridad y eficacia del tratamiento con MIRCERA en otras indicaciones.'},{'en': 'You can stay if you want.','es': 'Así lo decidí, pueden quedarse si quieren.'},{'en': "Of course, when I say 'translating an idiom,' I do not mean literal translation, rather an equivalent idiomatic expression in the target language, or any other means to convey the meaning.",'es': "Por supuesto, cuando digo 'traducir un idioma', no me refiero a la traducción literal, más bien a una expresión equivalente idiomática de la lengua final, o cualquier otro medio para transmitir el significado."}]}
É importante observar que fizemos o download do conjunto de dados train, pois se tivéssemos feito o download de tudo, receberíamos um erro.
InputPythonfrom datasets import load_datasetopus100_all = load_dataset("opus100", "en-es")Copied
InputPythonopus100_all[1]Copied
---------------------------------------------------------------------------KeyError Traceback (most recent call last)Cell In[12], line 1----> 1 opus100_all[1]File ~/miniconda3/envs/nlp/lib/python3.11/site-packages/datasets/dataset_dict.py:80, in DatasetDict.__getitem__(self, k)76 available_suggested_splits = [77 split for split in (Split.TRAIN, Split.TEST, Split.VALIDATION) if split in self78 ]79 suggested_split = available_suggested_splits[0] if available_suggested_splits else list(self)[0]---> 80 raise KeyError(81 f"Invalid key: {k}. Please first select a split. For example: "82 f"`my_dataset_dictionary['{suggested_split}'][{k}]`. "83 f"Available splits: {sorted(self)}"84 )KeyError: "Invalid key: 1. Please first select a split. For example: `my_dataset_dictionary['train'][1]`. Available splits: ['test', 'train', 'validation']"
Como podemos ver, ele nos diz que primeiro temos que escolher uma divisão, portanto, nesse caso em que baixamos tudo, isso deveria ter sido feito da seguinte forma
InputPythonopus100_all["train"][1]Copied
{'translation': {'en': "I'm out of here.", 'es': 'Me voy de aquí.'}}
Também podemos indexar por alguns dos recursos, mas primeiro vamos ver quais são eles.
InputPythonfeatures = opus100.featuresfeaturesCopied
{'translation': Translation(languages=['en', 'es'], id=None)}
Vemos que se trata de "tradução".
InputPythonopus100["translation"]Copied
[{'en': "It was the asbestos in here, that's what did it!",'es': 'Fueron los asbestos aquí. ¡Eso es lo que ocurrió!'},{'en': "I'm out of here.", 'es': 'Me voy de aquí.'},{'en': 'One time, I swear I pooped out a stick of chalk.','es': 'Una vez, juro que cagué una barra de tiza.'},{'en': 'And I will move, do you understand me?','es': 'Y prefiero mudarme, ¿Entiendes?'},{'en': '- Thank you, my lord.', 'es': '- Gracias.'},{'en': 'You have to help me.', 'es': 'Debes ayudarme.'},{'en': 'Fuck this!', 'es': '¡Por la mierda!'},{'en': 'The safety and efficacy of MIRCERA therapy in other indications has not been established.','es': 'No se ha establecido la seguridad y eficacia del tratamiento con MIRCERA en otras indicaciones.'},{'en': 'You can stay if you want.','es': 'Así lo decidí, pueden quedarse si quieren.'},{'en': "Of course, when I say 'translating an idiom,' I do not mean literal translation, rather an equivalent idiomatic expression in the target language, or any other means to convey the meaning.",'es': "Por supuesto, cuando digo 'traducir un idioma', no me refiero a la traducción literal, más bien a una expresión equivalente idiomática de la lengua final, o cualquier otro medio para transmitir el significado."},{'en': 'Norman.', 'es': 'Norman.'},{'en': "- I'm not stupid.", 'es': '- Yo no soy estúpido.'},{'en': 'Sorry, a weird gas bubble for a sec.','es': 'Perdón, he tenido una burbuja de gas extraño un momentito'},...'es': '- ¿Qué parte no entiendes?'},{'en': 'Is it anything like your last Christmas letter?', 'es': 'Sí, bueno.'},{'en': 'Mike.', 'es': 'Mike.'},{'en': 'The haemoglobin should be measured every one or two weeks until it is stable.','es': 'La hemoglobina se medirá cada una o dos semanas hasta que se estabilice.'},{'en': 'Yeah, buddy!', 'es': '- ¡Sí, amigo!'},{'en': "That's not it.", 'es': 'No se trata de eso.'},{'en': 'Come on.', 'es': 'Vamos.'},{'en': 'I knew this would happen.', 'es': 'Sabía que esto sucedería.'},...]
