Las redes neuronales fueron creadas entre las décadas de los 50 y 60, imitando el funcionamiento de la sinapsis entre las neuronas del ser humano; es decir, las redes neuronales imitan a nuestras neuronas.
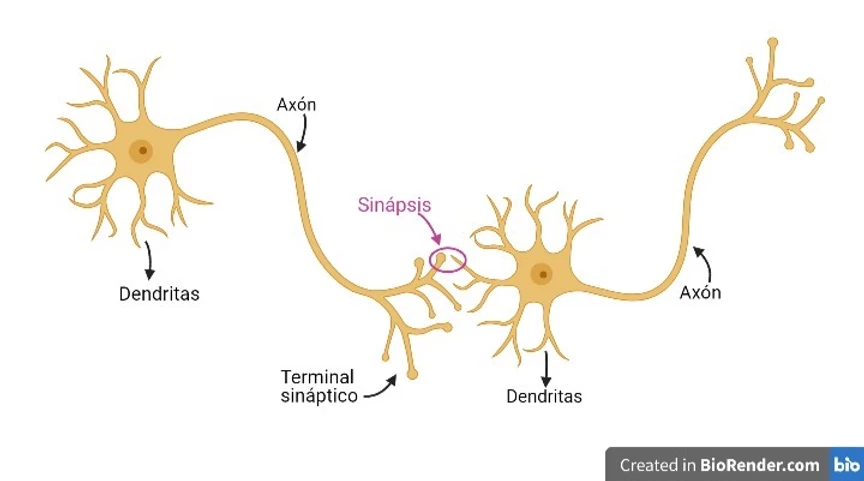
Nuestras neuronas tienen *Dendritas* por donde llegan los potenciales eléctricos y el *Axón* por donde salen nuevos potenciales eléctricos. De este modo se pueden conectar los *axones* de unas neuronas con las *dendritas* de otras formando redes neuronales. Cada neurona recibirá distintos potenciales eléctricos por sus *dendritas*; estas procesarán esos potenciales haciendo que salga un nuevo potencial eléctrico por su *axón*.
Por tanto, se pueden entender las neuronas como elementos que reciben señales de otras neuronas, las procesan y sacan otra señal hacia otra neurona.
Con esta analogía se crearon las redes neuronales artificiales, que son un conjunto de elementos que reciben señales de otras neuronas, las procesan y devuelven otras señales. Se pueden entender como unidades que realizan cálculos con las señales que les llegan y devuelven otra señal, es decir, como unidades de procesamiento
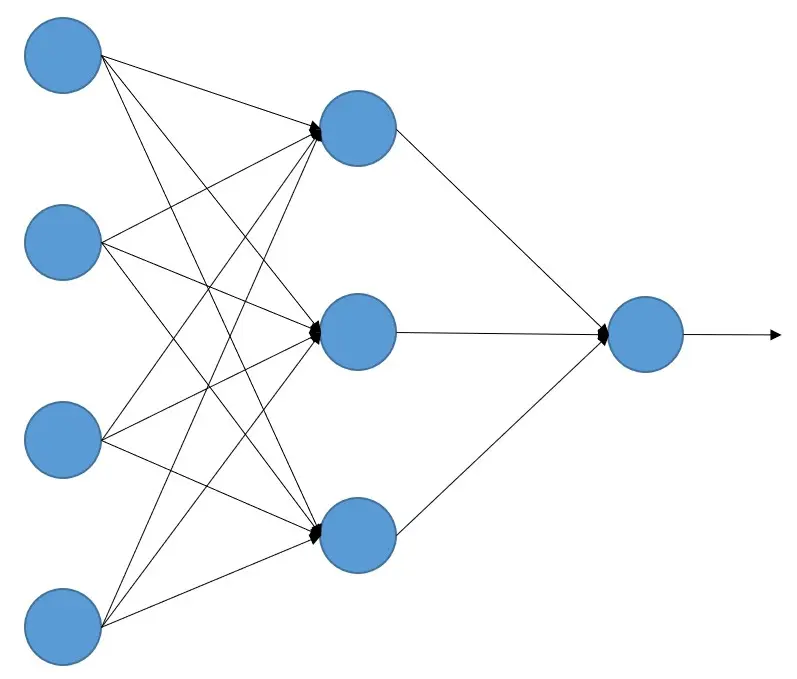
¿Cómo aprenden las redes neuronales?
Como hemos dicho, las redes neuronales artificiales son un conjunto de 'neuronas' que realizan un cálculo de todas las señales que les entran, pero ¿cómo sabemos qué cálculos tiene que hacer cada neurona para que una red neuronal artificial (a partir de ahora las llamaremos solo redes neuronales) realice la tarea que nosotros queramos?
Esto se hace mediante el aprendizaje automático. A la red neuronal se le dan un montón de ejemplos etiquetados para que aprenda. Por ejemplo, si queremos hacer una red que distinga entre perros y gatos, le daremos a la red un montón de imágenes de perros diciéndole que son perros y un montón de imágenes de gatos diciéndole que son gatos
Cuando la red tiene el conjunto de datos etiquetados (en este caso las imágenes de perros y gatos), se le pasa cada imagen a la red, esta da un resultado y si no es el esperado (en este caso perro o gato), mediante el algoritmo de backpropagation (propagación hacia atrás) que estudiaremos más adelante (esto es solo una introducción teórica) se van corrigiendo los cálculos que hace cada neurona, de manera que, a medida que se le van enseñando un montón de imágenes, la red neuronal cada vez lo va haciendo mejor hasta que acierta (en nuestro caso distingue entre un perro y un gato).
