
Aviso: Este post foi traduzido para o português usando um modelo de tradução automática. Por favor, me avise se encontrar algum erro.
Neste post, vamos ver como fazer fine tuning em pequenos modelos de linguagem, vamos ver como fazer fine tuning para classificação de texto e para geração de texto. Primeiro, vamos ver como fazer isso com as bibliotecas do Hugging Face, já que o Hugging Face se tornou um ator muito importante no ecossistema de IA neste momento.
Mas embora as bibliotecas do Hugging Face sejam muito importantes e úteis, é muito importante saber como o treinamento realmente acontece e o que está acontecendo por baixo dos panos, então vamos repetir o treinamento para classificação e geração de texto, mas com Pytorch.
Ajuste fino para classificação de texto com Hugging Face
Login
Para poder subir o resultado do treinamento ao hub devemos nos autenticar primeiro, para isso precisamos de um token
Para criar um token, é necessário ir à página de settings/tokens da nossa conta, onde aparecerá algo assim
Damos a New token e será exibida uma janela para criar um novo token
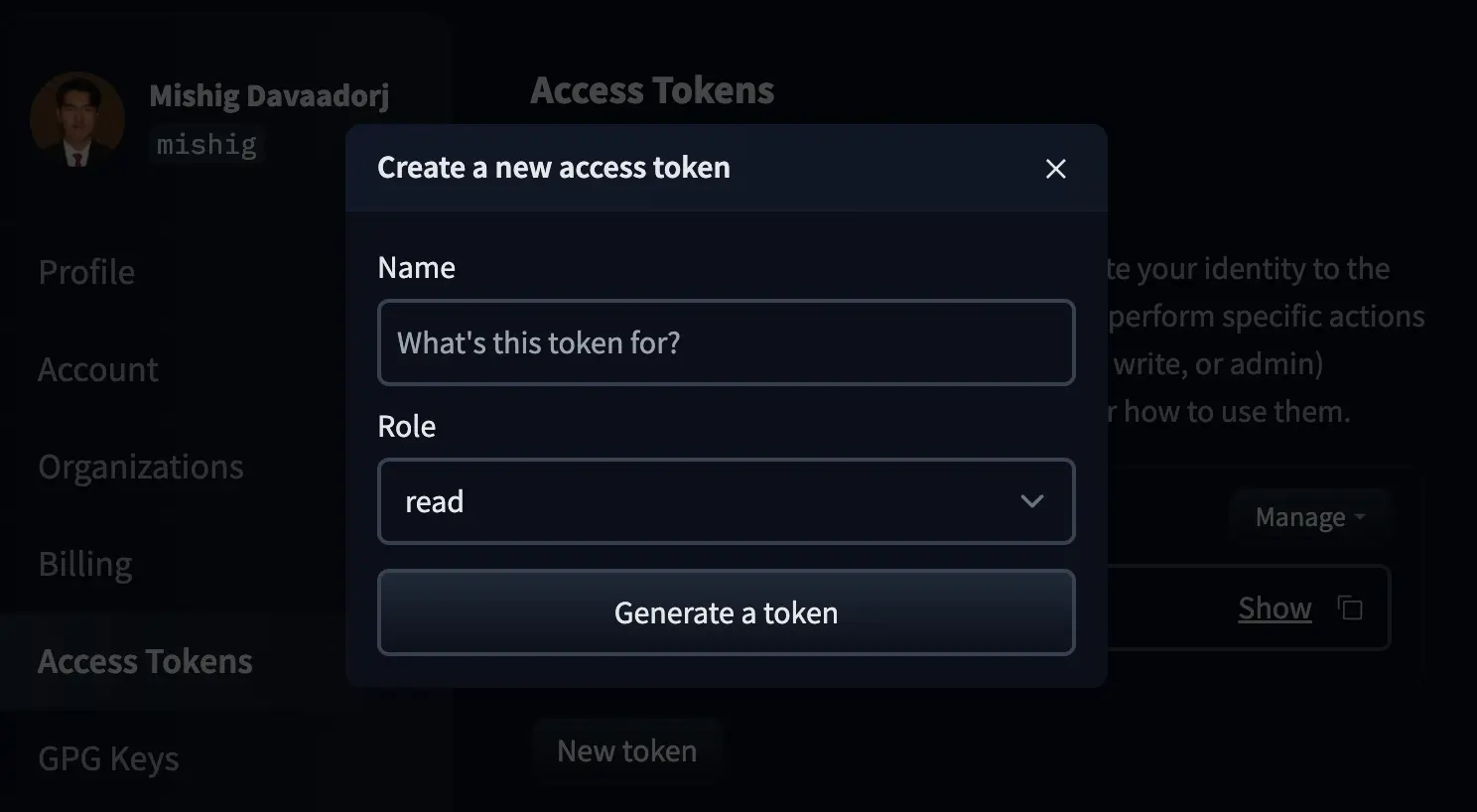
Damos um nome ao token e o criamos com o papel write, ou com o papel Fine-grained, que nos permite selecionar exatamente quais permissões o token terá.
Uma vez criado, copiamos e colamos a seguir.
InputPythonfrom huggingface_hub import notebook_loginnotebook_login()Copied
Conjunto de Dados
Agora vamos baixar um dataset, neste caso vamos baixar um de avaliações do Amazon
InputPythonfrom datasets import load_datasetdataset = load_dataset("mteb/amazon_reviews_multi", "en")Copied
Vamos vê-lo um pouco
InputPythondatasetCopied
DatasetDict({train: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 200000})validation: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000})test: Dataset({features: ['id', 'text', 'label', 'label_text'],num_rows: 5000})})
Vemos que tem um conjunto de treinamento com 200.000 amostras, um de validação com 5.000 amostras e um de teste com 5.000 amostras.
Vamos a ver um exemplo do conjunto de treinamento
InputPythonfrom random import randintidx = randint(0, len(dataset['train']) - 1)dataset['train'][idx]Copied
{'id': 'en_0907914','text': 'Mixed with fir it’s passable Not the scent I had hoped for . Love the scent of cedar, but this one missed','label': 3,'label_text': '3'}
Vemos que tem a avaliação no campo text e a pontuação que o usuário deu no campo label
Como vamos a fazer um modelo de classificação de textos, precisamos saber quantas classes vamos ter.
InputPythonnum_classes = len(dataset['train'].unique('label'))num_classesCopied
5
Vamos a ter 5 classes, agora vamos a ver o valor mínimo dessas classes para saber se a pontuação começa em 0 ou em 1. Para isso, usamos o método unique
InputPythondataset.unique('label')Copied
{'train': [0, 1, 2, 3, 4],'validation': [0, 1, 2, 3, 4],'test': [0, 1, 2, 3, 4]}
O valor mínimo será 0
Para treinar, as etiquetas precisam estar em um campo chamado labels, enquanto no nosso conjunto de dados está em um campo chamado label, então criamos o novo campo labels com o mesmo valor que label
Criamos uma função que faça o que quisermos
InputPythondef set_labels(example):example['labels'] = example['label']return exampleCopied
Aplicamos a função ao conjunto de dados
InputPythondataset = dataset.map(set_labels)Copied
Vamos ver como fica o dataset
InputPythondataset['train'][idx]Copied
{'id': 'en_0907914','text': 'Mixed with fir it’s passable Not the scent I had hoped for . Love the scent of cedar, but this one missed','label': 3,'label_text': '3','labels': 3}
Tokenizador
Como temos as avaliações em texto no conjunto de dados, precisamos tokenizá-las para poder inserir os tokens no modelo.
InputPythonfrom transformers import AutoTokenizercheckpoint = "openai-community/gpt2"tokenizer = AutoTokenizer.from_pretrained(checkpoint)Copied
Agora criamos uma função para tokenizar o texto. Vamos fazer isso de maneira que todas as frases tenham o mesmo comprimento, de modo que o tokenizador truncará quando necessário e adicionará tokens de padding quando necessário. Além disso, indicamos que retorne tensores do pytorch.
