
Aviso: Este post foi traduzido para o português usando um modelo de tradução automática. Por favor, me avise se encontrar algum erro.
📚 **Esta entrada faz parte da série _Guia completo do LangGraph_**, dividida em quatro capítulos que são lidos em ordem:
> * 👉 **Parte 1: Chatbot básico y herramientas**
* Parte 2: Memória de curto prazo
* Parte 3: Memória de longo prazo e human-in-the-loop
* Parte 4: Personalização do estado e checkpoints
LangGraph é um framework de orquestração de baixo nível para construir agentes controláveis
Enquanto LangChain fornece integrações e componentes para agilizar o desenvolvimento de aplicações LLM, a biblioteca LangGraph permite a orquestração de agentes, oferecendo arquiteturas personalizáveis, memória de longo prazo e human in the loop para lidar de forma confiável com tarefas complexas.
Neste post vamos desabilitar
LangSmith, que é uma ferramenta de depuração de grafos. Vamos desabilitá-lo para não adicionar mais complexidade ao post e focar apenas emLangGraph
Como funciona LangGraph?
LangGraph baseia-se em três componentes:
- Nós: Representam as unidades de processamento da aplicação, como chamar um LLM ou uma ferramenta. São funções em Python que são executadas quando o nó é chamado.
- Tomar o estado como entrada
- Realizam alguma operação
- Devolvem o estado atualizado * Arestas: Representam as transições entre os nós. Definem a lógica de como o grafo será executado, ou seja, qual nó será executado depois de outro. Podem ser:
- Diretos: Vão de um nó a outro
- Condicionais: Dependem de uma condição
- State: Representa o estado da aplicação, ou seja, contém toda a informação necessária para a aplicação. Mantém-se durante a execução da aplicação. É definido pelo utilizador, por isso é preciso pensar muito bem no que vai ser guardado nele.
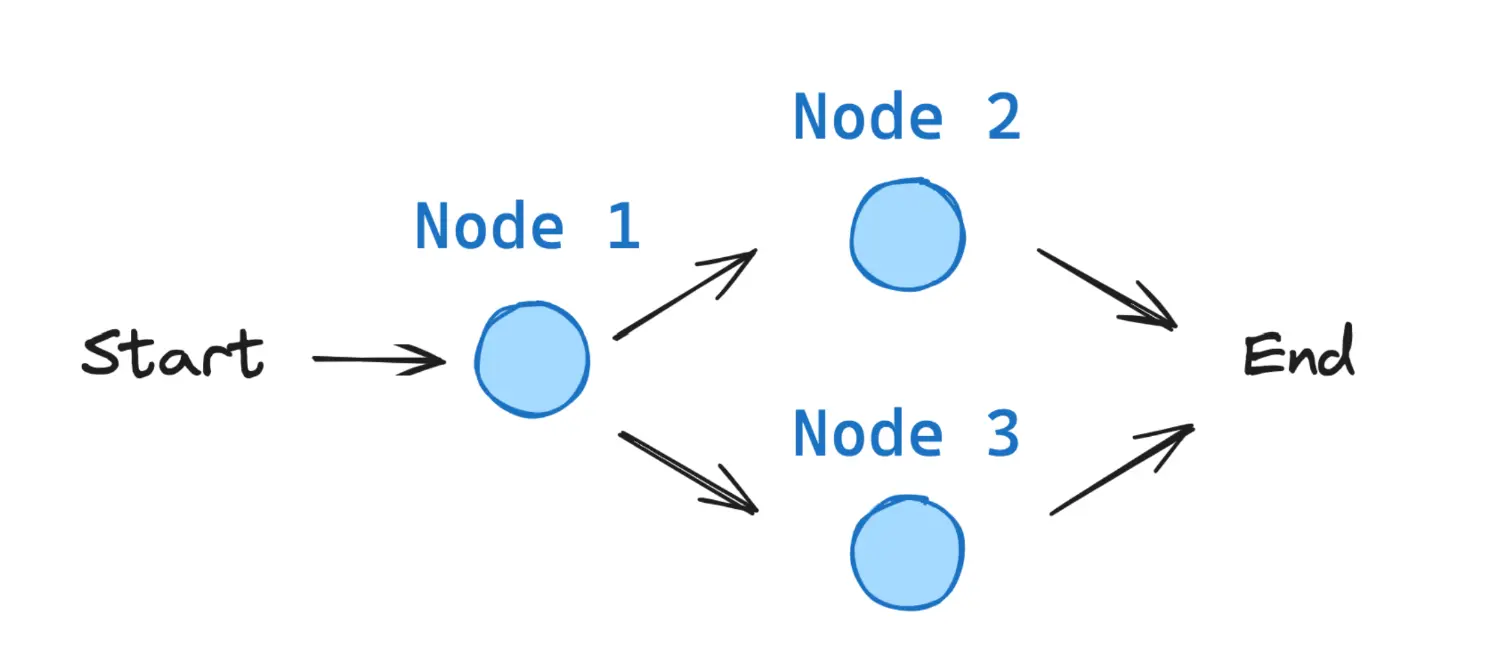
Todos os grafos do LangGraph começam a partir de um nó START e terminam em um nó END.
Instalação do LangGraph
Para instalar LangGraph você pode usar o pip:
pip install -U langgrapho instalar a partir do Conda:
conda install langgraphInstalação do módulo da Hugging Face e Anthropic
Vamos usar um modelo de linguagem do Hugging Face, por isso precisamos instalar seu pacote do LangGraph.
pip install langchain-huggingfacePara uma parte vamos usar Sonnet 3.7, depois explicaremos por quê. Então também instalamos o pacote da Anthropic.
pip install langchain_anthropicAPI KEY do Hugging Face
Vamos usar Qwen/Qwen2.5-72B-Instruct através de Hugging Face Inference Endpoints, portanto precisamos de uma API KEY.
Para poder usar o Inference Endpoints do HuggingFace, a primeira coisa que você precisa é ter uma conta no HuggingFace. Uma vez que a tenha, é preciso ir para Access tokens na configuração do seu perfil e gerar um novo token.
É preciso dar-lhe um nome. No meu caso, vou chamar langgraph e habilitar a permissão Make calls to inference providers. Ele nos criará um token que teremos de copiar
Para gerenciar o token, vamos criar um arquivo no mesmo caminho em que estamos trabalhando chamado .env e vamos colocar o token que copiamos no arquivo da seguinte maneira:
HUGGINGFACE_LANGGRAPH="hf_...."Agora, para poder obter o token, precisamos ter instalado dotenv, que instalamos por meio de
pip install python-dotenvExecutamos o seguinte
InputPythonimport osimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")Copied
Agora que temos um token, criamos um cliente. Para isso, precisamos ter instalada a biblioteca huggingface_hub. Instalamo-la usando conda ou pip.
pip install --upgrade huggingface_hubo
conda install -c conda-forge huggingface_hubAgora temos que escolher qual modelo vamos usar. Você pode ver os modelos disponíveis na página de Supported models da documentação de Inference Endpoints da Hugging Face.
Vamos usar Qwen2.5-72B-Instruct, que é um modelo muito bom.
InputPythonMODEL = "Qwen/Qwen2.5-72B-Instruct"Copied
Agora podemos criar o cliente
InputPythonfrom huggingface_hub import InferenceClientclient = InferenceClient(api_key=HUGGINGFACE_TOKEN, model=MODEL)clientCopied
<InferenceClient(model='Qwen/Qwen2.5-72B-Instruct', timeout=None)>
Fazemos um teste para ver se funciona
InputPythonmessage = [{ "role": "user", "content": "Hola, qué tal?" }]stream = client.chat.completions.create(messages=message,temperature=0.5,max_tokens=1024,top_p=0.7,stream=False)response = stream.choices[0].message.contentprint(response)Copied
¡Hola! Estoy bien, gracias por preguntar. ¿Cómo estás tú? ¿En qué puedo ayudarte hoy?
API KEY da Anthropic
Criar um chatbot básico
Vamos a criar um chatbot simples usando LangGraph. Este chatbot responderá diretamente às mensagens do usuário. Embora seja simples, nos servirá para ver os conceitos básicos da construção de grafos com LangGraph.
Como o nome indica, LangGraph é uma biblioteca para lidar com grafos. Então começamos criando um grafo StateGraph.
Un StateGraph define a estrutura do nosso chatbot como uma máquina de estados. Adicionaremos nodos ao nosso grafo para representar os llms, tools e funções; os llms poderão fazer uso dessas tools e funções; e acrescentaremos edges para especificar como o bot deve fazer a transição entre esses nodos.
Então começamos criando um StateGraph que precisa de uma classe State para gerenciar o estado do grafo. Como agora vamos criar um chatbot simples, só precisamos gerenciar uma lista de mensagens no estado.
InputPythonfrom typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraphfrom langgraph.graph.message import add_messagesclass State(TypedDict):# Messages have the type "list". The `add_messages` function# in the annotation defines how this state key should be updated# (in this case, it appends messages to the list, rather than overwriting them)messages: Annotated[list, add_messages]graph_builder = StateGraph(State)Copied
A função add_messages une duas listas de mensagens.
Chegarão novas listas de mensagens, por isso serão unidas à lista de mensagens já existente. Cada lista de mensagens contém um ID, então são adicionadas com esse ID. Isso garante que as mensagens sejam apenas adicionadas, não substituídas, a menos que uma nova mensagem tenha o mesmo ID que uma já existente, caso em que ela é substituída.
add_messages é uma função redutora, é uma função responsável por atualizar o estado.
O grafo graph_builder que criamos recebe um estado State e devolve um novo estado State. Além disso, atualiza a lista de mensagens.
**Conceito**
> Ao definir um grafo, o primeiro passo é definir seu
State. OStateinclui o esquema do grafo e asreducer functionsque lidam com atualizações do estado.
> No nosso exemplo,
Stateé do tipoTypedDict(dicionário tipado) com uma chave:messages.>
add_messagesé umareducer functionque é utilizada para agregar novas mensagens à lista em vez de sobrescrevê-las na lista. Se uma chave de um estado não tem umareducer function, cada valor que chegar dessa chave sobrescreverá os valores anteriores.
>
add_messagesé umareducer functiondo langgraph, mas nós vamos poder criar as nossas
Agora vamos adicionar ao grafo o nó chatbot. Os nós representam unidades de trabalho. Em geral, são funções regulares de Python.
Adicionamos um nó com o método add_node que recebe o nome do nó e a função que será executada.
De modo que vamos a crear um LLM com HuggingFace, depois criaremos um chat model com LangChain que fará referência ao LLM criado. Uma vez que tenhamos definido um chat model, definimos a função que será executada no nó do nosso grafo. Essa função fará uma chamada ao chat model criado e devolverá o resultado.
Por último, vamos a adicionar um nó com a função do chatbot ao grafo
InputPythonfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom huggingface_hub import loginos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Define the chatbot functiondef chatbot_function(state: State):return {"messages": [llm.invoke(state["messages"])]}# The first argument is the unique node name# The second argument is the function or object that will be called whenever# the node is used.graph_builder.add_node("chatbot_node", chatbot_function)Copied
<langgraph.graph.state.StateGraph at 0x130548440>
Usamos ChatHuggingFace, que é um chat do tipo BaseChatModel, que é um tipo de chat base de LangChain. Uma vez criado o BaseChatModel, criamos a função chatbot_function, que será executada quando o nó for executado. E, por fim, criamos o nó chatbot_node e indicamos que ele tem de executar a função chatbot_function.