Si lo piensas, esto es lo mismo que ocurre en nuestro cerebro. Los que sois padres lo habréis vivido. Cuando tienes un hijo o hija no le explicas cómo es un perro o cómo es un gato, según vas viendo perros y gatos se lo vas diciendo "*¡Mira, un perro!*" o "*¡Ahí está el gato que hace miau!*". Y el niño o niña en su cerebro va haciendo el proceso de aprendizaje hasta que un día te dice "*¡Un gua gua!*"
El invierno de la inteligencia artificial
Pues bien, ya tenemos todo lo que necesitamos, un sistema que aprende igual que lo hace el cerebro humano y algoritmos que lo imitan. Solo necesitamos datos etiquetados y ordenadores que hagan el cálculo... ¡Pues no!
Por un lado, se vio que era necesaria una gran cantidad de datos para que las redes neuronales aprendieran. Ponte en situación, como he explicado antes, las redes neuronales se crearon entre la década de los 50 y 60, en esa época no había grandes bases de datos, ¡y mucho menos etiquetadas!
Además, las pocas bases de datos que pudiese haber eran muy pequeñas, ya que la capacidad de almacenamiento era muy pequeña. Hoy en día en nuestros teléfonos móviles podemos tener GB de memoria, pero en esa época eso era impensable, y hasta hace no tanto seguía siendo impensable.
Era común que hubiese *bases de datos analógicas*, es decir, una gran cantidad de documentos guardados en bibliotecas, universidades, etc. Pero lo que se necesitaba era que esos datos fuesen digitalizados e introducidos a las redes. Vuelve a ponerte en situación: década de entre los 50 y 60.
Además los ordenadores eran muy lentos haciendo la cantidad de cálculos que estos algoritmos necesitaban, por lo que un entrenamiento de una red muy simple llevaba mucho tiempo (días o semanas) y además no producía muy buenos resultados
Todas estas dificultades técnicas duraron muchos años, ¡en los 90 aún era común tener las cosas guardadas en disquetes, cuya capacidad podía llegar como máximo a los 2 MB!
Por estas razones, estos algoritmos se descartaron e incluso fueron mal vistos dentro de la comunidad científica. A quien le apetecía investigar en ellos lo tenía que hacer casi como pasatiempo y sin airearlo mucho.