Fazemos com que o comprimento de cada sentença seja de 768 tokens porque estamos usando o modelo pequeno do GPT2, que como vimos no post de GPT2 tem uma dimensão de embedding de 768 tokens
InputPythondef tokenize_function(examples):return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=768, return_tensors="pt")Copied
Vamos a provar a tokenizar um texto
InputPythontokens = tokenize_function(dataset['train'][idx])Copied
---------------------------------------------------------------------------ValueError Traceback (most recent call last)Cell In[11], line 1----> 1 tokens = tokenize_function(dataset['train'][idx])Cell In[10], line 2, in tokenize_function(examples)1 def tokenize_function(examples):----> 2 return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=768, return_tensors="pt")File ~/miniconda3/envs/nlp_/lib/python3.11/site-packages/transformers/tokenization_utils_base.py:2883, in PreTrainedTokenizerBase.__call__(self, text, text_pair, text_target, text_pair_target, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)2881 if not self._in_target_context_manager:2882 self._switch_to_input_mode()-> 2883 encodings = self._call_one(text=text, text_pair=text_pair, **all_kwargs)2884 if text_target is not None:2885 self._switch_to_target_mode()File ~/miniconda3/envs/nlp_/lib/python3.11/site-packages/transformers/tokenization_utils_base.py:2989, in PreTrainedTokenizerBase._call_one(self, text, text_pair, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)2969 return self.batch_encode_plus(2970 batch_text_or_text_pairs=batch_text_or_text_pairs,2971 add_special_tokens=add_special_tokens,(...)2986 **kwargs,2987 )2988 else:-> 2989 return self.encode_plus(2990 text=text,2991 text_pair=text_pair,2992 add_special_tokens=add_special_tokens,2993 padding=padding,2994 truncation=truncation,2995 max_length=max_length,2996 stride=stride,2997 is_split_into_words=is_split_into_words,2998 pad_to_multiple_of=pad_to_multiple_of,2999 return_tensors=return_tensors,3000 return_token_type_ids=return_token_type_ids,3001 return_attention_mask=return_attention_mask,3002 return_overflowing_tokens=return_overflowing_tokens,3003 return_special_tokens_mask=return_special_tokens_mask,3004 return_offsets_mapping=return_offsets_mapping,3005 return_length=return_length,3006 verbose=verbose,3007 **kwargs,3008 )File ~/miniconda3/envs/nlp_/lib/python3.11/site-packages/transformers/tokenization_utils_base.py:3053, in PreTrainedTokenizerBase.encode_plus(self, text, text_pair, add_special_tokens, padding, truncation, max_length, stride, is_split_into_words, pad_to_multiple_of, return_tensors, return_token_type_ids, return_attention_mask, return_overflowing_tokens, return_special_tokens_mask, return_offsets_mapping, return_length, verbose, **kwargs)3032 """3033 Tokenize and prepare for the model a sequence or a pair of sequences.3034(...)3049 method).3050 """3052 # Backward compatibility for 'truncation_strategy', 'pad_to_max_length'-> 3053 padding_strategy, truncation_strategy, max_length, kwargs = self._get_padding_truncation_strategies(3054 padding=padding,3055 truncation=truncation,3056 max_length=max_length,3057 pad_to_multiple_of=pad_to_multiple_of,3058 verbose=verbose,3059 **kwargs,3060 )3062 return self._encode_plus(3063 text=text,3064 text_pair=text_pair,(...)3080 **kwargs,3081 )File ~/miniconda3/envs/nlp_/lib/python3.11/site-packages/transformers/tokenization_utils_base.py:2788, in PreTrainedTokenizerBase._get_padding_truncation_strategies(self, padding, truncation, max_length, pad_to_multiple_of, verbose, **kwargs)2786 # Test if we have a padding token2787 if padding_strategy != PaddingStrategy.DO_NOT_PAD and (self.pad_token is None or self.pad_token_id < 0):-> 2788 raise ValueError(2789 "Asking to pad but the tokenizer does not have a padding token. "2790 "Please select a token to use as `pad_token` `(tokenizer.pad_token = tokenizer.eos_token e.g.)` "2791 "or add a new pad token via `tokenizer.add_special_tokens({'pad_token': '[PAD]'})`."2792 )2794 # Check that we will truncate to a multiple of pad_to_multiple_of if both are provided2795 if (2796 truncation_strategy != TruncationStrategy.DO_NOT_TRUNCATE2797 and padding_strategy != PaddingStrategy.DO_NOT_PAD(...)2800 and (max_length % pad_to_multiple_of != 0)2801 ):ValueError: Asking to pad but the tokenizer does not have a padding token. Please select a token to use as `pad_token` `(tokenizer.pad_token = tokenizer.eos_token e.g.)` or add a new pad token via `tokenizer.add_special_tokens({'pad_token': '[PAD]'})`.
Dá-nos um erro porque o tokenizador do GPT2 não tem um token para preenchimento e pede que atribuamos um, além de sugerir fazer tokenizer.pad_token = tokenizer.eos_token, então fazemos isso.
InputPythontokenizer.pad_token = tokenizer.eos_tokenCopied
Voltamos a testar a função de tokenização
InputPythontokens = tokenize_function(dataset['train'][idx])tokens['input_ids'].shape, tokens['attention_mask'].shapeCopied
(torch.Size([1, 768]), torch.Size([1, 768]))
Agora que verificamos que a função tokeniza corretamente, aplicamos essa função ao conjunto de dados, mas também a aplicamos em lotes para que seja executada mais rapidamente.
Além disso, aproveitamos e eliminamos as colunas que não vamos precisar.
InputPythondataset = dataset.map(tokenize_function, batched=True, remove_columns=['text', 'label', 'id', 'label_text'])Copied
Vamos ver agora como fica o dataset
InputPythondatasetCopied
DatasetDict({train: Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 200000})validation: Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 5000})test: Dataset({features: ['id', 'text', 'label', 'label_text', 'labels'],num_rows: 5000})})
Vemos que temos os campos 'labels', 'input_ids' e 'attention_mask', que é o que nos interessa para treinar.
Modelo
Instanciamos um modelo para classificação de sequências e indicamos o número de classes que temos
InputPythonfrom transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_classes)Copied
Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Diz que os pesos da camada score foram inicializados de maneira aleatória e que temos que reentreiná-los, vamos ver por que isso acontece.
O modelo GPT2 seria este
InputPythonfrom transformers import AutoModelForCausalLMcasual_model = AutoModelForCausalLM.from_pretrained(checkpoint)Copied
Enquanto o modelo do GPT2 para gerar texto é este
Vamos a ver sua arquitetura
InputPythoncasual_modelCopied
GPT2LMHeadModel((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(lm_head): Linear(in_features=768, out_features=50257, bias=False))
E agora a arquitetura do modelo que vamos usar para classificar as reviews
InputPythonmodelCopied
GPT2ForSequenceClassification((transformer): GPT2Model((wte): Embedding(50257, 768)(wpe): Embedding(1024, 768)(drop): Dropout(p=0.1, inplace=False)(h): ModuleList((0-11): 12 x GPT2Block((ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(attn): GPT2Attention((c_attn): Conv1D()(c_proj): Conv1D()(attn_dropout): Dropout(p=0.1, inplace=False)(resid_dropout): Dropout(p=0.1, inplace=False))(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): GPT2MLP((c_fc): Conv1D()(c_proj): Conv1D()(act): NewGELUActivation()(dropout): Dropout(p=0.1, inplace=False))))(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True))(score): Linear(in_features=768, out_features=5, bias=False))
Aqui há duas coisas para mencionar
- A primeira é que em ambos, a primeira camada tem dimensões de 50257x768, o que corresponde a 50257 possíveis tokens do vocabulário do GPT2 e a 768 dimensões do embedding, por isso fizemos bem em tokenizar as avaliações com um tamanho de 768 tokens
- A segunda é que o modelo
casual(o de geração de texto) tem no final uma camadaLinearque gera 50257 valores, ou seja, é responsável por prever o próximo token e dar um valor a um possível token. Enquanto isso, o modelo de classificação tem uma camadaLinearque gera apenas 5 valores, um para cada classe, o que nos fornecerá a probabilidade de a review pertencer a cada classe.
Por isso recebíamos a mensagem de que os pesos da camada score haviam sido inicializados de forma aleatória, porque a biblioteca transformers removeu a camada Linear de 768x50257 e adicionou uma camada Linear de 768x5, inicializou-a com valores aleatórios e nós temos que treiná-la para o nosso problema específico.