**Aviso**
> A função de nó
chatbot_functionrecebe o estadoStatecomo entrada e devolve um dicionário que contém uma atualização da listamessagespara a chavemensajes. Este é o padrão básico para todas as funções do nóLangGraph.
A reducer function do nosso grafo add_messages agregará as mensagens de resposta do llm a qualquer mensagem que já esteja no estado.
A seguir, adicionamos um nó entry. Isso informa ao nosso grafo onde começar seu trabalho sempre que o executamos.
InputPythonfrom langgraph.graph import STARTgraph_builder.add_edge(START, "chatbot_node")Copied
<langgraph.graph.state.StateGraph at 0x130548440>
Da mesma forma, adicionamos um nó finish. Isso indica ao grafo que, sempre que este nó for executado, ele pode encerrar o trabalho.
InputPythonfrom langgraph.graph import ENDgraph_builder.add_edge("chatbot_node", END)Copied
<langgraph.graph.state.StateGraph at 0x130548440>
Importamos START e END, que podem ser encontrados em constants, e são o primeiro e o último nó do nosso grafo.
Normalmente são nós virtuais
Finalmente, temos que compilar nosso grafo. Para isso, usamos o método construtor de grafos compile(). Isso cria um CompiledGraph que podemos usar para executar nossa aplicação.
InputPythongraph = graph_builder.compile()Copied
Podemos visualizar o grafo usando o método get_graph e um dos métodos de “desenho”, como draw_ascii ou draw_mermaid_png. O desenho de cada um dos métodos requer dependências adicionais.
InputPythonfrom IPython.display import Image, displaytry:display(Image(graph.get_graph().draw_mermaid_png()))except Exception as e:print(f"Error al visualizar el grafo: {e}")Copied
<IPython.core.display.Image object>
Agora podemos testar o chatbot!
**Conselho**
> No seguinte bloco de código, você pode sair do ciclo de chat a qualquer momento digitando
quit,exitouq.
InputPython# Colors for the terminalCOLOR_GREEN = "\033[32m"COLOR_YELLOW = "\033[33m"COLOR_RESET = "\033[0m"def stream_graph_updates(user_input: str):for event in graph.stream({"messages": [{"role": "user", "content": user_input}]}):for value in event.values():print(f"{COLOR_GREEN}User: {COLOR_RESET}{user_input}")print(f"{COLOR_YELLOW}Assistant: {COLOR_RESET}{value['messages'][-1].content}")while True:try:user_input = input("User: ")if user_input.lower() in ["quit", "exit", "q"]:print(f"{COLOR_GREEN}User: {COLOR_RESET}{user_input}")print(f"{COLOR_YELLOW}Assistant: {COLOR_RESET}Goodbye!")breakevents =stream_graph_updates(user_input)except:# fallback if input() is not availableuser_input = "What do you know about LangGraph?"print("User: " + user_input)stream_graph_updates(user_input)breakCopied
User: HelloAssistant: Hello! It's nice to meet you. How can I assist you today? Whether you have questions, need information, or just want to chat, I'm here to help!User: How are you doing?Assistant: I'm just a computer program, so I don't have feelings, but I'm here and ready to help you with any questions or tasks you have! How can I assist you today?User: Me well, I'm making a post about LangGraph, what do you think?Assistant: LangGraph is an intriguing topic, especially if you're delving into the realm of graph-based models and their applications in natural language processing (NLP). LangGraph, as I understand, is a framework or tool that leverages graph theory to improve or provide a new perspective on NLP tasks such as text classification, information extraction, and semantic analysis. By representing textual information as graphs (nodes for entities and edges for relationships), it can offer a more nuanced understanding of the context and semantics in language data.If you're making a post about it, here are a few points you might consider:1. **Introduction to LangGraph**: Start with a brief explanation of what LangGraph is and its core principles. How does it model language or text differently compared to traditional NLP approaches? What unique advantages does it offer by using graph-based methods?2. **Applications of LangGraph**: Discuss some of the key applications where LangGraph has been or can be applied. This could include improving the accuracy of sentiment analysis, enhancing machine translation, or optimizing chatbot responses to be more contextually aware.3. **Technical Innovations**: Highlight any technical innovations or advancements that LangGraph brings to the table. This could be about new algorithms, more efficient data structures, or novel ways of training models on graph data.4. **Challenges and Limitations**: It's also important to address the challenges and limitations of using graph-based methods in NLP. Performance, scalability, and the current state of the technology can be discussed here.5. **Future Prospects**: Wrap up with a look into the future of LangGraph and graph-based NLP in general. What are the upcoming trends, potential areas of growth, and how might these tools start impacting broader technology landscapes?Each section can help frame your post in a way that's informative and engaging for your audience, whether they're technical experts or casual readers looking for an introduction to this intriguing area of NLP.User: qAssistant: Goodbye!
**Parabéns!** Você construiu seu primeiro chatbot usando LangGraph. Este bot pode participar de uma conversa básica recebendo a entrada do usuário e gerando respostas usando o LLM que definimos.
Antes, íamos escrevendo o código pouco a pouco e pode ser que não tenha ficado muito claro. Fez-se assim para explicar cada parte do código, mas agora vamos reescrevê-lo, porém organizado de outra forma, o que fica mais claro à vista. Ou seja, agora que não é preciso explicar cada parte do código, nós a agrupamos de outra forma para que fique mais claro
InputPythonfrom typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom huggingface_hub import loginfrom IPython.display import Image, displayimport osos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracingimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")# Stateclass State(TypedDict):messages: Annotated[list, add_messages]# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Functiondef chatbot_function(state: State):return {"messages": [llm.invoke(state["messages"])]}# Start to build the graphgraph_builder = StateGraph(State)# Add nodes to the graphgraph_builder.add_node("chatbot_node", chatbot_function)# Add edgesgraph_builder.add_edge(START, "chatbot_node")graph_builder.add_edge("chatbot_node", END)# Compile the graphgraph = graph_builder.compile()# Display the graphtry:display(Image(graph.get_graph().draw_mermaid_png()))except Exception as e:print(f"Error al visualizar el grafo: {e}")Copied
<IPython.core.display.Image object>
Mais
Todos os blocos mais estão aí caso queiras aprofundar mais em LangGraph; caso contrário, podes ler tudo sem ler os blocos mais
Tipagem do estado
Vimos como criar um agente com um estado tipado usando TypedDict, mas também podemos criá-lo com outro tipo tipado.
Tipagem via TypeDict
É a forma que vimos antes, tipamos o estado como um dicionário usando a tipagem do Python TypeDict. Passamos uma chave e um valor para cada variável do nosso estado
from typing_extensions import TypedDict
from typing import Annotated
from langgraph.graph.message import add_messages
from langgraph.graph import StateGraph
class State(TypedDict):
messages: Annotated[list, add_messages]Para acessar as mensagens, fazemos isso como com qualquer dicionário, por meio de state["messages"]
Tipagem por meio de dataclass
Outra opção é usar o tipado dataclass do Python
from dataclasses import dataclass
from typing import Annotated
from langgraph.graph.message import add_messages
from langgraph.graph import StateGraph
@dataclass
class State:
messages: Annotated[list, add_messages]Como se pode ver, é semelhante à tipagem por meio de dicionários, mas agora, como o estado é uma classe, acessamos as mensagens por meio de state.messages
Tipagem com Pydantic
Pydantic é uma biblioteca muito usada para tipagem de dados em Python. Ela nos oferece a possibilidade de adicionar uma verificação de tipagem. Vamos verificar que a mensagem comece com 'User', 'Assistant' ou 'System'
from pydantic import BaseModel, field_validator, ValidationError
from typing import Annotated
from langgraph.graph.message import add_messages
class State(BaseModel):
messages: Annotated[list, add_messages] # Deve começar com 'User', 'Assistant' ou 'System'
@field_validator('messages')
@classmethod
def validate_messages(cls, value):
# Garanta que as mensagens comecem com `User`, `Assistant` ou `System`
se não value.startswith["'User'"] e não value.startswith["'Assistant'"] e não value.startswith["'System'"]:
raise ValueError("Message must start with 'User', 'Assistant' or 'System'")
return value
tente:
state = PydanticState(messages=["Hello"])
except ValidationError as e:
print("Erro de validação:", e)Redutores
Como dissemos, precisamos usar uma função do tipo Reducer para indicar como atualizar o estado, já que, caso contrário, os valores do estado serão sobrescritos.
Vamos a ver um exemplo de um grafo no qual não usamos uma função do tipo Reducer para indicar como atualizar o estado
InputPythonfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom IPython.display import Image, displayclass State(TypedDict):foo: intdef node_1(state):print("---Node 1---")return {"foo": state['foo'] + 1}def node_2(state):print("---Node 2---")return {"foo": state['foo'] + 1}def node_3(state):print("---Node 3---")return {"foo": state['foo'] + 1}# Build graphbuilder = StateGraph(State)builder.add_node("node_1", node_1)builder.add_node("node_2", node_2)builder.add_node("node_3", node_3)# Logicbuilder.add_edge(START, "node_1")builder.add_edge("node_1", "node_2")builder.add_edge("node_1", "node_3")builder.add_edge("node_2", END)builder.add_edge("node_3", END)# Addgraph = builder.compile()# Viewdisplay(Image(graph.get_graph().draw_mermaid_png()))Copied
<IPython.core.display.Image object>
Como vemos, definimos um grafo no qual primeiro é executado o nó 1 e depois o 2 e o 3. Vamos executá-lo para ver o que acontece.