Como podemos ver, obtemos uma lista com muitos pares de traduções entre inglês e espanhol, portanto, se quiséssemos a primeira, poderíamos nos sentir tentados a fazer opus100["translation"][0], mas vamos fazer algumas medições de tempo.
InputPythonfrom time import timet0 = time()opus100["translation"][0]t = time()print(f"Tiempo indexando primero por feature y luego por posición: {t-t0} segundos")t0 = time()opus100[0]["translation"]t = time()print(f"Tiempo indexando primero por posición y luego por feature: {t-t0} segundos")Copied
Tiempo indexando primero por feature y luego por posición: 6.145161390304565 segundosTiempo indexando primero por posición y luego por feature: 0.00044727325439453125 segundos
Como você pode ver, é muito mais rápido indexar primeiro por posição e depois por recurso, porque se fizermos opus100["translation"], obteremos todos os pares de tradução do conjunto de dados e manteremos o primeiro, enquanto que se fizermos opus100[0], obteremos o primeiro elemento do conjunto de dados e manteremos apenas o recurso que desejamos.
Por isso, é importante indexar primeiro por posição e depois por recurso.
Vejamos agora um exemplo de duas traduções
InputPythonopus100[0]["translation"]Copied
{'en': "It was the asbestos in here, that's what did it!",'es': 'Fueron los asbestos aquí. ¡Eso es lo que ocurrió!'}
Conjuntos de dados iteráveis (streaming)
Como já dissemos, o download do conjunto de dados iterável é feito à medida que precisamos dos dados e não de uma só vez. Para isso, precisamos adicionar o parâmetro streaming=True à função load_dataset.

InputPythonfrom datasets import load_datasetiterable_dataset = load_dataset("food101", split="train", streaming=True)for example in iterable_dataset:print(example)breakCopied
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=384x512 at 0x7F9878371AD0>, 'label': 6}
Diferentemente dos conjuntos de dados normais, com os conjuntos de dados iteráveis não é possível fazer indexação ou fatiamento, porque, como não os temos carregados na memória, não podemos pegar partes do conjunto.
Para iterar em um conjunto de dados iterável, você deve fazer isso com um for, como fizemos anteriormente, mas quando quiser apenas obter o próximo elemento, você deve fazer isso com as funções next() e iter() do Python.
Com a função next(), convertemos o conjunto de dados em um tipo de dados iterável do Python. E com a função next() obtemos o próximo elemento do tipo de dados iterável. Tudo isso é melhor explicado na postagem Introduction to Python.
InputPythonnext(iter(iterable_dataset))Copied
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=384x512>,'label': 6}
No entanto, se o que queremos é obter vários elementos novos do conjunto de dados, faremos isso usando a função list() e o método take().
Com o método take(), informamos ao conjunto de dados iterável quantos elementos novos desejamos. Já com a função list(), convertemos esses dados em uma lista.
InputPythonlist(iterable_dataset.take(3))Copied
[{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=384x512>,'label': 6},{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=512x512>,'label': 6},{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=512x383>,'label': 6}]
Pré-processamento de dados
Quando temos um conjunto de dados, geralmente precisamos fazer algum pré-processamento dos dados, por exemplo, às vezes precisamos remover caracteres inválidos etc. A biblioteca dataset fornece essa funcionalidade por meio do método map.
Primeiro, vamos instanciar um conjunto de dados e um tokenizador pré-treinado. Para instanciar o tokenizador, usamos a biblioteca transformers e não a biblioteca tokenizers, porque com a biblioteca transformers podemos instanciar um tokenizador pré-treinado e, com a biblioteca tokenizers, teríamos que criar o tokenizador do zero.