Revolución de la inteligencia artificial
Sin embargo, en 2012 se produce un hecho que revoluciona todo. Pero vayamos atrás unos años para poner en contexto.
En 2007 salió al mercado el primer iPhone (y posteriormente un montón de smartphones de otras marcas), lo que puso en las manos de casi todo el mundo un dispositivo con la capacidad de tomar fotos con cada vez más calidad, escribir textos, música, audios, etc. Y cada vez con más capacidad de almacenamiento. Por lo que en unos pocos años se pudieron crear grandes bases de datos, digitalizadas y etiquetadas.
Por lo que ya teníamos 2 de los 3 problemas solucionados. Teníamos gran capacidad de generar datos en formato digital, etiquetados y capacidad de almacenarlos.
Por otro lado, por esas épocas, debido al creciente mundo de los videojuegos, las tarjetas gráficas o GPUs cada vez eran más potentes debido al cada vez mayor mercado. Y se dio la casualidad de que los cálculos que realizaban estas GPUs eran muy parecidos a los que necesitaban los algoritmos de las redes neuronales.
Por lo que ya teníamos dispositivos que eran capaces de realizar los cálculos necesarios en un tiempo aceptable.
Ya lo teníamos todo, solo era cuestión de tiempo que alguien lo uniese.
Competición ImageNet
En 2010 se empezó a lanzar una competición de reconocimiento de imágenes por computador llamada ILSVRC (ImageNet Large Scale Visual Recognition Challenge). Esta contiene más de 14 millones de imágenes clasificadas en 1000 categorías distintas. Gana el equipo que menor porcentaje de error tenga
Los dos primeros años, en 2010 y en 2011, se obtienen ganadores con una tasa de error similar, de entre el 25 % y el 30 %, pero en 2012 gana la competición un equipo que participó con una red neuronal llamada AlexNet y consiguió un error por encima del 15 %, es decir, una diferencia de 10 puntos. De ahí en adelante todos los años ganaron equipos con redes neuronales mejores hasta llegar un momento en que se mejoró la tasa de error del ser humano, que es del 5 %.
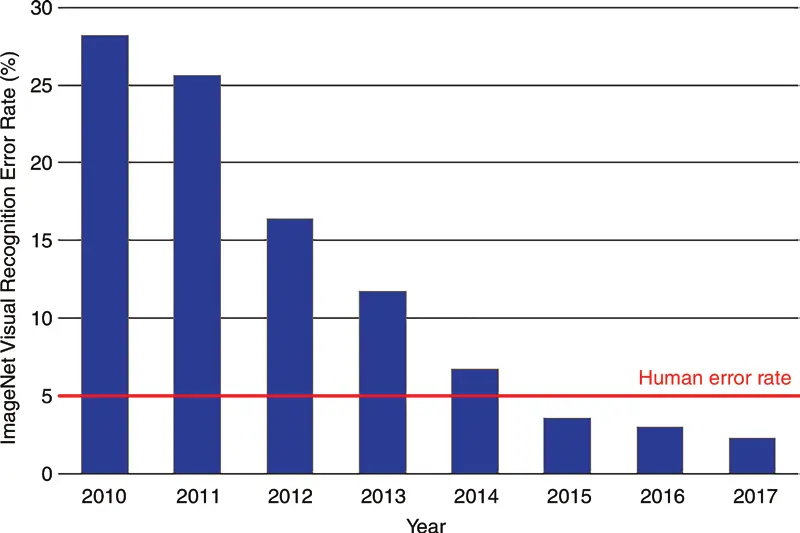
Ese hito en la competición en el año 2012 hizo ver a la comunidad científica que las redes neuronales funcionaban y el gran poder que tenían. Desde entonces no se ha parado de investigar, haciendo que de un año a otro los avances sean enormes.
Ejemplos de redes neuronales
Se puede ver cómo la generación de imágenes de caras mediante el uso de una arquitectura de red neuronal llamada GAN, ha mejorado notablemente desde el 2014.

Podemos meternos en la página web this person does not exist, donde cada vez que entremos nos mostrará la imagen de una persona que no existe y ha sido generada por una red neuronal. O nos podemos meter en la página web this X does not exist, donde nos muestra páginas que hacen lo mismo pero con otras temáticas
OpenAI ha creado Dall-e 2, que es una red a la que le pides que te dibuje algo como un astronauta descansando en un resort tropical en un estilo fotorrealista.

Nvidia ha creado GauGan2, con la cual, a partir de un garabato mal hecho, te lo convierten en un bonito paisaje.

Podemos ver cómo, gracias a las redes neuronales, Tesla ha conseguido hacer su autopiloto

Y cómo no quedarse boquiabierto con los deepfakes
Cada vez aparecen ejemplos que asombran más, y probablemente, cuando estés viendo este curso, los ejemplos que he puesto ya sean muy antiguos y haya otros mucho más novedosos y asombrosos.
