InputPythonfrom langgraph.errors import InvalidUpdateErrortry:graph.invoke({"foo" : 1})except InvalidUpdateError as e:print(f"InvalidUpdateError occurred: {e}")Copied
---Node 1------Node 2------Node 3---InvalidUpdateError occurred: At key 'foo': Can receive only one value per step. Use an Annotated key to handle multiple values.For troubleshooting, visit: https://python.langchain.com/docs/troubleshooting/errors/INVALID_CONCURRENT_GRAPH_UPDATE
Obtemos um erro porque primeiro o nó 1 modifica o valor de foo e depois os nós 2 e 3 tentam modificar o valor de foo em paralelo, o que gera um erro
Então, para evitar isso, usamos uma função do tipo Reducer para indicar como modificar o estado
Redutores predefinidos
Usamos o tipo Annotated para especificar que é uma função do tipo Reducer. E usamos o operador add para adicionar um valor a uma lista
InputPythonfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom IPython.display import Image, displayfrom operator import addfrom typing import Annotatedclass State(TypedDict):foo: Annotated[list[int], add]def node_1(state):print("---Node 1---")return {"foo": [state['foo'][-1] + 1]}def node_2(state):print("---Node 2---")return {"foo": [state['foo'][-1] + 1]}def node_3(state):print("---Node 3---")return {"foo": [state['foo'][-1] + 1]}# Build graphbuilder = StateGraph(State)builder.add_node("node_1", node_1)builder.add_node("node_2", node_2)builder.add_node("node_3", node_3)# Logicbuilder.add_edge(START, "node_1")builder.add_edge("node_1", "node_2")builder.add_edge("node_1", "node_3")builder.add_edge("node_2", END)builder.add_edge("node_3", END)# Addgraph = builder.compile()# Viewdisplay(Image(graph.get_graph().draw_mermaid_png()))Copied
<IPython.core.display.Image object>
Vamos executá-lo de novo para ver o que acontece
InputPythongraph.invoke({"foo" : [1]})Copied
---Node 1------Node 2------Node 3---
{'foo': [1, 2, 3, 3]}
Como vemos, inicializamos o valor de foo em 1, o que é adicionado a uma lista. Depois o nó 1 soma 1 e o adiciona como novo valor na lista, ou seja, adiciona um 2. Por último, os nós 2 e 3 somam um ao último valor da lista, ou seja, os dois nós obtêm um 3 e os dois nós o adicionam ao final da lista, por isso a lista resultante tem dois 3 no final
Vamos ver o caso de que um ramo tenha mais nós do que outro
InputPythonfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom IPython.display import Image, displayfrom operator import addfrom typing import Annotatedclass State(TypedDict):foo: Annotated[list[int], add]def node_1(state):print("---Node 1---")return {"foo": [state['foo'][-1] + 1]}def node_2_1(state):print("---Node 2_1---")return {"foo": [state['foo'][-1] + 1]}def node_2_2(state):print("---Node 2_2---")return {"foo": [state['foo'][-1] + 1]}def node_3(state):print("---Node 3---")return {"foo": [state['foo'][-1] + 1]}# Build graphbuilder = StateGraph(State)builder.add_node("node_1", node_1)builder.add_node("node_2_1", node_2_1)builder.add_node("node_2_2", node_2_2)builder.add_node("node_3", node_3)# Logicbuilder.add_edge(START, "node_1")builder.add_edge("node_1", "node_2_1")builder.add_edge("node_1", "node_3")builder.add_edge("node_2_1", "node_2_2")builder.add_edge("node_2_2", END)builder.add_edge("node_3", END)# Addgraph = builder.compile()# Viewdisplay(Image(graph.get_graph().draw_mermaid_png()))Copied
<IPython.core.display.Image object>
Se agora executarmos o grafo
InputPythongraph.invoke({"foo" : [1]})Copied
---Node 1------Node 2_1------Node 3------Node 2_2---
{'foo': [1, 2, 3, 3, 4]}
O que aconteceu é que primeiro foi executado o nó 1, em seguida o nó 2_1, depois, em paralelo, os nós 2_2 e 3, e por último o nó END
Como definimos foo como uma lista de inteiros, e ela está tipada, se inicializarmos o estado com None obtemos um erro
InputPythontry:graph.invoke({"foo" : None})except TypeError as e:print(f"TypeError occurred: {e}")Copied
TypeError occurred: can only concatenate list (not "NoneType") to list
Vamos ver como consertá-lo com reducers personalizados
Redutores personalizados
Às vezes não podemos usar um Reducer predefinido e temos que criar o nosso
InputPythonfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom IPython.display import Image, displayfrom typing import Annotateddef reducer_function(current_list, new_item: list | None):if current_list is None:current_list = []if new_item is not None:return current_list + new_itemreturn current_listclass State(TypedDict):foo: Annotated[list[int], reducer_function]def node_1(state):print("---Node 1---")if len(state['foo']) == 0:return {'foo': [0]}return {"foo": [state['foo'][-1] + 1]}def node_2(state):print("---Node 2---")return {"foo": [state['foo'][-1] + 1]}def node_3(state):print("---Node 3---")return {"foo": [state['foo'][-1] + 1]}# Build graphbuilder = StateGraph(State)builder.add_node("node_1", node_1)builder.add_node("node_2", node_2)builder.add_node("node_3", node_3)# Logicbuilder.add_edge(START, "node_1")builder.add_edge("node_1", "node_2")builder.add_edge("node_1", "node_3")builder.add_edge("node_2", END)builder.add_edge("node_3", END)# Addgraph = builder.compile()# Viewdisplay(Image(graph.get_graph().draw_mermaid_png()))Copied
<IPython.core.display.Image object>
Se agora iniciarmos o grafo com um valor None, já não nos dá um erro
InputPythontry:graph.invoke({"foo" : None})except TypeError as e:print(f"TypeError occurred: {e}")Copied
---Node 1------Node 2------Node 3---
Múltiplos estados
Estados privados
Suponhamos que queremos ocultar variáveis do estado, por qualquer motivo, porque algumas variáveis só acrescentam ruído ou porque queremos manter alguma variável privada.
Se quisermos ter um estado privado, simplesmente o criamos.
InputPythonfrom typing_extensions import TypedDictfrom IPython.display import Image, displayfrom langgraph.graph import StateGraph, START, ENDclass OverallState(TypedDict):public_var: intclass PrivateState(TypedDict):private_var: intdef node_1(state: OverallState) -> PrivateState:print("---Node 1---")return {"private_var": state['public_var'] + 1}def node_2(state: PrivateState) -> OverallState:print("---Node 2---")return {"public_var": state['private_var'] + 1}# Build graphbuilder = StateGraph(OverallState)builder.add_node("node_1", node_1)builder.add_node("node_2", node_2)# Logicbuilder.add_edge(START, "node_1")builder.add_edge("node_1", "node_2")builder.add_edge("node_2", END)# Addgraph = builder.compile()# Viewdisplay(Image(graph.get_graph().draw_mermaid_png()))Copied
<IPython.core.display.Image object>
Como vemos, criamos o estado privado PrivateState e o estado público OverallState. Cada um com uma variável privada e uma pública. Primeiro, é executado o nó 1, que modifica a variável privada e a devolve. Depois, é executado o nó 2, que modifica a variável pública e a devolve. Vamos executar o grafo para ver o que acontece.
InputPythongraph.invoke({"public_var" : 1})Copied
---Node 1------Node 2---
{'public_var': 3}
Como vemos ao executar o grafo, passamos a variável pública public_var e obtemos na saída outra variável pública public_var com o valor modificado, mas nunca se acessou a variável privada private_var
Estados de entrada e saída
Podemos definir as variáveis de entrada e saída do grafo. Embora internamente o estado possa ter mais variáveis, definimos quais variáveis são de entrada para o grafo e quais variáveis são de saída.
InputPythonfrom typing_extensions import TypedDictfrom IPython.display import Image, displayfrom langgraph.graph import StateGraph, START, ENDclass InputState(TypedDict):question: strclass OutputState(TypedDict):answer: strclass OverallState(TypedDict):question: stranswer: strnotes: strdef thinking_node(state: InputState):return {"answer": "bye", "notes": "... his is name is Lance"}def answer_node(state: OverallState) -> OutputState:return {"answer": "bye Lance"}graph = StateGraph(OverallState, input=InputState, output=OutputState)graph.add_node("answer_node", answer_node)graph.add_node("thinking_node", thinking_node)graph.add_edge(START, "thinking_node")graph.add_edge("thinking_node", "answer_node")graph.add_edge("answer_node", END)graph = graph.compile()# Viewdisplay(Image(graph.get_graph().draw_mermaid_png()))Copied
<IPython.core.display.Image object>
Neste caso, o estado tem 3 variáveis, question, answer e notes. No entanto, definimos como entrada do grafo question e como saída do grafo answer. Portanto, o estado interno pode ter mais variáveis, mas elas não são consideradas na hora de invocar o grafo. Vamos executar o grafo para ver o que acontece
InputPythongraph.invoke({"question":"hi"})Copied
{'answer': 'bye Lance'}
Como vemos, metemos question no grafo e obtivemos answer na saída.
Manuseio do contexto
Vamos voltar a ver o código do chatbot básico
InputPythonfrom typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom huggingface_hub import loginfrom IPython.display import Image, displayimport osimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")class State(TypedDict):messages: Annotated[list, add_messages]os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Define the chatbot functiondef chatbot_function(state: State):return {"messages": [llm.invoke(state["messages"])]}# Create graph buildergraph_builder = StateGraph(State)# Add nodesgraph_builder.add_node("chatbot_node", chatbot_function)# Connect nodesgraph_builder.add_edge(START, "chatbot_node")graph_builder.add_edge("chatbot_node", END)# Compile the graphgraph = graph_builder.compile()display(Image(graph.get_graph().draw_mermaid_png()))Copied
<IPython.core.display.Image object>
Vamos criar um contexto que passaremos ao modelo
InputPythonfrom langchain_core.messages import AIMessage, HumanMessagemessages = [AIMessage(f"So you said you were researching ocean mammals?", name="Bot")]messages.append(HumanMessage(f"Yes, I know about whales. But what others should I learn about?", name="Lance"))for m in messages:m.pretty_print()Copied
================================== Ai Message ==================================Name: BotSo you said you were researching ocean mammals?================================ Human Message =================================Name: LanceYes, I know about whales. But what others should I learn about?
Se o passarmos ao grafo, obteremos a saída
InputPythonoutput = graph.invoke({'messages': messages})for m in output['messages']:m.pretty_print()Copied
================================== Ai Message ==================================Name: BotSo you said you were researching ocean mammals?================================ Human Message =================================Name: LanceYes, I know about whales. But what others should I learn about?================================== Ai Message ==================================That's a great topic! Besides whales, there are several other fascinating ocean mammals you might want to learn about. Here are a few:1. **Dolphins**: Highly intelligent and social, dolphins are found in all oceans of the world. They are known for their playful behavior and communication skills.2. **Porpoises**: Similar to dolphins but generally smaller and stouter, porpoises are less social and more elusive. They are found in coastal waters around the world.3. **Seals and Sea Lions**: These are semi-aquatic mammals that can be found in both Arctic and Antarctic regions, as well as in more temperate waters. They are known for their sleek bodies and flippers, and they differ in their ability to walk on land (sea lions can "walk" on their flippers, while seals can only wriggle or slide).4. **Walruses**: Known for their large tusks and whiskers, walruses are found in the Arctic. They are well-adapted to cold waters and have a thick layer of blubber to keep them warm.5. **Manatees and Dugongs**: These gentle, herbivorous mammals are often called "sea cows." They live in shallow, coastal areas and are found in tropical and subtropical regions. Manatees are found in the Americas, while dugongs are found in the Indo-Pacific region.6. **Otters**: While not fully aquatic, sea otters spend most of their lives in the water and are excellent swimmers. They are known for their dense fur, which keeps them warm in cold waters.7. **Polar Bears**: Although primarily considered land animals, polar bears are excellent swimmers and spend a significant amount of time in the water, especially when hunting for seals.Each of these mammals has unique adaptations and behaviors that make them incredibly interesting to study. If you have any specific questions or topics you'd like to explore further, feel free to ask!
Como vemos agora na saída, temos mais uma mensagem.
Se isto continuar crescendo, chegará um momento em que teremos um contexto muito longo, o que implicará um maior gasto de tokens, podendo acarretar um maior custo econômico e também maior latência.
Além disso, com contextos muito longos, os LLMs começam a apresentar pior desempenho.
Nos últimos modelos, na data de escrita deste post, acima de 8k tokens de contexto, o desempenho do LLM começa a cair
Então, vamos ver várias maneiras de gerir isso
Modificar o contexto com funções do tipo Reducer
Vimos que, com as funções do tipo Reducer, podemos modificar as mensagens do estado
InputPythonfrom typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom langchain_core.messages import RemoveMessagefrom huggingface_hub import loginfrom IPython.display import Image, displayimport osimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")class State(TypedDict):messages: Annotated[list, add_messages]os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Nodesdef filter_messages(state: State):# Delete all but the 2 most recent messagesdelete_messages = [RemoveMessage(id=m.id) for m in state["messages"][:-2]]return {"messages": delete_messages}def chat_model_node(state: State):return {"messages": [llm.invoke(state["messages"])]}# Create graph buildergraph_builder = StateGraph(State)# Add nodesgraph_builder.add_node("filter_messages_node", filter_messages)graph_builder.add_node("chatbot_node", chat_model_node)# Connecto nodesgraph_builder.add_edge(START, "filter_messages_node")graph_builder.add_edge("filter_messages_node", "chatbot_node")graph_builder.add_edge("chatbot_node", END)# Compile the graphgraph = graph_builder.compile()display(Image(graph.get_graph().draw_mermaid_png()))Copied
<IPython.core.display.Image object>
Como vemos no grafo, primeiro filtramos as mensagens e depois passamos o resultado para o modelo.