InputPythonfrom transformers import AutoTokenizerfrom datasets import load_datasettokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")dataset = load_dataset("rotten_tomatoes", split="train")Copied
Vamos dar uma olhada nas "chaves" do conjunto de dados
InputPythondataset[0].keys()Copied
dict_keys(['text', 'label'])
Agora vamos dar uma olhada em um exemplo do conjunto de dados
InputPythondataset[0]Copied
{'text': 'the rock is destined to be the 21st century's new " conan " and that he's going to make a splash even greater than arnold schwarzenegger , jean-claud van damme or steven segal .','label': 1}
Vamos tokenizar o texto
InputPythontokenizer(dataset[0]["text"])Copied
{'input_ids': [101, 1996, 2600, 2003, 16036, 2000, 2022, 1996, 7398, 2301, 1005, 1055, 2047, 1000, 16608, 1000, 1998, 2008, 2002, 1005, 1055, 2183, 2000, 2191, 1037, 17624, 2130, 3618, 2084, 7779, 29058, 8625, 13327, 1010, 3744, 1011, 18856, 19513, 3158, 5477, 4168, 2030, 7112, 16562, 2140, 1012, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
Quando vamos treinar um modelo de linguagem, vimos que não podemos passar a ele o texto, mas apenas os tokens, portanto, faremos um pré-processamento do conjunto de dados para tokenizar todos os textos.
Primeiro, criamos uma função que tokeniza um texto de entrada.
InputPythondef tokenization(example):return tokenizer(example["text"])Copied
Agora, como dissemos, com o método map podemos aplicar uma função a todos os elementos de um conjunto de dados. Também usamos a variável batched=True para aplicar a função a lotes de texto, e não um a um, para sermos mais rápidos.
InputPythondataset = dataset.map(tokenization, batched=True)Copied
Vamos agora dar uma olhada nas "chaves" do conjunto de dados
InputPythondataset[0].keys()Copied
dict_keys(['text', 'label', 'input_ids', 'token_type_ids', 'attention_mask'])
Como podemos ver, novas chaves foram adicionadas ao conjunto de dados, que são aquelas adicionadas ao tokenizar o texto.
Vejamos novamente o mesmo exemplo anterior.
InputPythondataset[0]Copied
{'text': 'the rock is destined to be the 21st century's new " conan " and that he's going to make a splash even greater than arnold schwarzenegger , jean-claud van damme or steven segal .','label': 1,'input_ids': [101,1996,2600,2003,16036,2000,2022,1996,7398,2301,1005,1055,2047,1000,16608,1000,1998,2008,...1,1,1,1,1,1,1,1,1,1]}
Ele é muito maior do que antes
Formato do conjunto de dados
Temos tokenização para poder usar o conjunto de dados com um modelo de linguagem, mas se você observar o tipo de dados de cada chave, ele é uma lista.
InputPythontype(dataset[0]["text"]), type(dataset[0]["label"]), type(dataset[0]["input_ids"]), type(dataset[0]["token_type_ids"]), type(dataset[0]["attention_mask"])Copied
(str, int, list, list, list)
No entanto, para o treinamento, precisamos que eles sejam tensores, portanto, o datasets fornece um método para definir o formato dos dados dos conjuntos de dados, que é o método set_format.
InputPythondataset.set_format(type="torch", columns=["input_ids", "token_type_ids", "attention_mask", "label"])dataset.format['type']Copied
'torch'
Vamos dar uma olhada novamente nas "chaves" do conjunto de dados
InputPythondataset[0].keys()Copied
dict_keys(['label', 'input_ids', 'token_type_ids', 'attention_mask'])
Como podemos ver, ao formatar, não temos mais a chave texto e, na verdade, não precisamos dela.
Agora vemos o tipo de dados de cada chave.
InputPythontype(dataset[0]["label"]), type(dataset[0]["input_ids"]), type(dataset[0]["token_type_ids"]), type(dataset[0]["attention_mask"])Copied
(torch.Tensor, torch.Tensor, torch.Tensor, torch.Tensor)
Todos são tensionadores, perfeitos para treinamento
Nesse ponto, poderíamos salvar o conjunto de dados para não precisarmos fazer sempre esse pré-processamento.
Criar um conjunto de dados
Ao criar um conjunto de dados, o huggingface nos dá três opções, por meio de pastas, mas, no momento da redação desta postagem, fazê-lo por meio de pastas só é válido para conjuntos de dados de imagem ou áudio.
Os outros dois métodos são por meio de geradores e por meio de dicionários, portanto, vamos dar uma olhada neles.