Apagamos o modelo casual, pois não vamos usá-lo.
InputPythondel casual_modelCopied
Treinador
Vamos agora a configurar os argumentos do treinamento
InputPythonfrom transformers import TrainingArgumentsmetric_name = "accuracy"model_name = "GPT2-small-finetuned-amazon-reviews-en-classification"LR = 2e-5BS_TRAIN = 28BS_EVAL = 40EPOCHS = 3WEIGHT_DECAY = 0.01training_args = TrainingArguments(model_name,eval_strategy="epoch",save_strategy="epoch",learning_rate=LR,per_device_train_batch_size=BS_TRAIN,per_device_eval_batch_size=BS_EVAL,num_train_epochs=EPOCHS,weight_decay=WEIGHT_DECAY,lr_scheduler_type="cosine",warmup_ratio = 0.1,fp16=True,load_best_model_at_end=True,metric_for_best_model=metric_name,push_to_hub=True,)Copied
Definimos uma métrica para o dataloader de validação
InputPythonimport numpy as npfrom evaluate import loadmetric = load("accuracy")def compute_metrics(eval_pred):print(eval_pred)predictions, labels = eval_predpredictions = np.argmax(predictions, axis=1)return metric.compute(predictions=predictions, references=labels)Copied
Definimos agora o treinador
InputPythonfrom transformers import Trainertrainer = Trainer(model,training_args,train_dataset=dataset['train'],eval_dataset=dataset['validation'],tokenizer=tokenizer,compute_metrics=compute_metrics,)Copied
Treinamos
InputPythontrainer.train()Copied
0%| | 0/600000 [00:00<?, ?it/s]
---------------------------------------------------------------------------ValueError Traceback (most recent call last)Cell In[21], line 1----> 1 trainer.train()File ~/miniconda3/envs/nlp_/lib/python3.11/site-packages/transformers/trainer.py:1876, in Trainer.train(self, resume_from_checkpoint, trial, ignore_keys_for_eval, **kwargs)1873 try:1874 # Disable progress bars when uploading models during checkpoints to avoid polluting stdout1875 hf_hub_utils.disable_progress_bars()-> 1876 return inner_training_loop(1877 args=args,1878 resume_from_checkpoint=resume_from_checkpoint,1879 trial=trial,1880 ignore_keys_for_eval=ignore_keys_for_eval,1881 )1882 finally:1883 hf_hub_utils.enable_progress_bars()File ~/miniconda3/envs/nlp_/lib/python3.11/site-packages/transformers/trainer.py:2178, in Trainer._inner_training_loop(self, batch_size, args, resume_from_checkpoint, trial, ignore_keys_for_eval)2175 rng_to_sync = True2177 step = -1-> 2178 for step, inputs in enumerate(epoch_iterator):2179 total_batched_samples += 12181 if self.args.include_num_input_tokens_seen:File ~/miniconda3/envs/nlp_/lib/python3.11/site-packages/accelerate/data_loader.py:454, in DataLoaderShard.__iter__(self)452 # We iterate one batch ahead to check when we are at the end453 try:--> 454 current_batch = next(dataloader_iter)455 except StopIteration:456 yieldFile ~/miniconda3/envs/nlp_/lib/python3.11/site-packages/torch/utils/data/dataloader.py:631, in _BaseDataLoaderIter.__next__(self)628 if self._sampler_iter is None:629 # TODO(https://github.com/pytorch/pytorch/issues/76750)630 self._reset() # type: ignore[call-arg]--> 631 data = self._next_data()632 self._num_yielded += 1633 if self._dataset_kind == _DatasetKind.Iterable and \634 self._IterableDataset_len_called is not None and \635 self._num_yielded > self._IterableDataset_len_called:File ~/miniconda3/envs/nlp_/lib/python3.11/site-packages/torch/utils/data/dataloader.py:675, in _SingleProcessDataLoaderIter._next_data(self)673 def _next_data(self):674 index = self._next_index() # may raise StopIteration--> 675 data = self._dataset_fetcher.fetch(index) # may raise StopIteration676 if self._pin_memory:677 data = _utils.pin_memory.pin_memory(data, self._pin_memory_device)File ~/miniconda3/envs/nlp_/lib/python3.11/site-packages/torch/utils/data/_utils/fetch.py:54, in _MapDatasetFetcher.fetch(self, possibly_batched_index)52 else:53 data = self.dataset[possibly_batched_index]---> 54 return self.collate_fn(data)File ~/miniconda3/envs/nlp_/lib/python3.11/site-packages/transformers/data/data_collator.py:271, in DataCollatorWithPadding.__call__(self, features)270 def __call__(self, features: List[Dict[str, Any]]) -> Dict[str, Any]:--> 271 batch = pad_without_fast_tokenizer_warning(272 self.tokenizer,273 features,274 padding=self.padding,275 max_length=self.max_length,276 pad_to_multiple_of=self.pad_to_multiple_of,277 return_tensors=self.return_tensors,278 )279 if "label" in batch:280 batch["labels"] = batch["label"]File ~/miniconda3/envs/nlp_/lib/python3.11/site-packages/transformers/data/data_collator.py:66, in pad_without_fast_tokenizer_warning(tokenizer, *pad_args, **pad_kwargs)63 tokenizer.deprecation_warnings["Asking-to-pad-a-fast-tokenizer"] = True65 try:---> 66 padded = tokenizer.pad(*pad_args, **pad_kwargs)67 finally:68 # Restore the state of the warning.69 tokenizer.deprecation_warnings["Asking-to-pad-a-fast-tokenizer"] = warning_stateFile ~/miniconda3/envs/nlp_/lib/python3.11/site-packages/transformers/tokenization_utils_base.py:3299, in PreTrainedTokenizerBase.pad(self, encoded_inputs, padding, max_length, pad_to_multiple_of, return_attention_mask, return_tensors, verbose)3297 # The model's main input name, usually `input_ids`, has be passed for padding3298 if self.model_input_names[0] not in encoded_inputs:-> 3299 raise ValueError(3300 "You should supply an encoding or a list of encodings to this method "3301 f"that includes {self.model_input_names[0]}, but you provided {list(encoded_inputs.keys())}"3302 )3304 required_input = encoded_inputs[self.model_input_names[0]]3306 if required_input is None or (isinstance(required_input, Sized) and len(required_input) == 0):ValueError: You should supply an encoding or a list of encodings to this method that includes input_ids, but you provided ['label', 'labels']
Nós recebemos novamente um erro porque o modelo não tem um token de padding atribuído, então, assim como com o tokenizador, nós o atribuímos.
InputPythonmodel.config.pad_token_id = model.config.eos_token_idCopied
Recriamos os argumentos do treinador com o novo modelo, que agora tem um token de padding, o treinador e voltamos a treinar.
InputPythontraining_args = TrainingArguments(model_name,eval_strategy="epoch",save_strategy="epoch",learning_rate=LR,per_device_train_batch_size=BS_TRAIN,per_device_eval_batch_size=BS_EVAL,num_train_epochs=EPOCHS,weight_decay=WEIGHT_DECAY,lr_scheduler_type="cosine",warmup_ratio = 0.1,fp16=True,load_best_model_at_end=True,metric_for_best_model=metric_name,push_to_hub=True,logging_dir="./runs",)trainer = Trainer(model,training_args,train_dataset=dataset['train'],eval_dataset=dataset['validation'],tokenizer=tokenizer,compute_metrics=compute_metrics,)Copied
Agora que vimos que tudo está bem, podemos treinar
InputPythontrainer.train()Copied
<IPython.core.display.HTML object>
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x782767ea1450><transformers.trainer_utils.EvalPrediction object at 0x782767eeefe0><transformers.trainer_utils.EvalPrediction object at 0x782767eecfd0>
TrainOutput(global_step=21429, training_loss=0.7846888848762739, metrics={'train_runtime': 26367.7801, 'train_samples_per_second': 22.755, 'train_steps_per_second': 0.813, 'total_flos': 2.35173445632e+17, 'train_loss': 0.7846888848762739, 'epoch': 3.0})
Avaliação
Uma vez treinado, avaliamos sobre o dataset de teste
InputPythontrainer.evaluate(eval_dataset=dataset['test'])Copied
<IPython.core.display.HTML object>
<transformers.trainer_utils.EvalPrediction object at 0x7826ddfded40>
{'eval_loss': 0.7973636984825134,'eval_accuracy': 0.6626,'eval_runtime': 76.3016,'eval_samples_per_second': 65.529,'eval_steps_per_second': 1.638,'epoch': 3.0}
Publicar o modelo
Já temos nosso modelo treinado, agora podemos compartilhá-lo com o mundo, então primeiro criamos uma **ficha do modelo**
InputPythontrainer.create_model_card()Copied
E já podemos publicá-lo. Como a primeira coisa que fizemos foi fazer login no hub do huggingface, podemos enviá-lo para o nosso hub sem nenhum problema.