Voltamos a criar um contexto que passaremos ao modelo, mas agora com mais mensagens
InputPythonfrom langchain_core.messages import AIMessage, HumanMessagemessages = [AIMessage(f"So you said you were researching ocean mammals?", name="Bot")]messages.append(HumanMessage(f"Yes, I know about whales. But what others should I learn about?", name="Lance"))messages.append(AIMessage(f"I know about sharks too", name="Bot"))messages.append(HumanMessage(f"What others should I learn about?", name="Lance"))messages.append(AIMessage(f"I know about dolphins too", name="Bot"))messages.append(HumanMessage(f"Tell me more about dolphins", name="Lance"))for m in messages:m.pretty_print()Copied
================================== Ai Message ==================================Name: BotSo you said you were researching ocean mammals?================================ Human Message =================================Name: LanceYes, I know about whales. But what others should I learn about?================================== Ai Message ==================================Name: BotI know about sharks too================================ Human Message =================================Name: LanceWhat others should I learn about?================================== Ai Message ==================================Name: BotI know about dolphins too================================ Human Message =================================Name: LanceTell me more about dolphins
Se o passarmos ao grafo, obteremos a saída
InputPythonoutput = graph.invoke({'messages': messages})for m in output['messages']:m.pretty_print()Copied
================================== Ai Message ==================================Name: BotI know about dolphins too================================ Human Message =================================Name: LanceTell me more about dolphins================================== Ai Message ==================================Dolphins are highly intelligent marine mammals that are part of the family Delphinidae, which includes about 40 species. They are found in oceans worldwide, from tropical to temperate regions, and are known for their agility and playful behavior. Here are some interesting facts about dolphins:1. **Social Behavior**: Dolphins are highly social animals and often live in groups called pods, which can range from a few individuals to several hundred. Social interactions are complex and include cooperative behaviors, such as hunting and defending against predators.2. **Communication**: Dolphins communicate using a variety of sounds, including clicks, whistles, and body language. These sounds can be used for navigation (echolocation), communication, and social bonding. Each dolphin has a unique signature whistle that helps identify it to others in the pod.3. **Intelligence**: Dolphins are considered one of the most intelligent animals on Earth. They have large brains and display behaviors such as problem-solving, mimicry, and even the use of tools. Some studies suggest that dolphins can recognize themselves in mirrors, indicating a level of self-awareness.4. **Diet**: Dolphins are carnivores and primarily feed on fish and squid. They use echolocation to locate and catch their prey. Some species, like the bottlenose dolphin, have been observed using teamwork to herd fish into tight groups, making them easier to catch.5. **Reproduction**: Dolphins typically give birth to a single calf after a gestation period of about 10 to 12 months. Calves are born tail-first and are immediately helped to the surface for their first breath by their mother or another dolphin. Calves nurse for up to two years and remain dependent on their mothers for a significant period.6. **Conservation**: Many dolphin species are threatened by human activities such as pollution, overfishing, and habitat destruction. Some species, like the Indo-Pacific humpback dolphin and the Amazon river dolphin, are endangered. Conservation efforts are crucial to protect these animals and their habitats.7. **Human Interaction**: Dolphins have a long history of interaction with humans, often appearing in mythology and literature. In some cultures, they are considered sacred or bring good luck. Today, dolphins are popular in marine parks and are often the focus of eco-tourism activities, such as dolphin-watching tours.Dolphins continue to fascinate scientists and the general public alike, with ongoing research into their behavior, communication, and social structures providing new insights into these remarkable creatures.
Como se pode ver, a função de filtragem eliminou todas as mensagens, exceto as duas últimas, e essas duas mensagens foram passadas como contexto para o LLM.
Recortar mensagens
Outra solução é recortar cada mensagem da lista de mensagens que tenha muitos tokens; define-se um limite de tokens e elimina-se a mensagem que ultrapassa esse limite.
InputPythonfrom typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom langchain_core.messages import trim_messagesfrom huggingface_hub import loginfrom IPython.display import Image, displayimport osimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")class State(TypedDict):messages: Annotated[list, add_messages]os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Nodesdef trim_messages_node(state: State):# Trim the messages based on the specified parameterstrimmed_messages = trim_messages(state["messages"],max_tokens=100, # Maximum tokens allowed in the trimmed liststrategy="last", # Keep the latest messagestoken_counter=llm, # Use the LLM's tokenizer to count tokensallow_partial=True, # Allow cutting messages mid-way if needed)# Print the trimmed messages to see the effect of trim_messagesprint("--- trimmed messages (input to LLM) ---")for m in trimmed_messages:m.pretty_print()print("------------------------------------------------")# Invoke the LLM with the trimmed messagesresponse = llm.invoke(trimmed_messages)# Return the LLM's response in the correct state formatreturn {"messages": [response]}# Create graph buildergraph_builder = StateGraph(State)# Add nodesgraph_builder.add_node("trim_messages_node", trim_messages_node)# Connecto nodesgraph_builder.add_edge(START, "trim_messages_node")graph_builder.add_edge("trim_messages_node", END)# Compile the graphgraph = graph_builder.compile()display(Image(graph.get_graph().draw_mermaid_png()))Copied
<IPython.core.display.Image object>
Como vemos no grafo, primeiro filtramos as mensagens e depois passamos o resultado para o modelo.
Voltamos a criar um contexto que passaremos ao modelo, mas agora com mais mensagens
InputPythonfrom langchain_core.messages import AIMessage, HumanMessagemessages = [AIMessage(f"So you said you were researching ocean mammals?", name="Bot")]messages.append(HumanMessage(f"Yes, I know about whales. But what others should I learn about?", name="Lance"))messages.append(AIMessage(f"""I know about sharks too. They are very dangerous, but they are also very beautiful.Sometimes have been seen in the wild, but they are not very common. In the wild, they are very dangerous, but they are also very beautiful.They live in the sea and in the ocean. They can travel long distances and can be found in many parts of the world.Often they live in groups of 20 or more, but they are not very common.They should eat a lot of food. Normally they eat a lot of fish.The white shark is the largest of the sharks and is the most dangerous.The great white shark is the most famous of the sharks and is the most dangerous.The tiger shark is the most aggressive of the sharks and is the most dangerous.The hammerhead shark is the most beautiful of the sharks and is the most dangerous.The mako shark is the fastest of the sharks and is the most dangerous.The bull shark is the most common of the sharks and is the most dangerous.""", name="Bot"))messages.append(HumanMessage(f"What others should I learn about?", name="Lance"))messages.append(AIMessage(f"I know about dolphins too", name="Bot"))messages.append(HumanMessage(f"Tell me more about dolphins", name="Lance"))for m in messages:m.pretty_print()Copied
================================== Ai Message ==================================Name: BotSo you said you were researching ocean mammals?================================ Human Message =================================Name: LanceYes, I know about whales. But what others should I learn about?================================== Ai Message ==================================Name: BotI know about sharks too. They are very dangerous, but they are also very beautiful.Sometimes have been seen in the wild, but they are not very common. In the wild, they are very dangerous, but they are also very beautiful.They live in the sea and in the ocean. They can travel long distances and can be found in many parts of the world.Often they live in groups of 20 or more, but they are not very common.They should eat a lot of food. Normally they eat a lot of fish.The white shark is the largest of the sharks and is the most dangerous.The great white shark is the most famous of the sharks and is the most dangerous.The tiger shark is the most aggressive of the sharks and is the most dangerous.The hammerhead shark is the most beautiful of the sharks and is the most dangerous.The mako shark is the fastest of the sharks and is the most dangerous.The bull shark is the most common of the sharks and is the most dangerous.================================ Human Message =================================Name: LanceWhat others should I learn about?================================== Ai Message ==================================Name: BotI know about dolphins too================================ Human Message =================================Name: LanceTell me more about dolphins
Se o passarmos para o grafo, obteremos a saída
InputPythonoutput = graph.invoke({'messages': messages})Copied
--- trimmed messages (input to LLM) ---================================== Ai Message ==================================Name: BotThe tiger shark is the most aggressive of the sharks and is the most dangerous.The hammerhead shark is the most beautiful of the sharks and is the most dangerous.The mako shark is the fastest of the sharks and is the most dangerous.The bull shark is the most common of the sharks and is the most dangerous.================================ Human Message =================================Name: LanceWhat others should I learn about?================================== Ai Message ==================================Name: BotI know about dolphins too================================ Human Message =================================Name: LanceTell me more about dolphins------------------------------------------------
Como se pode ver, o contexto que é passado ao LLM foi recortado; a mensagem, que era muito longa e tinha muitos tokens, foi truncada. Vamos ver a saída do LLM.
InputPythonfor m in output['messages']:m.pretty_print()Copied
================================== Ai Message ==================================Name: BotSo you said you were researching ocean mammals?================================ Human Message =================================Name: LanceYes, I know about whales. But what others should I learn about?================================== Ai Message ==================================Name: BotI know about sharks too. They are very dangerous, but they are also very beautiful.Sometimes have been seen in the wild, but they are not very common. In the wild, they are very dangerous, but they are also very beautiful.They live in the sea and in the ocean. They can travel long distances and can be found in many parts of the world.Often they live in groups of 20 or more, but they are not very common.They should eat a lot of food. Normally they eat a lot of fish.The white shark is the largest of the sharks and is the most dangerous.The great white shark is the most famous of the sharks and is the most dangerous.The tiger shark is the most aggressive of the sharks and is the most dangerous.The hammerhead shark is the most beautiful of the sharks and is the most dangerous.The mako shark is the fastest of the sharks and is the most dangerous.The bull shark is the most common of the sharks and is the most dangerous.================================ Human Message =================================Name: LanceWhat others should I learn about?================================== Ai Message ==================================Name: BotI know about dolphins too================================ Human Message =================================Name: LanceTell me more about dolphins================================== Ai Message ==================================Certainly! Dolphins are intelligent marine mammals that are part of the family Delphinidae, which includes nearly 40 species. Here are some interesting facts about dolphins:1. **Intelligence**: Dolphins are known for their high intelligence and have large brains relative to their body size. They exhibit behaviors that suggest social complexity, self-awareness, and problem-solving skills. For example, they can recognize themselves in mirrors, a trait shared by only a few other species.2. **Communication**: Dolphins communicate using a variety of clicks, whistles, and body language. Each dolphin has a unique "signature whistle" that helps identify it to others, similar to a human name. They use echolocation to navigate and locate prey by emitting clicks and interpreting the echoes that bounce back.3. **Social Structure**: Dolphins are highly social animals and often live in groups called pods. These pods can vary in size from a few individuals to several hundred. Within these groups, dolphins form complex social relationships and often cooperate to hunt and protect each other from predators.4. **Habitat**: Dolphins are found in all the world's oceans and in some rivers. Different species have adapted to various environments, from tropical waters to the cooler regions of the open sea. Some species, like the Amazon river dolphin (also known as the boto), live in freshwater rivers.5. **Diet**: Dolphins are carnivores and primarily eat fish, squid, and crustaceans. Their diet can vary depending on the species and their habitat. Some species, like the killer whale (which is actually a large dolphin), can even hunt larger marine mammals.6. **Reproduction**: Dolphins have a long gestation period, typically around 10 to 12 months. Calves are born tail-first and are nursed by their mothers for up to two years. Dolphins often form strong bonds with their offspring and other members of their pod.7. **Conservation**: Many species of dolphins face threats such as pollution, overfishing, and entanglement in fishing nets. Conservation efforts are ongoing to protect these animals and their habitats. Organizations like the International Union for Conservation of Nature (IUCN) and the World Wildlife Fund (WWF) work to raise awareness and implement conservation measures.8. **Cultural Significance**: Dolphins have been a source of fascination and inspiration for humans for centuries. They appear in myths, legends, and art across many cultures and are often seen as symbols of intelligence, playfulness, and freedom.Dolphins are truly remarkable creatures with a lot to teach us about social behavior, communication, and the complexities of marine ecosystems. If you have any specific questions or want to know more about a particular species, feel free to ask!