Criando um conjunto de dados a partir de um gerador
Suponha que tenhamos os seguintes pares de frases em inglês e espanhol:
InputPythonprint("El perro ha comido hoy - The dog has eaten today")print("El gato ha dormido hoy - The cat has slept today")print("El pájaro ha volado hoy - The bird has flown today")print("El pez ha nadado hoy - The fish has swum today")print("El caballo ha galopado hoy - The horse has galloped today")print("El cerdo ha corrido hoy - The pig has run today")print("El ratón ha saltado hoy - The mouse has jumped today")print("El elefante ha caminado hoy - The elephant has walked today")print("El león ha rugido hoy - The lion has roared today")print("El tigre ha cazado hoy - The tiger has hunted today")Copied
El perro ha comido hoy - The dog has eaten todayEl gato ha dormido hoy - The cat has slept todayEl pájaro ha volado hoy - The bird has flown todayEl pez ha nadado hoy - The fish has swum todayEl caballo ha galopado hoy - The horse has galloped todayEl cerdo ha corrido hoy - The pig has run todayEl ratón ha saltado hoy - The mouse has jumped todayEl elefante ha caminado hoy - The elephant has walked todayEl león ha rugido hoy - The lion has roared todayEl tigre ha cazado hoy - The tiger has hunted today
Não me julgue, ele é gerado pelo copiloto
Podemos criar um conjunto de dados usando um gerador importando o Dataset e usando seu método from_generator.
InputPythonfrom datasets import Datasetdef generator():yield {"es": "El perro ha comido hoy", "en": "The dog has eaten today"}yield {"es": "El gato ha dormido hoy", "en": "The cat has slept today"}yield {"es": "El pájaro ha volado hoy", "en": "The bird has flown today"}yield {"es": "El pez ha nadado hoy", "en": "The fish has swum today"}yield {"es": "El caballo ha galopado hoy", "en": "The horse has galloped today"}yield {"es": "El cerdo ha corrido hoy", "en": "The pig has run today"}yield {"es": "El ratón ha saltado hoy", "en": "The mouse has jumped today"}yield {"es": "El elefante ha caminado hoy", "en": "The elephant has walked today"}yield {"es": "El león ha rugido hoy", "en": "The lion has roared today"}yield {"es": "El tigre ha cazado hoy", "en": "The tiger has hunted today"}dataset = Dataset.from_generator(generator)datasetCopied
Generating train split: 0 examples [00:00, ? examples/s]
Dataset({features: ['es', 'en'],num_rows: 10})
O bom de usar o método from_generator é que podemos criar um conjunto de dados iterável, que, como vimos anteriormente, não precisa ser carregado inteiro na memória. Para fazer isso, basta importar o módulo IterableDataset em vez do módulo Dataset e usar o método from_generator novamente.
InputPythonfrom datasets import IterableDatasetdef generator():yield {"es": "El perro ha comido hoy", "en": "The dog has eaten today"}yield {"es": "El gato ha dormido hoy", "en": "The cat has slept today"}yield {"es": "El pájaro ha volado hoy", "en": "The bird has flown today"}yield {"es": "El pez ha nadado hoy", "en": "The fish has swum today"}yield {"es": "El caballo ha galopado hoy", "en": "The horse has galloped today"}yield {"es": "El cerdo ha corrido hoy", "en": "The pig has run today"}yield {"es": "El ratón ha saltado hoy", "en": "The mouse has jumped today"}yield {"es": "El elefante ha caminado hoy", "en": "The elephant has walked today"}yield {"es": "El león ha rugido hoy", "en": "The lion has roared today"}yield {"es": "El tigre ha cazado hoy", "en": "The tiger has hunted today"}iterable_dataset = IterableDataset.from_generator(generator)iterable_datasetCopied
IterableDataset({features: ['es', 'en'],n_shards: 1})
Agora podemos pegar os dados um a um
InputPythonnext(iter(iterable_dataset))Copied
{'es': 'El perro ha comido hoy', 'en': 'The dog has eaten today'}
O em lotes
InputPythonlist(iterable_dataset.take(3))Copied
[{'es': 'El perro ha comido hoy', 'en': 'The dog has eaten today'},{'es': 'El gato ha dormido hoy', 'en': 'The cat has slept today'},{'es': 'El pájaro ha volado hoy', 'en': 'The bird has flown today'}]
Criando um conjunto de dados a partir de um dicionário
Talvez tenhamos os dados armazenados em um dicionário e, nesse caso, podemos criar um conjunto de dados importando o módulo Dataset e usando o método from_dict.