InputPythontrainer.push_to_hub()Copied
Uso do modelo
Limpamos tudo o que for possível
InputPythonimport torchimport gcdef clear_hardwares():torch.clear_autocast_cache()torch.cuda.ipc_collect()torch.cuda.empty_cache()gc.collect()clear_hardwares()clear_hardwares()Copied
Como subimos o modelo ao nosso hub, podemos baixá-lo e usá-lo
InputPythonfrom transformers import pipelineuser = "maximofn"checkpoints = f"{user}/{model_name}"task = "text-classification"classifier = pipeline(task, model=checkpoints, tokenizer=checkpoints)Copied
Agora, se quisermos que nos retorne a probabilidade de todas as classes, simplesmente usamos o classificador que acabamos de instanciar, com o parâmetro top_k=None
InputPythonlabels = classifier("I love this product", top_k=None)labelsCopied
[{'label': 'LABEL_4', 'score': 0.8253807425498962},{'label': 'LABEL_3', 'score': 0.15411493182182312},{'label': 'LABEL_2', 'score': 0.013907806016504765},{'label': 'LABEL_0', 'score': 0.003939222544431686},{'label': 'LABEL_1', 'score': 0.0026572425849735737}]
Se quisermos apenas a classe com a maior probabilidade, fazemos o mesmo mas com o parâmetro top_k=1
InputPythonlabel = classifier("I love this product", top_k=1)labelCopied
[{'label': 'LABEL_4', 'score': 0.8253807425498962}]
E se quisermos n classes, fazemos o mesmo mas com o parâmetro top_k=n
InputPythontwo_labels = classifier("I love this product", top_k=2)two_labelsCopied
[{'label': 'LABEL_4', 'score': 0.8253807425498962},{'label': 'LABEL_3', 'score': 0.15411493182182312}]
Também podemos testar o modelo com Automodel e AutoTokenizer
InputPythonfrom transformers import AutoTokenizer, AutoModelForSequenceClassificationimport torchmodel_name = "GPT2-small-finetuned-amazon-reviews-en-classification"user = "maximofn"checkpoint = f"{user}/{model_name}"num_classes = 5tokenizer = AutoTokenizer.from_pretrained(checkpoint)model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_classes).half().eval().to("cuda")Copied
InputPythontokens = tokenizer.encode("I love this product", return_tensors="pt").to(model.device)with torch.no_grad():output = model(tokens)logits = output.logitslables = torch.softmax(logits, dim=1).cpu().numpy().tolist()lables[0]Copied
[0.003963470458984375,0.0026721954345703125,0.01397705078125,0.154541015625,0.82470703125]
Se você quiser testar mais o modelo, você pode vê-lo em Maximofn/GPT2-small-finetuned-amazon-reviews-en-classification
Ajuste fino para geração de texto com Hugging Face
Para garantizar que não tenho problemas de memória VRAM, reinicio o notebook
Login
Para poder fazer o upload do resultado do treinamento para o hub, devemos nos autenticar primeiro, para isso precisamos de um token
Para criar um token é necessário ir à página de settings/tokens da nossa conta, aparecerá algo assim
Damos a New token e uma janela aparecerá para criar um novo token
Damos um nome ao token e o criamos com o papel write, ou com o papel Fine-grained, que nos permite selecionar exatamente quais permissões terá o token.
Uma vez criado, copiamos e colamos a seguir.
InputPythonfrom huggingface_hub import notebook_loginnotebook_login()Copied
Conjunto de Dados
Vamos a usar um dataset de chistes em inglês
InputPythonfrom datasets import load_datasetjokes = load_dataset("Maximofn/short-jokes-dataset")jokesCopied
DatasetDict({train: Dataset({features: ['ID', 'Joke'],num_rows: 231657})})
Vamos vê-lo um pouco
InputPythonjokesCopied
DatasetDict({train: Dataset({features: ['ID', 'Joke'],num_rows: 231657})})
Vemos que é um conjunto de treinamento único com mais de 200 mil piadas. Então, mais tarde teremos que dividi-lo em treinamento e avaliação.
Vamos a ver um exemplo
InputPythonfrom random import randintidx = randint(0, len(jokes['train']) - 1)jokes['train'][idx]Copied
{'ID': 198387,'Joke': 'My hot dislexic co-worker said she had an important massage to give me in her office... When I got there, she told me it can wait until I put on some clothes.'}
Vemos que tem um ID de piada que não nos interessa em absoluto e a própria piada
Caso você tenha pouca memória na GPU, vou fazer um subconjunto do conjunto de dados, escolha o percentual de piadas que deseja usar
InputPythonpercent_of_train_dataset = 1 # If you want 50% of the dataset, set this to 0.5subset_dataset = jokes["train"].select(range(int(len(jokes["train"]) * percent_of_train_dataset)))subset_datasetCopied
Dataset({features: ['ID', 'Joke'],num_rows: 231657})
Agora dividimos o subconjunto em um conjunto de treinamento e outro de validação.
InputPythonpercent_of_train_dataset = 0.90split_dataset = subset_dataset.train_test_split(train_size=int(subset_dataset.num_rows * percent_of_train_dataset), seed=19, shuffle=False)train_dataset = split_dataset["train"]validation_test_dataset = split_dataset["test"]split_dataset = validation_test_dataset.train_test_split(train_size=int(validation_test_dataset.num_rows * 0.5), seed=19, shuffle=False)validation_dataset = split_dataset["train"]test_dataset = split_dataset["test"]print(f"Size of the train set: {len(train_dataset)}. Size of the validation set: {len(validation_dataset)}. Size of the test set: {len(test_dataset)}")Copied
Size of the train set: 208491. Size of the validation set: 11583. Size of the test set: 11583
Tokenizador
Instanciamos o tokenizador. Instanciamos o token de padding do tokenizador para que não nos dê erro como antes.
InputPythonfrom transformers import AutoTokenizercheckpoints = "openai-community/gpt2"tokenizer = AutoTokenizer.from_pretrained(checkpoints)tokenizer.pad_token = tokenizer.eos_tokentokenizer.padding_side = "right"Copied
Vamos adicionar dois novos tokens de início de piada e fim de piada para ter mais controle
InputPythonnew_tokens = ['<SJ>', '<EJ>'] # Start and end of joke tokensnum_added_tokens = tokenizer.add_tokens(new_tokens)print(f"Added {num_added_tokens} tokens")Copied
Added 2 tokens
Criamos uma função para adicionar os novos tokens às frases.