Com um contexto reduzido, o LLM continua respondendo
Modificação do contexto e recorte de mensagens
Vamos combinar as duas técnicas anteriores, modificaremos o contexto e recortaremos as mensagens.
InputPythonfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom langchain_core.messages import RemoveMessage, trim_messagesfrom huggingface_hub import loginfrom IPython.display import Image, displayimport osimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")class State(TypedDict):messages: Annotated[list, add_messages]os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Nodesdef filter_messages(state: State):# Delete all but the 2 most recent messagesdelete_messages = [RemoveMessage(id=m.id) for m in state["messages"][:-2]]return {"messages": delete_messages}def trim_messages_node(state: State):# print the messagesprint("--- messages (input to trim_messages) ---")for m in state["messages"]:m.pretty_print()print("------------------------------------------------")# Trim the messages based on the specified parameterstrimmed_messages = trim_messages(state["messages"],max_tokens=100, # Maximum tokens allowed in the trimmed liststrategy="last", # Keep the latest messagestoken_counter=llm, # Use the LLM's tokenizer to count tokensallow_partial=True, # Allow cutting messages mid-way if needed)# Print the trimmed messages to see the effect of trim_messagesprint("--- trimmed messages (input to LLM) ---")for m in trimmed_messages:m.pretty_print()print("------------------------------------------------")# Invoke the LLM with the trimmed messagesresponse = llm.invoke(trimmed_messages)# Return the LLM's response in the correct state formatreturn {"messages": [response]}def chat_model_node(state: State):return {"messages": [llm.invoke(state["messages"])]}# Create graph buildergraph_builder = StateGraph(State)# Add nodesgraph_builder.add_node("filter_messages_node", filter_messages)graph_builder.add_node("chatbot_node", chat_model_node)graph_builder.add_node("trim_messages_node", trim_messages_node)# Connecto nodesgraph_builder.add_edge(START, "filter_messages_node")graph_builder.add_edge("filter_messages_node", "trim_messages_node")graph_builder.add_edge("trim_messages_node", "chatbot_node")graph_builder.add_edge("chatbot_node", END)# Compile the graphgraph = graph_builder.compile()display(Image(graph.get_graph().draw_mermaid_png()))Copied
<IPython.core.display.Image object>
Agora filtramos ficando com as duas últimas mensagens, depois fazemos o trim do contexto para não gastar muitos tokens e, por fim, passamos o resultado para o modelo.
Criamos um contexto para passá-lo ao grafo
InputPythonfrom langchain_core.messages import AIMessage, HumanMessagemessages = [AIMessage(f"So you said you were researching ocean mammals?", name="Bot")]messages.append(HumanMessage(f"Yes, I know about whales. But what others should I learn about?", name="Lance"))messages.append(AIMessage(f"I know about dolphins too", name="Bot"))messages.append(HumanMessage(f"What others should I learn about?", name="Lance"))messages.append(AIMessage(f"""I know about sharks too. They are very dangerous, but they are also very beautiful.Sometimes have been seen in the wild, but they are not very common. In the wild, they are very dangerous, but they are also very beautiful.They live in the sea and in the ocean. They can travel long distances and can be found in many parts of the world.Often they live in groups of 20 or more, but they are not very common.They should eat a lot of food. Normally they eat a lot of fish.The white shark is the largest of the sharks and is the most dangerous.The great white shark is the most famous of the sharks and is the most dangerous.The tiger shark is the most aggressive of the sharks and is the most dangerous.The hammerhead shark is the most beautiful of the sharks and is the most dangerous.The mako shark is the fastest of the sharks and is the most dangerous.The bull shark is the most common of the sharks and is the most dangerous.""", name="Bot"))messages.append(HumanMessage(f"What others should I learn about?", name="Lance"))for m in messages:m.pretty_print()Copied
================================== Ai Message ==================================Name: BotSo you said you were researching ocean mammals?================================ Human Message =================================Name: LanceYes, I know about whales. But what others should I learn about?================================== Ai Message ==================================Name: BotI know about dolphins too================================ Human Message =================================Name: LanceWhat others should I learn about?================================== Ai Message ==================================Name: BotI know about sharks too. They are very dangerous, but they are also very beautiful.Sometimes have been seen in the wild, but they are not very common. In the wild, they are very dangerous, but they are also very beautiful.They live in the sea and in the ocean. They can travel long distances and can be found in many parts of the world.Often they live in groups of 20 or more, but they are not very common.They should eat a lot of food. Normally they eat a lot of fish.The white shark is the largest of the sharks and is the most dangerous.The great white shark is the most famous of the sharks and is the most dangerous.The tiger shark is the most aggressive of the sharks and is the most dangerous.The hammerhead shark is the most beautiful of the sharks and is the most dangerous.The mako shark is the fastest of the sharks and is the most dangerous.The bull shark is the most common of the sharks and is the most dangerous.================================ Human Message =================================Name: LanceWhat others should I learn about?
Passamos isso ao grafo e obtemos a saída
InputPythonoutput = graph.invoke({'messages': messages})Copied
--- messages (input to trim_messages) ---================================== Ai Message ==================================Name: BotI know about sharks too. They are very dangerous, but they are also very beautiful.Sometimes have been seen in the wild, but they are not very common. In the wild, they are very dangerous, but they are also very beautiful.They live in the sea and in the ocean. They can travel long distances and can be found in many parts of the world.Often they live in groups of 20 or more, but they are not very common.They should eat a lot of food. Normally they eat a lot of fish.The white shark is the largest of the sharks and is the most dangerous.The great white shark is the most famous of the sharks and is the most dangerous.The tiger shark is the most aggressive of the sharks and is the most dangerous.The hammerhead shark is the most beautiful of the sharks and is the most dangerous.The mako shark is the fastest of the sharks and is the most dangerous.The bull shark is the most common of the sharks and is the most dangerous.================================ Human Message =================================Name: LanceWhat others should I learn about?--------------------------------------------------- trimmed messages (input to LLM) ---================================ Human Message =================================Name: LanceWhat others should I learn about?------------------------------------------------
Como se vê, ficamos apenas com a última mensagem; isso aconteceu porque a função de filtragem devolveu as duas últimas mensagens, mas a função de truncamento eliminou a penúltima mensagem por ter mais de 100 tokens.
Vamos ver o que temos na saída do modelo
InputPythonfor m in output['messages']:m.pretty_print()Copied
================================== Ai Message ==================================Name: BotI know about sharks too. They are very dangerous, but they are also very beautiful.Sometimes have been seen in the wild, but they are not very common. In the wild, they are very dangerous, but they are also very beautiful.They live in the sea and in the ocean. They can travel long distances and can be found in many parts of the world.Often they live in groups of 20 or more, but they are not very common.They should eat a lot of food. Normally they eat a lot of fish.The white shark is the largest of the sharks and is the most dangerous.The great white shark is the most famous of the sharks and is the most dangerous.The tiger shark is the most aggressive of the sharks and is the most dangerous.The hammerhead shark is the most beautiful of the sharks and is the most dangerous.The mako shark is the fastest of the sharks and is the most dangerous.The bull shark is the most common of the sharks and is the most dangerous.================================ Human Message =================================Name: LanceWhat others should I learn about?================================== Ai Message ==================================Certainly! To provide a more tailored response, it would be helpful to know what areas or topics you're interested in. However, here’s a general list of areas that are often considered valuable for personal and professional development:1. **Technology & Digital Skills**:- Programming languages (Python, JavaScript, etc.)...- Goal setting and motivation- Personal finance and budgeting- Critical thinking and problem solving8. **Social & Environmental Impact**:- Social entrepreneurship- Community organizing and activism- Sustainable living practices- Climate change and environmental policyIf you have a specific area of interest or a particular goal in mind, feel free to share, and I can provide more detailed recommendations!================================== Ai Message ==================================
Filtramos tanto o estado que o LLM não tem contexto suficiente; mais adiante veremos uma forma de resolver isso adicionando ao estado um resumo da conversa.
Modos de streaming
Streaming síncrono
Neste caso, vamos receber o resultado completo do LLM de uma só vez, assim que ele tiver terminado de gerar o texto.
Para explicar os modos de streaming síncrono, primeiro vamos criar um grafo básico.
InputPythonfrom typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom langchain_core.messages import HumanMessagefrom huggingface_hub import loginfrom IPython.display import Image, displayimport osimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")class State(TypedDict):messages: Annotated[list, add_messages]os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Nodesdef chat_model_node(state: State):# Return the LLM's response in the correct state formatreturn {"messages": [llm.invoke(state["messages"])]}# Create graph buildergraph_builder = StateGraph(State)# Add nodesgraph_builder.add_node("chatbot_node", chat_model_node)# Connecto nodesgraph_builder.add_edge(START, "chatbot_node")graph_builder.add_edge("chatbot_node", END)# Compile the graphgraph = graph_builder.compile()display(Image(graph.get_graph().draw_mermaid_png()))Copied
<IPython.core.display.Image object>
Agora temos duas maneiras de obter o resultado do LLM: uma é por meio do modo updates e a outra por meio do modo values.

Enquanto updates nos dá cada novo resultado, values nos dá todo o histórico de resultados.
Atualizações
InputPythonfor chunk in graph.stream({"messages": [HumanMessage(content="hi! I'm Máximo")]}, stream_mode="updates"):print(chunk['chatbot_node']['messages'][-1].content)Copied
Hello Máximo! It's nice to meet you. How can I assist you today? Feel free to ask me any questions or let me know if you need help with anything specific.
Valores
InputPythonfor chunk in graph.stream({"messages": [HumanMessage(content="hi! I'm Máximo")]}, stream_mode="values"):print(chunk['messages'][-1].content)Copied
hi! I'm MáximoHello Máximo! It's nice to meet you. How can I assist you today? Feel free to ask me any questions or let me know if you need help with anything specific.
Streaming assíncrono
Agora vamos receber o resultado do LLM token a token. Para isso temos que adicionar streaming=True quando criamos o LLM da HuggingFace e temos que mudar a função do nó do chatbot para que seja assíncrona.
InputPythonfrom typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom langchain_core.messages import HumanMessagefrom huggingface_hub import loginfrom IPython.display import Image, displayimport osimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")class State(TypedDict):messages: Annotated[list, add_messages]os.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracing# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,streaming=True,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Nodesasync def chat_model_node(state: State):async for token in llm.astream_log(state["messages"]):yield {"messages": [token]}# Create graph buildergraph_builder = StateGraph(State)# Add nodesgraph_builder.add_node("chatbot_node", chat_model_node)# Connecto nodesgraph_builder.add_edge(START, "chatbot_node")graph_builder.add_edge("chatbot_node", END)# Compile the graphgraph = graph_builder.compile()display(Image(graph.get_graph().draw_mermaid_png()))Copied
<IPython.core.display.Image object>
Como se pode ver, a função foi criada como assíncrona e se tornou um gerador, já que o yield devolve um valor e pausa a execução da função até que seja chamada novamente.