InputPythonfrom datasets import Datasettranslations_dict = {"es": ["El perro ha comido hoy","El gato ha dormido hoy","El pájaro ha volado hoy","El pez ha nadado hoy","El caballo ha galopado hoy","El cerdo ha corrido hoy","El ratón ha saltado hoy","El elefante ha caminado hoy","El león ha rugido hoy","El tigre ha cazado hoy"],"en": ["The dog has eaten today","The cat has slept today","The bird has flown today","The fish has swum today","The horse has galloped today","The pig has run today","The mouse has jumped today","The elephant has walked today","The lion has roared today","The tiger has hunted today"]}dataset = Dataset.from_dict(translations_dict)datasetCopied
Dataset({features: ['es', 'en'],num_rows: 10})
No entanto, ao criar um conjunto de dados a partir de um dicionário, não podemos criar um conjunto de dados iterável.
Compartilhe o conjunto de dados no Hub do Rosto Abraçado
Depois de criarmos o conjunto de dados, podemos carregá-lo em nosso espaço no Hugging Face Hub para que outros possam usá-lo. Para fazer isso, você precisa ter uma conta no Hugging Face.
Registro em log
Para fazer upload do conjunto de dados, primeiro precisamos fazer login.
Isso pode ser feito por meio do terminal com
huggingface-cli loginOu por meio do notebook, tendo instalado primeiro a biblioteca huggingface_hub com
pip install huggingface_hubAgora, podemos fazer login com a função notebook_login, que criará uma pequena interface gráfica na qual devemos inserir um token Hugging Face.
Para criar um token, acesse a página setings/tokens de sua conta, que terá a seguinte aparência
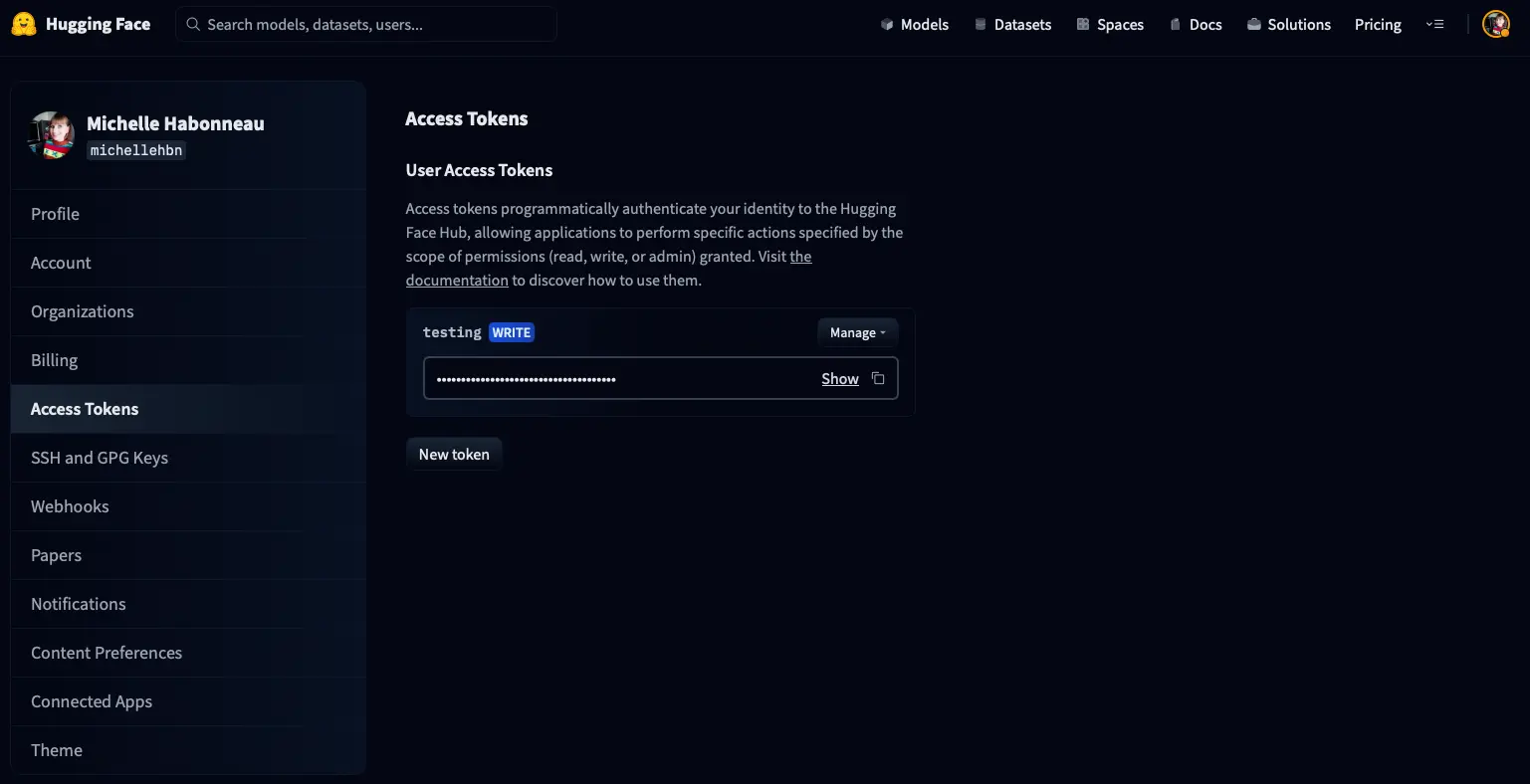
Clique em New token e será exibida uma janela para criar um novo token.