InputPythonjoke_column = "Joke"def format_joke(example):example[joke_column] = '<SJ> ' + example['Joke'] + ' <EJ>'return exampleCopied
Selecionamos as colunas que não precisamos
InputPythonremove_columns = [column for column in train_dataset.column_names if column != joke_column]remove_columnsCopied
['ID']
Formatamos o conjunto de dados e eliminamos as colunas que não precisamos
InputPythontrain_dataset = train_dataset.map(format_joke, remove_columns=remove_columns)validation_dataset = validation_dataset.map(format_joke, remove_columns=remove_columns)test_dataset = test_dataset.map(format_joke, remove_columns=remove_columns)train_dataset, validation_dataset, test_datasetCopied
(Dataset({features: ['Joke'],num_rows: 208491}),Dataset({features: ['Joke'],num_rows: 11583}),Dataset({features: ['Joke'],num_rows: 11583}))
Agora criamos uma função para tokenizar os piadas
InputPythondef tokenize_function(examples):return tokenizer(examples[joke_column], padding="max_length", truncation=True, max_length=768, return_tensors="pt")Copied
Tokenizamos o conjunto de dados e removemos a coluna com o texto
InputPythontrain_dataset = train_dataset.map(tokenize_function, batched=True, remove_columns=[joke_column])validation_dataset = validation_dataset.map(tokenize_function, batched=True, remove_columns=[joke_column])test_dataset = test_dataset.map(tokenize_function, batched=True, remove_columns=[joke_column])train_dataset, validation_dataset, test_datasetCopied
(Dataset({features: ['input_ids', 'attention_mask'],num_rows: 208491}),Dataset({features: ['input_ids', 'attention_mask'],num_rows: 11583}),Dataset({features: ['input_ids', 'attention_mask'],num_rows: 11583}))
Modelo
Agora instanciamos o modelo para geração de texto e atribuímos ao token de padding o token de end of string
InputPythonfrom transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained(checkpoints)model.config.pad_token_id = model.config.eos_token_idCopied
Vemos o tamanho do vocabulário do modelo
InputPythonvocab_size = model.config.vocab_sizevocab_sizeCopied
50257
Tem 50257 tokens, que é o tamanho do vocabulário do GPT2. Mas como dissemos que iríamos criar dois novos tokens com o início da piada e o fim da piada, os adicionamos ao modelo.
InputPythonmodel.resize_token_embeddings(len(tokenizer))new_vocab_size = model.config.vocab_sizeprint(f"Old vocab size: {vocab_size}. New vocab size: {new_vocab_size}. Added {new_vocab_size - vocab_size} tokens")Copied
Old vocab size: 50257. New vocab size: 50259. Added 2 tokens
Foram adicionados os dois novos tokens
Treinamento
Configuramos os parâmetros de treinamento
InputPythonfrom transformers import TrainingArgumentsmetric_name = "accuracy"model_name = "GPT2-small-finetuned-Maximofn-short-jokes-dataset-casualLM"output_dir = f"./training_results"LR = 2e-5BS_TRAIN = 28BS_EVAL = 32EPOCHS = 3WEIGHT_DECAY = 0.01WARMUP_STEPS = 100training_args = TrainingArguments(model_name,eval_strategy="epoch",save_strategy="epoch",learning_rate=LR,per_device_train_batch_size=BS_TRAIN,per_device_eval_batch_size=BS_EVAL,warmup_steps=WARMUP_STEPS,num_train_epochs=EPOCHS,weight_decay=WEIGHT_DECAY,lr_scheduler_type="cosine",warmup_ratio = 0.1,fp16=True,load_best_model_at_end=True,# metric_for_best_model=metric_name,push_to_hub=True,)Copied
Agora não usamos metric_for_best_model, depois de definir o treinador explicamos por que
Definimos o treinador
InputPythonfrom transformers import Trainertrainer = Trainer(model,training_args,train_dataset=train_dataset,eval_dataset=validation_dataset,tokenizer=tokenizer,# compute_metrics=compute_metrics,)Copied
Neste caso, não passamos uma função compute_metrics, mas sim, durante a avaliação, será usada a loss para avaliar o modelo. Por isso, ao definir os argumentos, não definimos metric_for_best_model, pois não vamos usar uma métrica para avaliar o modelo, mas sim a loss.
Treinamos
InputPythontrainer.train()Copied
0%| | 0/625473 [00:00<?, ?it/s]
---------------------------------------------------------------------------ValueError Traceback (most recent call last)Cell In[19], line 1----> 1 trainer.train()File ~/miniconda3/envs/nlp_/lib/python3.11/site-packages/transformers/trainer.py:1885, in Trainer.train(self, resume_from_checkpoint, trial, ignore_keys_for_eval, **kwargs)1883 hf_hub_utils.enable_progress_bars()1884 else:-> 1885 return inner_training_loop(1886 args=args,1887 resume_from_checkpoint=resume_from_checkpoint,1888 trial=trial,1889 ignore_keys_for_eval=ignore_keys_for_eval,1890 )File ~/miniconda3/envs/nlp_/lib/python3.11/site-packages/transformers/trainer.py:2216, in Trainer._inner_training_loop(self, batch_size, args, resume_from_checkpoint, trial, ignore_keys_for_eval)2213 self.control = self.callback_handler.on_step_begin(args, self.state, self.control)2215 with self.accelerator.accumulate(model):-> 2216 tr_loss_step = self.training_step(model, inputs)2218 if (2219 args.logging_nan_inf_filter2220 and not is_torch_xla_available()2221 and (torch.isnan(tr_loss_step) or torch.isinf(tr_loss_step))2222 ):2223 # if loss is nan or inf simply add the average of previous logged losses2224 tr_loss += tr_loss / (1 + self.state.global_step - self._globalstep_last_logged)File ~/miniconda3/envs/nlp_/lib/python3.11/site-packages/transformers/trainer.py:3238, in Trainer.training_step(self, model, inputs)3235 return loss_mb.reduce_mean().detach().to(self.args.device)3237 with self.compute_loss_context_manager():-> 3238 loss = self.compute_loss(model, inputs)3240 del inputs3241 torch.cuda.empty_cache()File ~/miniconda3/envs/nlp_/lib/python3.11/site-packages/transformers/trainer.py:3282, in Trainer.compute_loss(self, model, inputs, return_outputs)3280 else:3281 if isinstance(outputs, dict) and "loss" not in outputs:-> 3282 raise ValueError(3283 "The model did not return a loss from the inputs, only the following keys: "3284 f"{','.join(outputs.keys())}. For reference, the inputs it received are {','.join(inputs.keys())}."3285 )3286 # We don't use .loss here since the model may return tuples instead of ModelOutput.3287 loss = outputs["loss"] if isinstance(outputs, dict) else outputs[0]ValueError: The model did not return a loss from the inputs, only the following keys: logits,past_key_values. For reference, the inputs it received are input_ids,attention_mask.
Como vemos, nos dá um erro, dizendo que o modelo não retorna o valor do loss, que é fundamental para poder treinar, vamos ver por quê.
Vamos ver como é um exemplo do dataset
InputPythonidx = randint(0, len(train_dataset) - 1)sample = train_dataset[idx]sampleCopied
{'input_ids': [50257,4162,750,262,18757,6451,2245,2491,30,4362,340,373,734,10032,13,220,50258,50256,50256,...,50256,50256,50256],'attention_mask': [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,0,0,...,0,0,0]}
Como podemos ver, temos um dicionário com os input_ids e as attention_mask. Se o passarmos para o modelo, obtemos isso
InputPythonimport torchoutput = model(input_ids=torch.Tensor(sample["input_ids"]).long().unsqueeze(0).to(model.device),attention_mask=torch.Tensor(sample["attention_mask"]).long().unsqueeze(0).to(model.device),)print(output.loss)Copied
None
Como vemos, não retorna o valor da loss porque está esperando um valor para labels, que não foi fornecido. No exemplo anterior, em que fazíamos fine tuning para classificação de texto, dissemos que as etiquetas devem ser passadas para um campo do dataset chamado labels, mas neste caso não temos esse campo no dataset.
Se agora atribuirmos as labels aos input_ids e voltarmos a ver a loss
InputPythonimport torchoutput = model(input_ids=torch.Tensor(sample["input_ids"]).long().unsqueeze(0).to(model.device),attention_mask=torch.Tensor(sample["attention_mask"]).long().unsqueeze(0).to(model.device),labels=torch.Tensor(sample["input_ids"]).long().unsqueeze(0).to(model.device))print(output.loss)Copied
tensor(102.1873, device='cuda:0', grad_fn=<NllLossBackward0>)
Agora sim obtemos uma loss
Portanto, temos duas opções: adicionar um campo labels ao dataset, com os valores de input_ids, ou utilizar uma função da biblioteca transformers chamada data_collator. Neste caso, usaremos DataCollatorForLanguageModeling. Vamos ver isso.