Vamos executar o grafo de forma assíncrona e ver os tipos de eventos que são gerados.
InputPythontry:async for event in graph.astream_events({"messages": [HumanMessage(content="hi! I'm Máximo")]}, version="v2"):print(f"event: {event}")except Exception as e:print(f"Error: {e}")Copied
event: {'event': 'on_chain_start', 'data': {'input': {'messages': [HumanMessage(content="hi! I'm Máximo", additional_kwargs={}, response_metadata={})]}}, 'name': 'LangGraph', 'tags': [], 'run_id': 'c9c40a00-157a-4229-a0d1-fda00e7bfd34', 'metadata': {}, 'parent_ids': []}event: {'event': 'on_chain_start', 'data': {'input': {'messages': [HumanMessage(content="hi! I'm Máximo", additional_kwargs={}, response_metadata={}, id='6469501c-07b0-42e4-a3e6-f133ace1860c')]}}, 'name': 'chatbot_node', 'tags': ['graph:step:1'], 'run_id': '638828c0-4add-4141-b6b6-484446100237', 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34']}event: {'event': 'on_chain_start', 'data': {}, 'name': 'chatbot_node', 'tags': ['seq:step:1'], 'run_id': '15247b1a-1cd6-4863-9402-66499f921244', 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237']}event: {'event': 'on_chat_model_start', 'data': {'input': {'messages': [[HumanMessage(content="hi! I'm Máximo", additional_kwargs={}, response_metadata={}, id='6469501c-07b0-42e4-a3e6-f133ace1860c')]]}}, 'name': 'ChatHuggingFace', 'tags': [], 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chain_stream', 'run_id': '15247b1a-1cd6-4863-9402-66499f921244', 'name': 'chatbot_node', 'tags': ['seq:step:1'], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd'}, 'data': {'chunk': {'messages': [RunLogPatch({'op': 'replace','path': '','value': {'final_output': None,'id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3','logs': {},'name': 'ChatHuggingFace','streamed_output': [],'type': 'llm'}})]}}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='Hello', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' Má', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='ximo', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='!', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' It', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content="'s", additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' nice', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' to', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' meet', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' you', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='.', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' How', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' can', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' I', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' assist', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' you', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' today', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='?', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' Feel', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' free', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' to', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' ask', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' me', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' any', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' questions', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}
/Users/macm1/miniforge3/envs/langgraph/lib/python3.13/site-packages/huggingface_hub/inference/_generated/_async_client.py:2308: FutureWarning: `stop_sequences` is a deprecated argument for `text_generation` task and will be removed in version '0.28.0'. Use `stop` instead.warnings.warn(
event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' or', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' let', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' me', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' know', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' if', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' you', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' need', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' help', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' with', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' anything', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content=' specific', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='.', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_stream', 'data': {'chunk': AIMessageChunk(content='<|im_end|>', additional_kwargs={}, response_metadata={})}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chat_model_end', 'data': {'output': AIMessage(content="Hello Máximo! It's nice to meet you. How can I assist you today? Feel free to ask me any questions or let me know if you need help with anything specific.<|im_end|>", additional_kwargs={}, response_metadata={}, id='run-74dfdbb9-4c2d-4a08-ad7d-795b5953cae3-0'), 'input': {'messages': [[HumanMessage(content="hi! I'm Máximo", additional_kwargs={}, response_metadata={}, id='6469501c-07b0-42e4-a3e6-f133ace1860c')]]}}, 'run_id': '74dfdbb9-4c2d-4a08-ad7d-795b5953cae3', 'name': 'ChatHuggingFace', 'tags': [], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'ls_provider': 'huggingface', 'ls_model_type': 'chat'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237', '15247b1a-1cd6-4863-9402-66499f921244']}event: {'event': 'on_chain_stream', 'run_id': '15247b1a-1cd6-4863-9402-66499f921244', 'name': 'chatbot_node', 'tags': ['seq:step:1'], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd'}, 'data': {'chunk': {'messages': [RunLogPatch({'op': 'add','path': '/streamed_output/-','value': AIMessage(content="Hello Máximo! It's nice to meet you. How can I assist you today? Feel free to ask me any questions or let me know if you need help with anything specific.<|im_end|>", additional_kwargs={}, response_metadata={}, id='run-74dfdbb9-4c2d-4a08-ad7d-795b5953cae3-0')},{'op': 'replace','path': '/final_output','value': AIMessage(content="Hello Máximo! It's nice to meet you. How can I assist you today? Feel free to ask me any questions or let me know if you need help with anything specific.<|im_end|>", additional_kwargs={}, response_metadata={}, id='run-74dfdbb9-4c2d-4a08-ad7d-795b5953cae3-0')})]}}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237']}event: {'event': 'on_chain_end', 'data': {'output': {'messages': [RunLogPatch({'op': 'add','path': '/streamed_output/-','value': AIMessage(content="Hello Máximo! It's nice to meet you. How can I assist you today? Feel free to ask me any questions or let me know if you need help with anything specific.<|im_end|>", additional_kwargs={}, response_metadata={}, id='run-74dfdbb9-4c2d-4a08-ad7d-795b5953cae3-0')},{'op': 'replace','path': '/final_output','value': AIMessage(content="Hello Máximo! It's nice to meet you. How can I assist you today? Feel free to ask me any questions or let me know if you need help with anything specific.<|im_end|>", additional_kwargs={}, response_metadata={}, id='run-74dfdbb9-4c2d-4a08-ad7d-795b5953cae3-0')})]}, 'input': {'messages': [HumanMessage(content="hi! I'm Máximo", additional_kwargs={}, response_metadata={}, id='6469501c-07b0-42e4-a3e6-f133ace1860c')]}}, 'run_id': '15247b1a-1cd6-4863-9402-66499f921244', 'name': 'chatbot_node', 'tags': ['seq:step:1'], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd', 'checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34', '638828c0-4add-4141-b6b6-484446100237']}event: {'event': 'on_chain_stream', 'run_id': '638828c0-4add-4141-b6b6-484446100237', 'name': 'chatbot_node', 'tags': ['graph:step:1'], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd'}, 'data': {'chunk': {'messages': [RunLogPatch({'op': 'add','path': '/streamed_output/-','value': AIMessage(content="Hello Máximo! It's nice to meet you. How can I assist you today? Feel free to ask me any questions or let me know if you need help with anything specific.<|im_end|>", additional_kwargs={}, response_metadata={}, id='run-74dfdbb9-4c2d-4a08-ad7d-795b5953cae3-0')},{'op': 'replace','path': '/final_output','value': AIMessage(content="Hello Máximo! It's nice to meet you. How can I assist you today? Feel free to ask me any questions or let me know if you need help with anything specific.<|im_end|>", additional_kwargs={}, response_metadata={}, id='run-74dfdbb9-4c2d-4a08-ad7d-795b5953cae3-0')})]}}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34']}event: {'event': 'on_chain_end', 'data': {'output': {'messages': [RunLogPatch({'op': 'add','path': '/streamed_output/-','value': AIMessage(content="Hello Máximo! It's nice to meet you. How can I assist you today? Feel free to ask me any questions or let me know if you need help with anything specific.<|im_end|>", additional_kwargs={}, response_metadata={}, id='run-74dfdbb9-4c2d-4a08-ad7d-795b5953cae3-0')},{'op': 'replace','path': '/final_output','value': AIMessage(content="Hello Máximo! It's nice to meet you. How can I assist you today? Feel free to ask me any questions or let me know if you need help with anything specific.<|im_end|>", additional_kwargs={}, response_metadata={}, id='run-74dfdbb9-4c2d-4a08-ad7d-795b5953cae3-0')})]}, 'input': {'messages': [HumanMessage(content="hi! I'm Máximo", additional_kwargs={}, response_metadata={}, id='6469501c-07b0-42e4-a3e6-f133ace1860c')]}}, 'run_id': '638828c0-4add-4141-b6b6-484446100237', 'name': 'chatbot_node', 'tags': ['graph:step:1'], 'metadata': {'langgraph_step': 1, 'langgraph_node': 'chatbot_node', 'langgraph_triggers': ('branch:to:chatbot_node',), 'langgraph_path': ('__pregel_pull', 'chatbot_node'), 'langgraph_checkpoint_ns': 'chatbot_node:b7599990-0c1a-4133-fb2c-f32105784fbd'}, 'parent_ids': ['c9c40a00-157a-4229-a0d1-fda00e7bfd34']}Error: Unsupported message type: <class 'langchain_core.tracers.log_stream.RunLogPatch'>For troubleshooting, visit: https://python.langchain.com/docs/troubleshooting/errors/MESSAGE_COERCION_FAILURE
Como se pode ver, os tokens chegam com o evento on_chat_model_stream, então vamos capturá-lo e imprimi-lo.
InputPythontry:async for event in graph.astream_events({"messages": [HumanMessage(content="hi! I'm Máximo")]}, version="v2"):if event["event"] == "on_chat_model_stream":print(event["data"]["chunk"].content, end=" | ", flush=True)except Exception as e:passCopied
/Users/macm1/miniforge3/envs/langgraph/lib/python3.13/site-packages/huggingface_hub/inference/_generated/_async_client.py:2308: FutureWarning: `stop_sequences` is a deprecated argument for `text_generation` task and will be removed in version '0.28.0'. Use `stop` instead.warnings.warn(
Hello | Má | ximo | ! | It | 's | nice | to | meet | you | . | How | can | I | assist | you | today | ? | Feel | free | to | ask | me | any | questions | or | let | me | know | if | you | need | help | with | anything | specific | . | <|im_end|> |
Subgrafias
Antes vimos como bifurcar um grafo de forma que sejam executados nós em paralelo, mas suponhamos o caso de que agora o que queremos é que o que seja executado em paralelo sejam subgrafos. Então vamos ver como fazê-lo
Vamos ver como fazer um grafo de gerenciamento de logs que terá um subgrafo de resumo de logs e outro subgrafo de análise de erros nos logs.

Então, o que vamos fazer é primeiro definir cada um dos subgrafos separadamente e depois adicioná-los ao grafo principal.
Subgrafo de análise de erros em logs
Importamos as bibliotecas necessárias
InputPythonfrom IPython.display import Image, displayfrom langgraph.graph import StateGraph, START, ENDfrom operator import addfrom typing_extensions import TypedDictfrom typing import List, Optional, AnnotatedCopied
Criamos uma classe com a estrutura dos logs
InputPython# The structure of the logsclass Log(TypedDict):id: strquestion: strdocs: Optional[List]answer: strgrade: Optional[int]grader: Optional[str]feedback: Optional[str]Copied
Criamos agora duas classes, uma com a estrutura dos erros dos logs e outra com a análise que reportará na saída
InputPython# Failure Analysis Sub-graphclass FailureAnalysisState(TypedDict):cleaned_logs: List[Log]failures: List[Log]fa_summary: strprocessed_logs: List[str]class FailureAnalysisOutputState(TypedDict):fa_summary: strprocessed_logs: List[str]Copied
Criamos agora as funções dos nós, uma obterá as falhas nos logs, para isso buscará os logs que tenham algum valor no campo grade. Outra gerará um resumo das falhas. Além disso, vamos colocar prints para poder ver o que está acontecendo internamente.