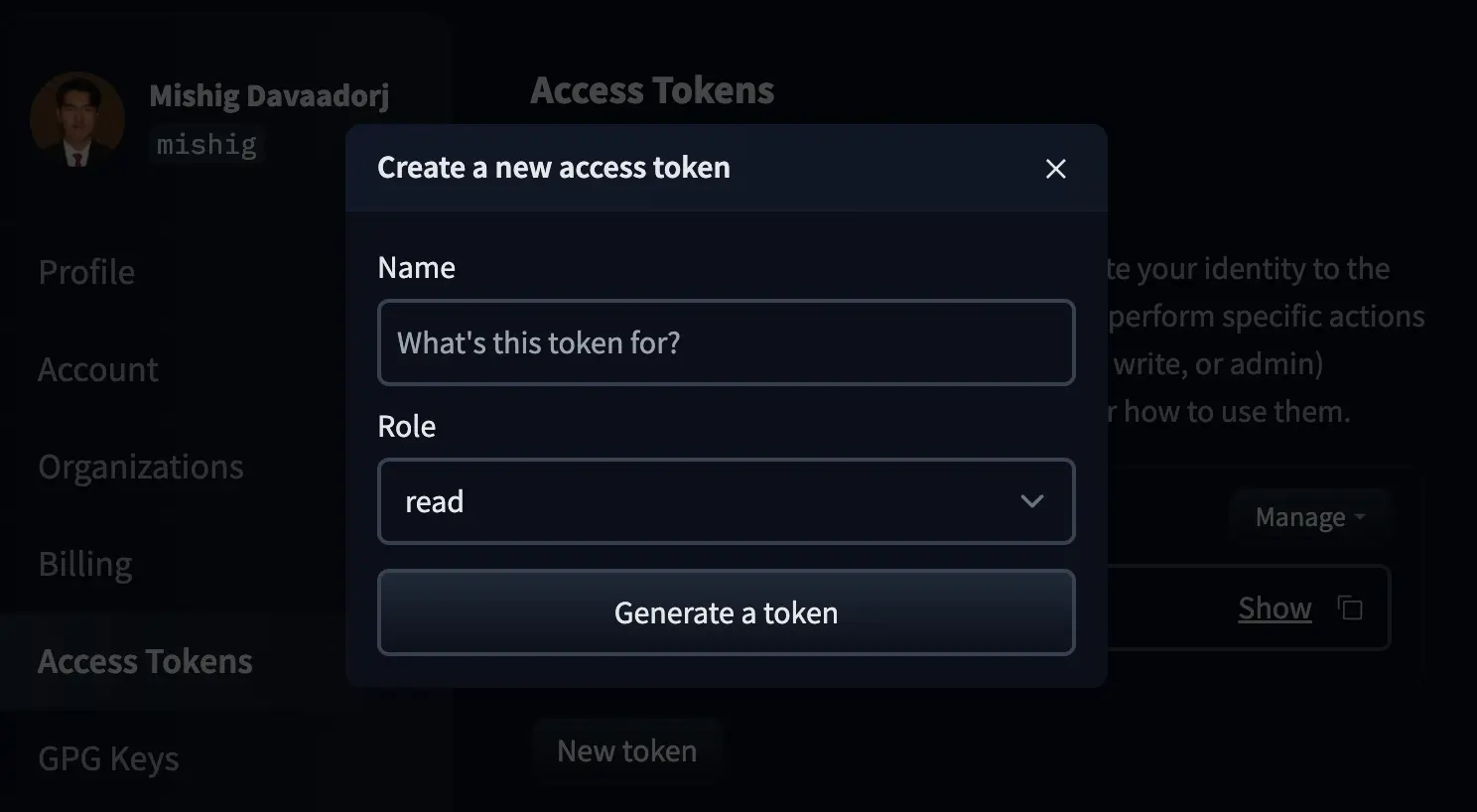
Nomeamos o token e o criamos com a função write.