InputPythonfrom transformers import DataCollatorForLanguageModelingmy_data_collator=DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)Copied
Passamos a amostra sample por este data_collator
InputPythoncollated_sample = my_data_collator([sample]).to(model.device)Copied
Vemos como é a saída
InputPythonfor key, value in collated_sample.items():print(f"{key} ({value.shape}): {value}")Copied
input_ids (torch.Size([1, 768])): tensor([[50257, 4162, 750, 262, 18757, 6451, 2245, 2491, 30, 4362,340, 373, 734, 10032, 13, 220, 50258, 50256, ..., 50256, 50256]],device='cuda:0')attention_mask (torch.Size([1, 768])): tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, ..., 0, 0]],device='cuda:0')labels (torch.Size([1, 768])): tensor([[50257, 4162, 750, 262, 18757, 6451, 2245, 2491, 30, 4362,340, 373, 734, 10032, 13, 220, 50258, -100, ..., -100, -100]],device='cuda:0')
Como se pode ver, o data_collator criou um campo labels e lhe atribuiu os valores de input_ids. Os tokens que estão mascarados receberam o valor -100. Isso ocorre porque quando definimos o data_collator, passamos o parâmetro mlm=False, o que significa que não estamos fazendo Masked Language Modeling, mas sim Language Modeling, por isso nenhum token original é mascarado.
Vamos ver se agora obtemos uma loss com esse data_collator
InputPythonoutput = model(**collated_sample)output.lossCopied
tensor(102.7181, device='cuda:0', grad_fn=<NllLossBackward0>)
Então, redefinimos o trainer com o data_collator e treinamos novamente.
InputPythonfrom transformers import DataCollatorForLanguageModelingtrainer = Trainer(model,training_args,train_dataset=train_dataset,eval_dataset=validation_dataset,tokenizer=tokenizer,data_collator=DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False),)Copied
InputPythontrainer.train()Copied
<IPython.core.display.HTML object>
There were missing keys in the checkpoint model loaded: ['lm_head.weight'].
TrainOutput(global_step=22341, training_loss=3.505178199598342, metrics={'train_runtime': 9209.5353, 'train_samples_per_second': 67.916, 'train_steps_per_second': 2.426, 'total_flos': 2.45146666696704e+17, 'train_loss': 3.505178199598342, 'epoch': 3.0})
Avaliação
Uma vez treinado, avaliamos o modelo sobre o dataset de teste.
InputPythontrainer.evaluate(eval_dataset=test_dataset)Copied
<IPython.core.display.HTML object>
{'eval_loss': 3.201305866241455,'eval_runtime': 65.0033,'eval_samples_per_second': 178.191,'eval_steps_per_second': 5.569,'epoch': 3.0}
Publicar o modelo
Criamos o cartão do modelo
InputPythontrainer.create_model_card()Copied
Publicamos
InputPythontrainer.push_to_hub()Copied
events.out.tfevents.1720875425.8de3af1b431d.6946.1: 0%| | 0.00/364 [00:00<?, ?B/s]
CommitInfo(commit_url='https://huggingface.co/Maximofn/GPT2-small-finetuned-Maximofn-short-jokes-dataset-casualLM/commit/d107b3bb0e02076483238f9975697761015ec390', commit_message='End of training', commit_description='', oid='d107b3bb0e02076483238f9975697761015ec390', pr_url=None, pr_revision=None, pr_num=None)
Uso do modelo
Limpez tudo o possível
InputPythonimport torchimport gcdef clear_hardwares():torch.clear_autocast_cache()torch.cuda.ipc_collect()torch.cuda.empty_cache()gc.collect()clear_hardwares()clear_hardwares()Copied
Baixamos o modelo e o tokenizador
InputPythonfrom transformers import AutoTokenizer, AutoModelForCausalLMuser = "maximofn"checkpoints = f"{user}/{model_name}"tokenizer = AutoTokenizer.from_pretrained(checkpoints)tokenizer.pad_token = tokenizer.eos_tokentokenizer.padding_side = "right"model = AutoModelForCausalLM.from_pretrained(checkpoints)model.config.pad_token_id = model.config.eos_token_idCopied
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Verificamos que o tokenizador e o modelo tenham os 2 tokens extras que adicionamos.
InputPythontokenizer_vocab = tokenizer.get_vocab()model_vocab = model.config.vocab_sizeprint(f"tokenizer_vocab: {len(tokenizer_vocab)}. model_vocab: {model_vocab}")Copied
tokenizer_vocab: 50259. model_vocab: 50259
Vemos que têm 50259 tokens, ou seja, os 50257 tokens do GPT2 mais os 2 que adicionamos.
Criamos uma função para gerar piadas
InputPythondef generate_joke(prompt_text):text = f"<SJ> {prompt_text}"tokens = tokenizer(text, return_tensors="pt").to(model.device)with torch.no_grad():output = model.generate(**tokens, max_new_tokens=256, eos_token_id=tokenizer.encode("<EJ>")[-1])return tokenizer.decode(output[0], skip_special_tokens=False)Copied
Geramos uma piada
InputPythongenerate_joke("Why didn't the frog cross the road?")Copied
Setting `pad_token_id` to `eos_token_id`:50258 for open-end generation.
"<SJ> Why didn't the frog cross the road? Because he was frog-in-the-face. <EJ>"
Se quiser testar mais o modelo, você pode vê-lo em Maximofn/GPT2-small-finetuned-Maximofn-short-jokes-dataset-casualLM
Ajuste fino para classificação de texto com Pytorch
Repetimos o treinamento com Pytorch
Reiniciamos o notebook para nos assegurar
Conjunto de Dados
Baixamos o mesmo conjunto de dados que quando fizemos o treinamento com as bibliotecas do Hugging Face
InputPythonfrom datasets import load_datasetdataset = load_dataset("mteb/amazon_reviews_multi", "en")Copied
Criamos uma variável com o número de classes
InputPythonnum_classes = len(dataset['train'].unique('label'))num_classesCopied
5
Antes processávamos todo o conjunto de dados para criar um campo chamado labels, mas agora não é necessário porque, como vamos programar tudo nós mesmos, nos adaptamos a como é o conjunto de dados.
Tokenizador
Criamos o tokenizador. Atribuímos o token de padding para que não nos dê erro como antes.
InputPythonfrom transformers import AutoTokenizercheckpoint = "openai-community/gpt2"tokenizer = AutoTokenizer.from_pretrained(checkpoint)tokenizer.pad_token = tokenizer.eos_tokenCopied
Criamos uma função para tokenizar o dataset
InputPythondef tokenize_function(examples):return tokenizer(examples["text"], padding="max_length", truncation=True, max_length=768, return_tensors="pt")Copied
Tokenizamos. Removemos colunas que não sejam necessárias, mas agora mantemos a de texto.
InputPythondataset = dataset.map(tokenize_function, batched=True, remove_columns=['id', 'label_text'])Copied
InputPythondatasetCopied
DatasetDict({train: Dataset({features: ['text', 'label', 'input_ids', 'attention_mask'],num_rows: 200000})validation: Dataset({features: ['text', 'label', 'input_ids', 'attention_mask'],num_rows: 5000})test: Dataset({features: ['text', 'label', 'input_ids', 'attention_mask'],num_rows: 5000})})
InputPythonpercentage = 1subset_train = dataset['train'].select(range(int(len(dataset['train']) * percentage)))percentage = 1subset_validation = dataset['validation'].select(range(int(len(dataset['validation']) * percentage)))subset_test = dataset['test'].select(range(int(len(dataset['test']) * percentage)))print(f"len subset_train: {len(subset_train)}, len subset_validation: {len(subset_validation)}, len subset_test: {len(subset_test)}")Copied
len subset_train: 200000, len subset_validation: 5000, len subset_test: 5000
Modelo
Importamos os pesos e atribuímos o token de padding
InputPythonfrom transformers import AutoModelForSequenceClassificationmodel = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_classes)model.config.pad_token_id = model.config.eos_token_idCopied
Some weights of GPT2ForSequenceClassification were not initialized from the model checkpoint at openai-community/gpt2 and are newly initialized: ['score.weight']You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Dispositivo
Criamos o dispositivo onde tudo será executado
InputPythonimport torchdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')Copied
De passagem, transferimos o modelo para o dispositivo e, de passagem, o convertemos para FP16 para ocupar menos memória
InputPythonmodel.half().to(device)print()Copied
Conjunto de Dados do Pytorch
Criamos um dataset de pytorch
InputPythonfrom torch.utils.data import Datasetclass ReviewsDataset(Dataset):def __init__(self, huggingface_dataset):self.dataset = huggingface_datasetdef __getitem__(self, idx):label = self.dataset[idx]['label']input_ids = torch.tensor(self.dataset[idx]['input_ids'])attention_mask = torch.tensor(self.dataset[idx]['attention_mask'])return input_ids, attention_mask, labeldef __len__(self):return len(self.dataset)Copied
Instanciamos os datasets
InputPythontrain_dataset = ReviewsDataset(subset_train)validatation_dataset = ReviewsDataset(subset_validation)test_dataset = ReviewsDataset(subset_test)Copied
Vamos dar uma olhada em um exemplo
InputPythoninput_ids, at_mask, label = train_dataset[0]input_ids.shape, at_mask.shape, labelCopied
(torch.Size([768]), torch.Size([768]), 0)
Pytorch Dataloader
Criamos agora um DataLoader do PyTorch
InputPythonfrom torch.utils.data import DataLoaderBS = 12train_loader = DataLoader(train_dataset, batch_size=BS, shuffle=True)validation_loader = DataLoader(validatation_dataset, batch_size=BS)test_loader = DataLoader(test_dataset, batch_size=BS)Copied
Vamos dar uma olhada em um exemplo
InputPythoninput_ids, at_mask, labels = next(iter(train_loader))input_ids.shape, at_mask.shape, labelsCopied
(torch.Size([12, 768]),torch.Size([12, 768]),tensor([2, 1, 2, 0, 3, 3, 0, 4, 3, 3, 4, 2]))
Para verificar se tudo está bem, passamos a amostra ao modelo para ver se tudo sai bem. Primeiro passamos os tokens para o dispositivo.