InputPythondef get_failures(state):""" Get logs that contain a failure """cleaned_logs = state["cleaned_logs"]print(f" debug get_failures: cleaned_logs: {cleaned_logs}")failures = [log for log in cleaned_logs if "grade" in log]print(f" debug get_failures: failures: {failures}")return {"failures": failures}def generate_summary(state):""" Generate summary of failures """failures = state["failures"]print(f" debug generate_summary: failures: {failures}")fa_summary = "Poor quality retrieval of documentation."print(f" debug generate_summary: fa_summary: {fa_summary}")processed_logs = [f"failure-analysis-on-log-{failure['id']}" for failure in failures]print(f" debug generate_summary: processed_logs: {processed_logs}")return {"fa_summary": fa_summary, "processed_logs": processed_logs}Copied
Por fim, criamos o grafo, adicionamos os nós e as edges e o compilamos
InputPythonfa_builder = StateGraph(FailureAnalysisState,output=FailureAnalysisOutputState)fa_builder.add_node("get_failures", get_failures)fa_builder.add_node("generate_summary", generate_summary)fa_builder.add_edge(START, "get_failures")fa_builder.add_edge("get_failures", "generate_summary")fa_builder.add_edge("generate_summary", END)graph = fa_builder.compile()display(Image(graph.get_graph().draw_mermaid_png()))Copied
<IPython.core.display.Image object>
Vamos criar um log de teste
InputPythonfailure_log = {"id": "1","question": "What is the meaning of life?","docs": None,"answer": "42","grade": 1,"grader": "AI","feedback": "Good job!"}Copied
Executamos o grafo com o log de teste. Como a função get_failures pega a chave cleaned_logs do estado, temos que passar o log ao grafo nessa mesma chave.
InputPythongraph.invoke({"cleaned_logs": [failure_log]})Copied
debug get_failures: cleaned_logs: [{'id': '1', 'question': 'What is the meaning of life?', 'docs': None, 'answer': '42', 'grade': 1, 'grader': 'AI', 'feedback': 'Good job!'}]debug get_failures: failures: [{'id': '1', 'question': 'What is the meaning of life?', 'docs': None, 'answer': '42', 'grade': 1, 'grader': 'AI', 'feedback': 'Good job!'}]debug generate_summary: failures: [{'id': '1', 'question': 'What is the meaning of life?', 'docs': None, 'answer': '42', 'grade': 1, 'grader': 'AI', 'feedback': 'Good job!'}]debug generate_summary: fa_summary: Poor quality retrieval of documentation.debug generate_summary: processed_logs: ['failure-analysis-on-log-1']
{'fa_summary': 'Poor quality retrieval of documentation.','processed_logs': ['failure-analysis-on-log-1']}
Pode-se ver que ele encontrou o log de teste, já que tem um valor de 1 no campo grade e, em seguida, gerou um resumo das falhas.
Vamos definir todo o subgrafo novamente para que fique mais claro e também para remover os prints que colocamos para debug.
InputPythonfrom IPython.display import Image, displayfrom langgraph.graph import StateGraph, START, ENDfrom operator import addfrom typing_extensions import TypedDictfrom typing import List, Optional, Annotated# The structure of the logsclass Log(TypedDict):id: strquestion: strdocs: Optional[List]answer: strgrade: Optional[int]grader: Optional[str]feedback: Optional[str]# Failure clasesclass FailureAnalysisState(TypedDict):cleaned_logs: List[Log]failures: List[Log]fa_summary: strprocessed_logs: List[str]class FailureAnalysisOutputState(TypedDict):fa_summary: strprocessed_logs: List[str]# Functionsdef get_failures(state):""" Get logs that contain a failure """cleaned_logs = state["cleaned_logs"]failures = [log for log in cleaned_logs if "grade" in log]return {"failures": failures}def generate_summary(state):""" Generate summary of failures """failures = state["failures"]fa_summary = "Poor quality retrieval of documentation."processed_logs = [f"failure-analysis-on-log-{failure['id']}" for failure in failures]return {"fa_summary": fa_summary, "processed_logs": processed_logs}# Build the graphfa_builder = StateGraph(FailureAnalysisState,output=FailureAnalysisOutputState)fa_builder.add_node("get_failures", get_failures)fa_builder.add_node("generate_summary", generate_summary)fa_builder.add_edge(START, "get_failures")fa_builder.add_edge("get_failures", "generate_summary")fa_builder.add_edge("generate_summary", END)graph = fa_builder.compile()display(Image(graph.get_graph().draw_mermaid_png()))Copied
<IPython.core.display.Image object>
Se agora o executarmos novamente, obteremos o mesmo resultado, mas sem os prints.
InputPythongraph.invoke({"cleaned_logs": [failure_log]})Copied
{'fa_summary': 'Poor quality retrieval of documentation.','processed_logs': ['failure-analysis-on-log-1']}
Subgrafo de resumo de logs
Agora criamos o subgrafo de resumo de logs. Neste caso, não é necessário recriar a classe com a estrutura dos logs, então criamos as classes com a estrutura para os resumos dos logs e com a estrutura da saída.
InputPython# Summarization subgraphclass QuestionSummarizationState(TypedDict):cleaned_logs: List[Log]qs_summary: strreport: strprocessed_logs: List[str]class QuestionSummarizationOutputState(TypedDict):report: strprocessed_logs: List[str]Copied
Agora definimos as funções dos nós, uma gerará o resumo dos logs e a outra "enviará o resumo para o Slack".
InputPythondef generate_summary(state):cleaned_logs = state["cleaned_logs"]print(f" debug generate_summary: cleaned_logs: {cleaned_logs}")summary = "Questions focused on ..."print(f" debug generate_summary: summary: {summary}")processed_logs = [f"summary-on-log-{log['id']}" for log in cleaned_logs]print(f" debug generate_summary: processed_logs: {processed_logs}")return {"qs_summary": summary, "processed_logs": processed_logs}def send_to_slack(state):qs_summary = state["qs_summary"]print(f" debug send_to_slack: qs_summary: {qs_summary}")report = "foo bar baz"print(f" debug send_to_slack: report: {report}")return {"report": report}Copied
Por fim, criamos o grafo, adicionamos os nós e as edges e o compilamos.
InputPython# Build the graphqs_builder = StateGraph(QuestionSummarizationState,output=QuestionSummarizationOutputState)qs_builder.add_node("generate_summary", generate_summary)qs_builder.add_node("send_to_slack", send_to_slack)qs_builder.add_edge(START, "generate_summary")qs_builder.add_edge("generate_summary", "send_to_slack")qs_builder.add_edge("send_to_slack", END)graph = qs_builder.compile()display(Image(graph.get_graph().draw_mermaid_png()))Copied
<IPython.core.display.Image object>
Voltamos a testar com o log que criamos antes.
InputPythongraph.invoke({"cleaned_logs": [failure_log]})Copied
debug generate_summary: cleaned_logs: [{'id': '1', 'question': 'What is the meaning of life?', 'docs': None, 'answer': '42', 'grade': 1, 'grader': 'AI', 'feedback': 'Good job!'}]debug generate_summary: summary: Questions focused on ...debug generate_summary: processed_logs: ['summary-on-log-1']debug send_to_slack: qs_summary: Questions focused on ...debug send_to_slack: report: foo bar baz
{'report': 'foo bar baz', 'processed_logs': ['summary-on-log-1']}
Voltamos a escrever o subgrafo, tudo junto para ver com mais clareza e sem os prints.
InputPython# Summarization clasesclass QuestionSummarizationState(TypedDict):cleaned_logs: List[Log]qs_summary: strreport: strprocessed_logs: List[str]class QuestionSummarizationOutputState(TypedDict):report: strprocessed_logs: List[str]# Functionsdef generate_summary(state):cleaned_logs = state["cleaned_logs"]summary = "Questions focused on ..."processed_logs = [f"summary-on-log-{log['id']}" for log in cleaned_logs]return {"qs_summary": summary, "processed_logs": processed_logs}def send_to_slack(state):qs_summary = state["qs_summary"]report = "foo bar baz"return {"report": report}# Build the graphqs_builder = StateGraph(QuestionSummarizationState,output=QuestionSummarizationOutputState)qs_builder.add_node("generate_summary", generate_summary)qs_builder.add_node("send_to_slack", send_to_slack)qs_builder.add_edge(START, "generate_summary")qs_builder.add_edge("generate_summary", "send_to_slack")qs_builder.add_edge("send_to_slack", END)graph = qs_builder.compile()display(Image(graph.get_graph().draw_mermaid_png()))Copied
<IPython.core.display.Image object>
Voltamos a executar o grafo com o log de teste.
InputPythongraph.invoke({"cleaned_logs": [failure_log]})Copied
{'report': 'foo bar baz', 'processed_logs': ['summary-on-log-1']}
Grafo principal
Agora que temos os dois subgrafos, podemos criar o grafo principal que os usará. Para isso, criamos a classe EntryGraphState, que terá o estado dos dois subgrafos.
InputPython# Entry Graphclass EntryGraphState(TypedDict):raw_logs: List[Log]cleaned_logs: List[Log]fa_summary: str # This will only be generated in the FA sub-graphreport: str # This will only be generated in the QS sub-graphprocessed_logs: Annotated[List[int], add] # This will be generated in BOTH sub-graphsCopied
Criamos uma função de limpeza de logs, que será um nó que será executado antes dos dois subgrafos e que lhes fornecerá os logs limpos, através da key cleaned_logs, que é a que os dois subgrafos obtêm do estado.
InputPythondef clean_logs(state):# Get logsraw_logs = state["raw_logs"]# Data cleaning raw_logs -> docscleaned_logs = raw_logsreturn {"cleaned_logs": cleaned_logs}Copied
Agora criamos o grafo principal
InputPython# Build the graphentry_builder = StateGraph(EntryGraphState)Copied
Adicionamos os nós. Para adicionar um subgrafo como nó, o que fazemos é adicionar sua compilação
InputPython# Add nodesentry_builder.add_node("clean_logs", clean_logs)entry_builder.add_node("question_summarization", qs_builder.compile())entry_builder.add_node("failure_analysis", fa_builder.compile())Copied
<langgraph.graph.state.StateGraph at 0x107985ef0>
A partir daqui, é como se sempre, adicionássemos os edges e o compilássemos.
InputPython# Add edgesentry_builder.add_edge(START, "clean_logs")entry_builder.add_edge("clean_logs", "failure_analysis")entry_builder.add_edge("clean_logs", "question_summarization")entry_builder.add_edge("failure_analysis", END)entry_builder.add_edge("question_summarization", END)# Compile the graphgraph = entry_builder.compile()Copied
Adding an edge to a graph that has already been compiled. This will not be reflected in the compiled graph.Adding an edge to a graph that has already been compiled. This will not be reflected in the compiled graph.Adding an edge to a graph that has already been compiled. This will not be reflected in the compiled graph.Adding an edge to a graph that has already been compiled. This will not be reflected in the compiled graph.Adding an edge to a graph that has already been compiled. This will not be reflected in the compiled graph.
Por fim, mostramos o grafo. Adicionamos xray=1 para que o estado interno do grafo seja visível.