Uma vez criado, nós o copiamos
InputPythonfrom huggingface_hub import notebook_loginnotebook_login()Copied
VBox(children=(HTML(value='<center> <img src=https://huggingface.co/front/assets/huggingface_logo-noborder.sv…
Upload do conjunto de dados
Uma vez conectados, podemos fazer upload do conjunto de dados simplesmente usando o método push_to_hub, fornecendo um nome para o conjunto de dados
InputPythondataset.push_to_hub("dataset_notebook_demo")Copied
Uploading the dataset shards: 0%| | 0/1 [00:00<?, ?it/s]
Creating parquet from Arrow format: 0%| | 0/1 [00:00<?, ?ba/s]
CommitInfo(commit_url='https://huggingface.co/datasets/Maximofn/dataset_notebook_demo/commit/71f1ad2cffd6f424f33d45fd992f817d8f76dc0e', commit_message='Upload dataset', commit_description='', oid='71f1ad2cffd6f424f33d45fd992f817d8f76dc0e', pr_url=None, pr_revision=None, pr_num=None)
Se formos agora ao nosso Hub, veremos que o conjunto de dados foi carregado.
Se agora acessarmos o cartão do conjunto de dados e virmos
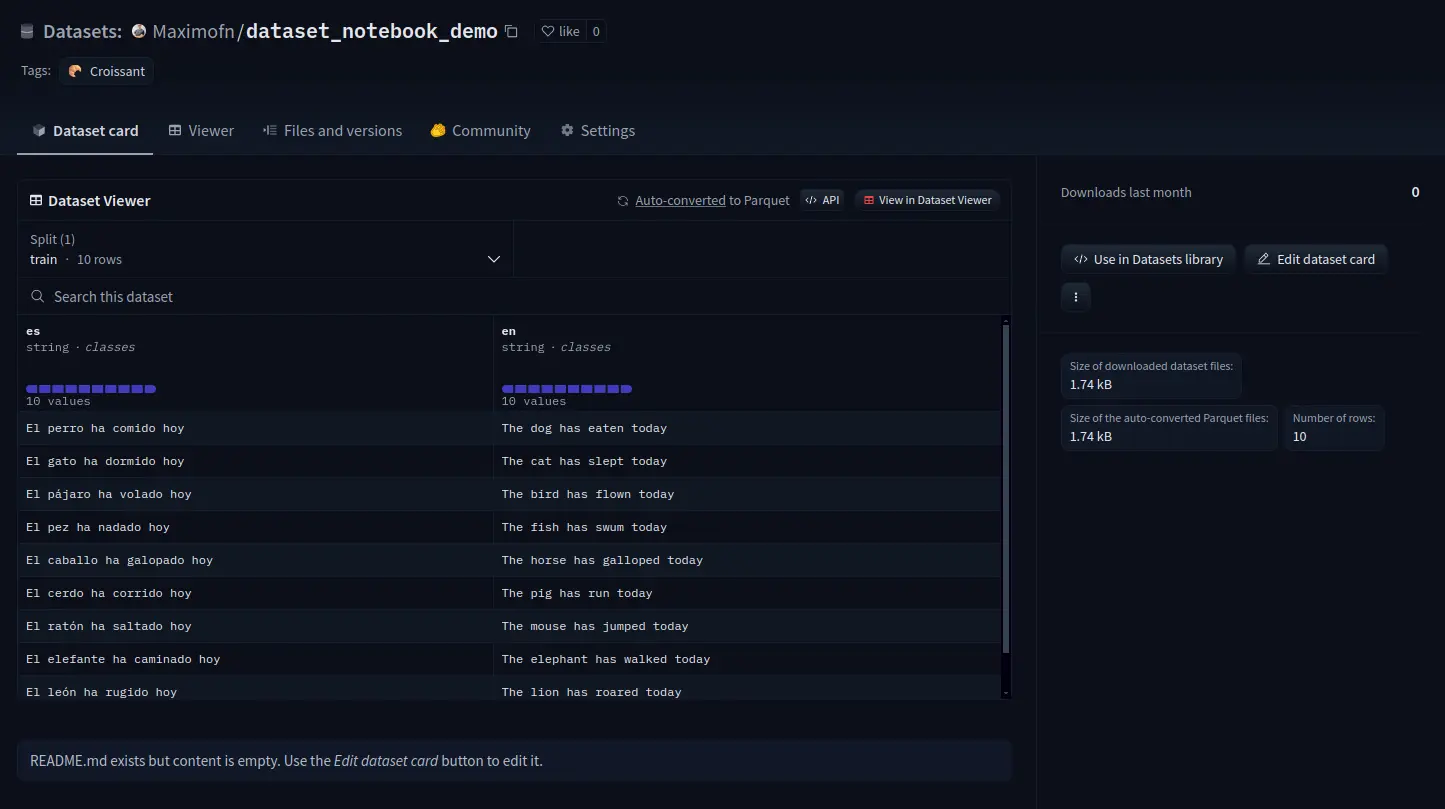
Vemos que nem tudo está preenchido, portanto, as informações devem ser completadas.