InputPythoninput_ids = input_ids.to(device)at_mask = at_mask.to(device)labels = labels.to(device)Copied
Agora passamos isso para o modelo
InputPythonoutput = model(input_ids=input_ids, attention_mask=at_mask, labels=labels)output.keys()Copied
odict_keys(['loss', 'logits', 'past_key_values'])
Como vemos, nos dá a loss e os logits
InputPythonoutput['loss']Copied
tensor(5.9414, device='cuda:0', dtype=torch.float16,grad_fn=<NllLossBackward0>)
InputPythonoutput['logits']Copied
tensor([[ 6.1953e+00, -1.2275e+00, -2.4824e+00, 5.8867e+00, -1.4734e+01],[ 5.4062e+00, -8.4570e-01, -2.3203e+00, 5.1055e+00, -1.1555e+01],[ 6.1641e+00, -9.3066e-01, -2.5664e+00, 6.0039e+00, -1.4570e+01],[ 5.2266e+00, -4.2358e-01, -2.0801e+00, 4.7461e+00, -1.1570e+01],[ 3.8184e+00, -2.3460e-03, -1.7666e+00, 3.4160e+00, -7.7969e+00],[ 4.1641e+00, -4.8169e-01, -1.6914e+00, 3.9941e+00, -8.7734e+00],[ 4.6758e+00, -3.0298e-01, -2.1641e+00, 4.1055e+00, -9.3359e+00],[ 4.1953e+00, -3.2471e-01, -2.1875e+00, 3.9375e+00, -8.3438e+00],[-1.1650e+00, 1.3564e+00, -6.2158e-01, -6.8115e-01, 4.8672e+00],[ 4.4961e+00, -8.7891e-02, -2.2793e+00, 4.2812e+00, -9.3359e+00],[ 4.9336e+00, -2.6627e-03, -2.1543e+00, 4.3711e+00, -1.0742e+01],[ 5.9727e+00, -4.3152e-02, -1.4551e+00, 4.3438e+00, -1.2117e+01]],device='cuda:0', dtype=torch.float16, grad_fn=<IndexBackward0>)
Métrica
Vamos a criar uma função para obter a métrica, que neste caso vai ser a acurácia.
InputPythondef predicted_labels(logits):percent = torch.softmax(logits, dim=1)predictions = torch.argmax(percent, dim=1)return predictionsCopied
InputPythondef compute_accuracy(logits, labels):predictions = predicted_labels(logits)correct = (predictions == labels).float()return correct.mean()Copied
Vamos a ver se ele calcula bem.
InputPythoncompute_accuracy(output['logits'], labels).item()Copied
0.1666666716337204
Otimizador
Como vamos a precisar um otimizador, criamos um
InputPythonfrom transformers import AdamWLR = 2e-5optimizer = AdamW(model.parameters(), lr=LR)Copied
/usr/local/lib/python3.10/dist-packages/transformers/optimization.py:588: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warningwarnings.warn(
Treinamento
Criamos o loop de treinamento
InputPythonfrom tqdm import tqdmEPOCHS = 3accuracy = 0for epoch in range(EPOCHS):model.train()train_loss = 0progresbar = tqdm(train_loader, total=len(train_loader), desc=f'Epoch {epoch + 1}')for input_ids, at_mask, labels in progresbar:input_ids = input_ids.to(device)at_mask = at_mask.to(device)label = labels.to(device)output = model(input_ids=input_ids, attention_mask=at_mask, labels=label)loss = output['loss']train_loss += loss.item()optimizer.zero_grad()loss.backward()optimizer.step()progresbar.set_postfix({'train_loss': loss.item()})train_loss /= len(train_loader)progresbar.set_postfix({'train_loss': train_loss})model.eval()valid_loss = 0progresbar = tqdm(validation_loader, total=len(validation_loader), desc=f'Epoch {epoch + 1}')for input_ids, at_mask, labels in progresbar:input_ids = input_ids.to(device)at_mask = at_mask.to(device)labels = labels.to(device)output = model(input_ids=input_ids, attention_mask=at_mask, labels=labels)loss = output['loss']valid_loss += loss.item()step_accuracy = compute_accuracy(output['logits'], labels)accuracy += step_accuracyprogresbar.set_postfix({'valid_loss': loss.item(), 'accuracy': step_accuracy.item()})valid_loss /= len(validation_loader)accuracy /= len(validation_loader)progresbar.set_postfix({'valid_loss': valid_loss, 'accuracy': accuracy})Copied
Epoch 1: 100%|██████████| 16667/16667 [44:13<00:00, 6.28it/s, train_loss=nan]Epoch 1: 100%|██████████| 417/417 [00:32<00:00, 12.72it/s, valid_loss=nan, accuracy=0]Epoch 2: 100%|██████████| 16667/16667 [44:06<00:00, 6.30it/s, train_loss=nan]Epoch 2: 100%|██████████| 417/417 [00:32<00:00, 12.77it/s, valid_loss=nan, accuracy=0]Epoch 3: 100%|██████████| 16667/16667 [44:03<00:00, 6.30it/s, train_loss=nan]Epoch 3: 100%|██████████| 417/417 [00:32<00:00, 12.86it/s, valid_loss=nan, accuracy=0]
Uso do modelo
Vamos a testar o modelo que treinamos
Primeiro tokenizamos um texto
InputPythoninput_tokens = tokenize_function({"text": "I love this product. It is amazing."})input_tokens['input_ids'].shape, input_tokens['attention_mask'].shapeCopied
(torch.Size([1, 768]), torch.Size([1, 768]))
Agora passamos isso para o modelo.
InputPythonoutput = model(input_ids=input_tokens['input_ids'].to(device), attention_mask=input_tokens['attention_mask'].to(device))output['logits']Copied
tensor([[nan, nan, nan, nan, nan]], device='cuda:0', dtype=torch.float16,grad_fn=<IndexBackward0>)
Vemos as previsões desses logits
InputPythonpredicted = predicted_labels(output['logits'])predictedCopied
tensor([0], device='cuda:0')
Ajuste fino para geração de texto com Pytorch
Repetimos o treinamento com Pytorch
Reiniciamos o notebook para nos assegurar
Conjunto de Dados
Voltamos a baixar o conjunto de dados de piadas
InputPythonfrom datasets import load_datasetjokes = load_dataset("Maximofn/short-jokes-dataset")jokesCopied
DatasetDict({train: Dataset({features: ['ID', 'Joke'],num_rows: 231657})})
Criamos um subconjunto caso haja pouca memória
InputPythonpercent_of_train_dataset = 1 # If you want 50% of the dataset, set this to 0.5subset_dataset = jokes["train"].select(range(int(len(jokes["train"]) * percent_of_train_dataset)))subset_datasetCopied
Dataset({features: ['ID', 'Joke'],num_rows: 231657})
Dividimos o conjunto de dados em subconjuntos de treinamento, validação e teste.
