
Disclaimer: This post has been translated to English using a machine translation model. Please, let me know if you find any mistakes.
Now that we have seen what embeddings are, we know that we can measure the similarity between two words by measuring the similarity between their embeddings. In the post on embeddings, we saw an example of using cosine similarity as a measure, but there are other similarity measures we can use, such as L2 squared, dot product similarity, cosine similarity, etc.
In this post, we are going to cover the three that we have mentioned.
L2 Square Similarity
This similarity is derived from the Euclidean distance, which is the straight-line distance between two points in a multidimensional space, calculated using the Pythagorean theorem.
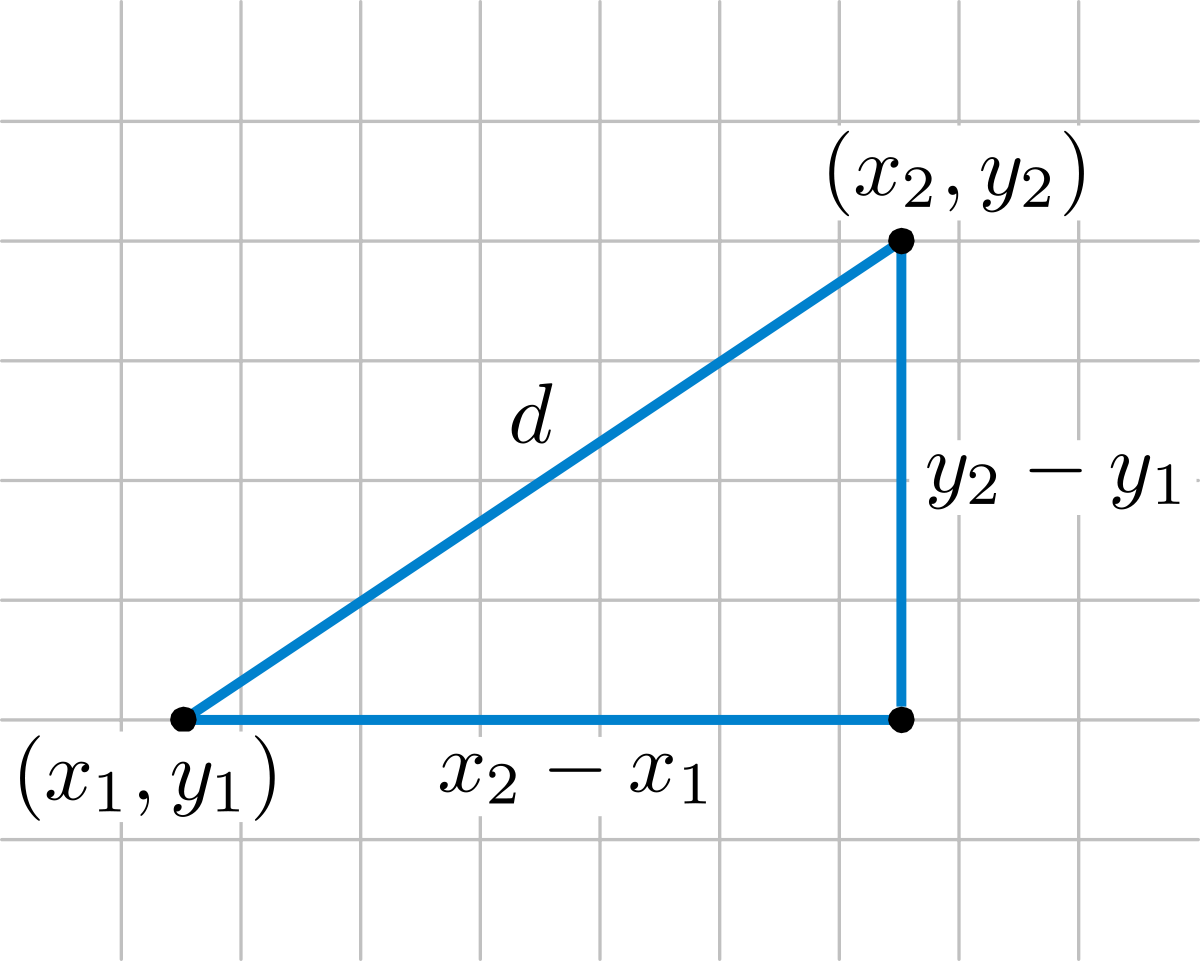
The Euclidean distance between two points p and q is calculated as:
d(p,q) = √((p1 - q1)2 + (p2 - q2)2 + ··· + (pn - qn)2) = √(∑i=1n (pi - qi)2)
The L2 similarity is the square of the Euclidean distance, that is:
similarity(p,q) = d(p,q)2 = ∑i=1n (pi - qi)2
Cosine Similarity
If we remember what we learned about sines and cosines in school, we will recall that when two vectors have an angle of 0° between them, their cosine is 1, when the angle between them is 90°, their cosine is 0, and when the angle is 180°, their cosine is -1.
Therefore, we can use the cosine of the angle between two vectors to measure their similarity. It can be shown that the cosine of the angle between two vectors is equal to the dot product of the two vectors divided by the product of their magnitudes. Proving this is not the goal of this post, but if you want, you can see the proof here.
similarity(U,V) = U · V||U|| ||V||
Dot Product Similarity
The dot product similarity is the dot product of two vectors
similarity(U,V) = U · V
As we have written the cosine similarity formula, when the length of the vectors is 1, that is, they are normalized, the cosine similarity is equal to the dot product similarity.
So, what is the use of the dot product similarity? It is used to measure the similarity between two vectors that are not normalized, that is, they do not have a length of 1.
For example, YouTube, to create the embeddings of its videos, makes the embeddings of the videos it classifies as higher quality longer than those of the videos it classifies as lower quality.
In this way, when a user performs a search, the dot product similarity will give higher similarity to higher quality videos, so it will provide the user with the highest quality videos first.
Which similarity system to use
To choose the similarity system we are going to use, we must take into account the space in which we are working.
- If we are working in a high-dimensional space, with normalized embeddings, cosine similarity works best. For example, OpenAI generates normalized embeddings, so cosine similarity works best.
- If we are working on a classification system where the distance between two classes is important, the L2 squared similarity works best.
- If we are working on a recommendation system where the length of the vectors is important, the dot product similarity works best.

