Carregamento de conjunto de dados privados
Se quisermos que somente nós ou as pessoas da nossa organização tenham acesso ao conjunto de dados, teremos que adicionar o atributo private=true ao método push_to_hub.
InputPythondataset.push_to_hub("dataset_notebook_demo_private", private=True)Copied
Uploading the dataset shards: 0%| | 0/1 [00:00<?, ?it/s]
Creating parquet from Arrow format: 0%| | 0/1 [00:00<?, ?ba/s]
CommitInfo(commit_url='https://huggingface.co/datasets/Maximofn/dataset_notebook_demo_private/commit/c90525f6aa5f1c8c44da3cde2b9599828abd8233', commit_message='Upload dataset', commit_description='', oid='c90525f6aa5f1c8c44da3cde2b9599828abd8233', pr_url=None, pr_revision=None, pr_num=None)
Se formos agora ao nosso Hub, veremos que o conjunto de dados foi carregado.
Se agora acessarmos o cartão do conjunto de dados e virmos
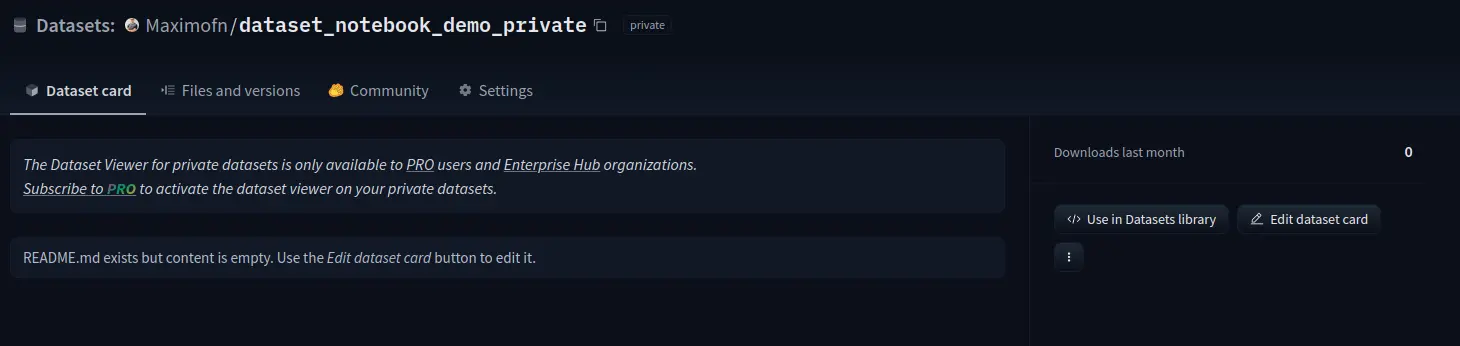
Podemos ver que nem tudo está preenchido, portanto, as informações precisariam ser completadas. Também podemos ver que nos conjuntos de dados privados os dados não estão visíveis.
Hub como repositório git
No Hugging Face, os modelos, os espaços e os conjuntos de dados são repositórios git, portanto, você pode trabalhar com eles dessa forma. Ou seja, você pode clonar, bifurcar, fazer solicitações pull, etc.
Mas outra grande vantagem disso é que você pode usar um conjunto de dados em uma determinada versão.
InputPythonfrom datasets import load_datasetds = load_dataset("yelp_review_full", revision="393e083")Copied
config.json: 0%| | 0.00/433 [00:00<?, ?B/s]
pytorch_model.bin: 0%| | 0.00/436M [00:00<?, ?B/s]
Some weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-cased and are newly initialized: ['classifier.bias', 'classifier.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.