InputPythonpercent_of_train_dataset = 0.90split_dataset = subset_dataset.train_test_split(train_size=int(subset_dataset.num_rows * percent_of_train_dataset), seed=19, shuffle=False)train_dataset = split_dataset["train"]validation_test_dataset = split_dataset["test"]split_dataset = validation_test_dataset.train_test_split(train_size=int(validation_test_dataset.num_rows * 0.5), seed=19, shuffle=False)validation_dataset = split_dataset["train"]test_dataset = split_dataset["test"]print(f"Size of the train set: {len(train_dataset)}. Size of the validation set: {len(validation_dataset)}. Size of the test set: {len(test_dataset)}")Copied
Size of the train set: 208491. Size of the validation set: 11583. Size of the test set: 11583
Tokenizador
Iniciamos o tokenizador e atribuímos ao token de padding o de end of string
InputPythonfrom transformers import AutoTokenizercheckpoints = "openai-community/gpt2"tokenizer = AutoTokenizer.from_pretrained(checkpoints)tokenizer.pad_token = tokenizer.eos_tokentokenizer.padding_side = "right"Copied
Adicionamos os tokens especiais de início e fim de piada
InputPythonnew_tokens = ['<SJ>', '<EJ>'] # Start and end of joke tokensnum_added_tokens = tokenizer.add_tokens(new_tokens)print(f"Added {num_added_tokens} tokens")Copied
Added 2 tokens
Os adicionamos ao dataset
InputPythonjoke_column = "Joke"def format_joke(example):example[joke_column] = '<SJ> ' + example['Joke'] + ' <EJ>'return exampleremove_columns = [column for column in train_dataset.column_names if column != joke_column]train_dataset = train_dataset.map(format_joke, remove_columns=remove_columns)validation_dataset = validation_dataset.map(format_joke, remove_columns=remove_columns)test_dataset = test_dataset.map(format_joke, remove_columns=remove_columns)train_dataset, validation_dataset, test_datasetCopied
(Dataset({features: ['Joke'],num_rows: 208491}),Dataset({features: ['Joke'],num_rows: 11583}),Dataset({features: ['Joke'],num_rows: 11583}))
Tokenizamos o conjunto de dados
InputPythondef tokenize_function(examples):return tokenizer(examples[joke_column], padding="max_length", truncation=True, max_length=768, return_tensors="pt")train_dataset = train_dataset.map(tokenize_function, batched=True, remove_columns=[joke_column])validation_dataset = validation_dataset.map(tokenize_function, batched=True, remove_columns=[joke_column])test_dataset = test_dataset.map(tokenize_function, batched=True, remove_columns=[joke_column])train_dataset, validation_dataset, test_datasetCopied
(Dataset({features: ['input_ids', 'attention_mask'],num_rows: 208491}),Dataset({features: ['input_ids', 'attention_mask'],num_rows: 11583}),Dataset({features: ['input_ids', 'attention_mask'],num_rows: 11583}))
Modelo
Instanciamos o modelo, atribuímos o token de padding e adicionamos os novos tokens de início de piada e fim de piada
InputPythonfrom transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained(checkpoints)model.config.pad_token_id = model.config.eos_token_idmodel.resize_token_embeddings(len(tokenizer))Copied
Embedding(50259, 768)
Dispositivo
Criamos o dispositivo e passamos o modelo para o dispositivo
InputPythonimport torchdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model.half().to(device)print()Copied
Conjunto de Dados do Pytorch
Criamos um conjunto de dados do PyTorch
InputPythonfrom torch.utils.data import Datasetclass JokesDataset(Dataset):def __init__(self, huggingface_dataset):self.dataset = huggingface_datasetdef __getitem__(self, idx):input_ids = torch.tensor(self.dataset[idx]['input_ids'])attention_mask = torch.tensor(self.dataset[idx]['attention_mask'])return input_ids, attention_maskdef __len__(self):return len(self.dataset)Copied
Instanciamos os conjuntos de dados de treinamento, validação e teste
InputPythontrain_pytorch_dataset = JokesDataset(train_dataset)validation_pytorch_dataset = JokesDataset(validation_dataset)test_pytorch_dataset = JokesDataset(test_dataset)Copied
Vamos ver um exemplo.
InputPythoninput_ids, attention_mask = train_pytorch_dataset[0]input_ids.shape, attention_mask.shapeCopied
(torch.Size([768]), torch.Size([768]))
Pytorch Dataloader
Criamos os dataloaders
InputPythonfrom torch.utils.data import DataLoaderBS = 28train_loader = DataLoader(train_pytorch_dataset, batch_size=BS, shuffle=True)validation_loader = DataLoader(validation_pytorch_dataset, batch_size=BS)test_loader = DataLoader(test_pytorch_dataset, batch_size=BS)Copied
Vemos uma amostra
InputPythoninput_ids, attention_mask = next(iter(train_loader))input_ids.shape, attention_mask.shapeCopied
(torch.Size([28, 768]), torch.Size([28, 768]))
Passamos isso para o modelo.
InputPythonoutput = model(input_ids.to(device), attention_mask=attention_mask.to(device))output.keys()Copied
odict_keys(['logits', 'past_key_values'])
Como podemos ver, não temos um valor de loss. Como já vimos, precisamos passar o input_ids e o labels.
InputPythonoutput = model(input_ids.to(device), attention_mask=attention_mask.to(device), labels=input_ids.to(device))output.keys()Copied
odict_keys(['loss', 'logits', 'past_key_values'])
Agora sim temos loss
InputPythonoutput['loss'].item()Copied
80.5625
Otimizador
Criamos um otimizador
InputPythonfrom transformers import AdamWLR = 2e-5optimizer = AdamW(model.parameters(), lr=5e-5)Copied
/usr/local/lib/python3.10/dist-packages/transformers/optimization.py:588: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warningwarnings.warn(
Treinamento
Criamos o loop de treinamento
InputPythonfrom tqdm import tqdmEPOCHS = 3for epoch in range(EPOCHS):model.train()train_loss = 0progresbar = tqdm(train_loader, total=len(train_loader), desc=f'Epoch {epoch + 1}')for input_ids, at_mask in progresbar:input_ids = input_ids.to(device)at_mask = at_mask.to(device)output = model(input_ids=input_ids, attention_mask=at_mask, labels=input_ids)loss = output['loss']train_loss += loss.item()optimizer.zero_grad()loss.backward()optimizer.step()progresbar.set_postfix({'train_loss': loss.item()})train_loss /= len(train_loader)progresbar.set_postfix({'train_loss': train_loss})Copied
Epoch 1: 100%|██████████| 7447/7447 [51:07<00:00, 2.43it/s, train_loss=nan]Epoch 2: 100%|██████████| 7447/7447 [51:06<00:00, 2.43it/s, train_loss=nan]Epoch 3: 100%|██████████| 7447/7447 [51:07<00:00, 2.43it/s, train_loss=nan]
Uso do modelo
Testamos o modelo
InputPythondef generate_text(decoded_joke, max_new_tokens=100, stop_token='<EJ>', top_k=0, temperature=1.0):input_tokens = tokenize_function({'Joke': decoded_joke})output = model(input_tokens['input_ids'].to(device), attention_mask=input_tokens['attention_mask'].to(device))nex_token = torch.argmax(output['logits'][:, -1, :], dim=-1).item()nex_token_decoded = tokenizer.decode(nex_token)decoded_joke = decoded_joke + nex_token_decodedfor _ in range(max_new_tokens):nex_token = torch.argmax(output['logits'][:, -1, :], dim=-1).item()nex_token_decoded = tokenizer.decode(nex_token)if nex_token_decoded == stop_token:breakdecoded_joke = decoded_joke + nex_token_decodedinput_tokens = tokenize_function({'Joke': decoded_joke})output = model(input_tokens['input_ids'].to(device), attention_mask=input_tokens['attention_mask'].to(device))return decoded_jokeCopied
InputPythongenerated_text = generate_text("<SJ> Why didn't the frog cross the road")generated_textCopied
"<SJ> Why didn't the frog cross the road!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!"

