InputPython# Setting xray to 1 will show the internal structure of the nested graphdisplay(Image(graph.get_graph(xray=1).draw_mermaid_png()))Copied
<IPython.core.display.Image object>
Se não tivéssemos adicionado xray=1, o grafo ficaria assim
InputPythondisplay(Image(graph.get_graph().draw_mermaid_png()))Copied
<IPython.core.display.Image object>
Agora criamos dois logs de teste, em um haverá um erro (um valor em grade) e no outro não.
InputPython# Dummy logsquestion_answer = Log(id="1",question="How can I import ChatOllama?",answer="To import ChatOllama, use: 'from langchain_community.chat_models import ChatOllama.'",)question_answer_feedback = Log(id="2",question="How can I use Chroma vector store?",answer="To use Chroma, define: rag_chain = create_retrieval_chain(retriever, question_answer_chain).",grade=0,grader="Document Relevance Recall",feedback="The retrieved documents discuss vector stores in general, but not Chroma specifically",)raw_logs = [question_answer,question_answer_feedback]Copied
Passamos para o grafo principal
InputPythongraph.invoke({"raw_logs": raw_logs})Copied
{'raw_logs': [{'id': '1','question': 'How can I import ChatOllama?','answer': "To import ChatOllama, use: 'from langchain_community.chat_models import ChatOllama.'"},{'id': '2','question': 'How can I use Chroma vector store?','answer': 'To use Chroma, define: rag_chain = create_retrieval_chain(retriever, question_answer_chain).','grade': 0,'grader': 'Document Relevance Recall','feedback': 'The retrieved documents discuss vector stores in general, but not Chroma specifically'}],'cleaned_logs': [{'id': '1','question': 'How can I import ChatOllama?','answer': "To import ChatOllama, use: 'from langchain_community.chat_models import ChatOllama.'"},{'id': '2','question': 'How can I use Chroma vector store?','answer': 'To use Chroma, define: rag_chain = create_retrieval_chain(retriever, question_answer_chain).','grade': 0,'grader': 'Document Relevance Recall','feedback': 'The retrieved documents discuss vector stores in general, but not Chroma specifically'}],'fa_summary': 'Poor quality retrieval of documentation.','report': 'foo bar baz','processed_logs': ['failure-analysis-on-log-2','summary-on-log-1','summary-on-log-2']}
Assim como antes, escrevemos todo o grafo para vê-lo com mais clareza
InputPython# Entry Graphclass EntryGraphState(TypedDict):raw_logs: List[Log]cleaned_logs: List[Log]fa_summary: str # This will only be generated in the FA sub-graphreport: str # This will only be generated in the QS sub-graphprocessed_logs: Annotated[List[int], add] # This will be generated in BOTH sub-graphs# Functionsdef clean_logs(state):# Get logsraw_logs = state["raw_logs"]# Data cleaning raw_logs -> docscleaned_logs = raw_logsreturn {"cleaned_logs": cleaned_logs}# Build the graphentry_builder = StateGraph(EntryGraphState)# Add nodesentry_builder.add_node("clean_logs", clean_logs)entry_builder.add_node("question_summarization", qs_builder.compile())entry_builder.add_node("failure_analysis", fa_builder.compile())# Add edgesentry_builder.add_edge(START, "clean_logs")entry_builder.add_edge("clean_logs", "failure_analysis")entry_builder.add_edge("clean_logs", "question_summarization")entry_builder.add_edge("failure_analysis", END)entry_builder.add_edge("question_summarization", END)# Compile the graphgraph = entry_builder.compile()# Setting xray to 1 will show the internal structure of the nested graphdisplay(Image(graph.get_graph(xray=1).draw_mermaid_png()))Copied
<IPython.core.display.Image object>
Passamos os logs de teste para o grafo principal
InputPythongraph.invoke({"raw_logs": raw_logs})Copied
{'raw_logs': [{'id': '1','question': 'How can I import ChatOllama?','answer': "To import ChatOllama, use: 'from langchain_community.chat_models import ChatOllama.'"},{'id': '2','question': 'How can I use Chroma vector store?','answer': 'To use Chroma, define: rag_chain = create_retrieval_chain(retriever, question_answer_chain).','grade': 0,'grader': 'Document Relevance Recall','feedback': 'The retrieved documents discuss vector stores in general, but not Chroma specifically'}],'cleaned_logs': [{'id': '1','question': 'How can I import ChatOllama?','answer': "To import ChatOllama, use: 'from langchain_community.chat_models import ChatOllama.'"},{'id': '2','question': 'How can I use Chroma vector store?','answer': 'To use Chroma, define: rag_chain = create_retrieval_chain(retriever, question_answer_chain).','grade': 0,'grader': 'Document Relevance Recall','feedback': 'The retrieved documents discuss vector stores in general, but not Chroma specifically'}],'fa_summary': 'Poor quality retrieval of documentation.','report': 'foo bar baz','processed_logs': ['failure-analysis-on-log-2','summary-on-log-1','summary-on-log-2']}
Ramos dinâmicos
Até agora, criamos nós e edges estáticos, mas há vezes em que não sabemos se vamos precisar de um ramo até que o grafo seja executado. Para isso, podemos usar o método SEND do LangGraph, que permite criar ramos dinamicamente.
Para vê-lo, vamos criar um grafo que gere piadas sobre alguns temas, mas como não sabemos de antemão sobre quantos temas queremos gerar piadas, por meio do método SEND vamos criar ramificações dinamicamente, de modo que, se ainda houver temas a serem gerados, será criada uma nova ramificação.
Nota: Esta seção será feita usando Sonnet 3.7, já que a integração do HuggingFace não tem a funcionalidade de
with_structured_output, que fornece uma saída estruturada com uma estrutura definida.
Primeiro importamos as bibliotecas necessárias.
InputPythonimport operatorfrom typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import END, StateGraph, STARTfrom langchain_anthropic import ChatAnthropicimport osos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracingimport dotenvdotenv.load_dotenv()ANTHROPIC_TOKEN = os.getenv("ANTHROPIC_LANGGRAPH_API_KEY")from IPython.display import ImageCopied
Criamos as classes com a estrutura do estado.
InputPythonclass OverallState(TypedDict):topic: strsubjects: listjokes: Annotated[list, operator.add]best_selected_joke: strclass JokeState(TypedDict):subject: strCopied
Criamos o LLM
InputPython# Create the LLM modelllm = ChatAnthropic(model="claude-3-7-sonnet-20250219", api_key=ANTHROPIC_TOKEN)Copied
Criamos a função que gerará os temas.
Vamos a usar with_structured_output para que o LLM gere uma saída com uma estrutura definida por nós; essa estrutura vamos definir com a classe Subjects, que é uma classe do tipo BaseModel do Pydantic.
InputPythonfrom pydantic import BaseModelclass Subjects(BaseModel):subjects: list[str]subjects_prompt = """Generate a list of 3 sub-topics that are all related to this overall topic: {topic}."""def generate_topics(state: OverallState):prompt = subjects_prompt.format(topic=state["topic"])response = llm.with_structured_output(Subjects).invoke(prompt)return {"subjects": response.subjects}Copied
Agora definimos a função que gerará as piadas.
InputPythonclass Joke(BaseModel):joke: strjoke_prompt = """Generate a joke about {subject}"""def generate_joke(state: JokeState):prompt = joke_prompt.format(subject=state["subject"])response = llm.with_structured_output(Joke).invoke(prompt)return {"jokes": [response.joke]}Copied
E, por último, a função que selecionará a melhor piada.
InputPythonclass BestJoke(BaseModel):id: intbest_joke_prompt = """Below are a bunch of jokes about {topic}. Select the best one! Return the ID of the best one, starting 0 as the ID for the first joke. Jokes: {jokes}"""def best_joke(state: OverallState):jokes = " ".join(state["jokes"])prompt = best_joke_prompt.format(topic=state["topic"], jokes=jokes)response = llm.with_structured_output(BestJoke).invoke(prompt)return {"best_selected_joke": state["jokes"][response.id]}Copied
Agora vamos criar uma função que decida se deve criar um novo ramo com SEND ou não, e para decidir isso verificará se ainda restam tópicos por gerar.
InputPythonfrom langgraph.constants import Senddef continue_to_jokes(state: OverallState):return [Send("generate_joke", {"subject": s}) for s in state["subjects"]]Copied
Construímos o grafo, adicionamos os nós e os edges.
InputPython# Build the graphgraph = StateGraph(OverallState)# Add nodesgraph.add_node("generate_topics", generate_topics)graph.add_node("generate_joke", generate_joke)graph.add_node("best_joke", best_joke)# Add edgesgraph.add_edge(START, "generate_topics")graph.add_conditional_edges("generate_topics", continue_to_jokes, ["generate_joke"])graph.add_edge("generate_joke", "best_joke")graph.add_edge("best_joke", END)# Compile the graphapp = graph.compile()# Display the graphImage(app.get_graph().draw_mermaid_png())Copied
<IPython.core.display.Image object>
Como se pode ver, a edge entre generate_topics e generate_joke é representada com uma linha tracejada, o que indica que é um ramo dinâmico.
Criamos agora um dicionário com a chave topic, que é a que o nó generate_topics precisa para gerar os temas, e o passamos ao grafo.
InputPython# Call the graph: here we call it to generate a list of jokesfor state in app.stream({"topic": "animals"}):print(state)Copied
{'generate_topics': {'subjects': ['Marine Animals', 'Endangered Species', 'Animal Behavior']}}{'generate_joke': {'jokes': ["Why don't cats play poker in the wild? Too many cheetahs!"]}}{'generate_joke': {'jokes': ["Why don't sharks eat clownfish? Because they taste funny!"]}}{'generate_joke': {'jokes': ["Why don't endangered species tell jokes? Because they're afraid of dying out from laughter!"]}}{'best_joke': {'best_selected_joke': "Why don't cats play poker in the wild? Too many cheetahs!"}}
Vamos recriar o grafo com todo o código junto para maior clareza.
InputPythonimport operatorfrom typing import Annotatedfrom typing_extensions import TypedDictfrom pydantic import BaseModelfrom langgraph.graph import END, StateGraph, STARTfrom langgraph.constants import Sendfrom langchain_anthropic import ChatAnthropicimport osos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracingimport dotenvdotenv.load_dotenv()ANTHROPIC_TOKEN = os.getenv("ANTHROPIC_LANGGRAPH_API_KEY")from IPython.display import Image# Prompts we will usesubjects_prompt = """Generate a list of 3 sub-topics that are all related to this overall topic: {topic}."""joke_prompt = """Generate a joke about {subject}"""best_joke_prompt = """Below are a bunch of jokes about {topic}. Select the best one! Return the ID of the best one, starting 0 as the ID for the first joke. Jokes: {jokes}"""# Create the LLM modelllm = ChatAnthropic(model="claude-3-7-sonnet-20250219", api_key=ANTHROPIC_TOKEN)class Subjects(BaseModel):subjects: list[str]class BestJoke(BaseModel):id: intclass OverallState(TypedDict):topic: strsubjects: listjokes: Annotated[list, operator.add]best_selected_joke: strclass JokeState(TypedDict):subject: strclass Joke(BaseModel):joke: strdef generate_topics(state: OverallState):prompt = subjects_prompt.format(topic=state["topic"])response = llm.with_structured_output(Subjects).invoke(prompt)return {"subjects": response.subjects}def continue_to_jokes(state: OverallState):return [Send("generate_joke", {"subject": s}) for s in state["subjects"]]def generate_joke(state: JokeState):prompt = joke_prompt.format(subject=state["subject"])response = llm.with_structured_output(Joke).invoke(prompt)return {"jokes": [response.joke]}def best_joke(state: OverallState):jokes = " ".join(state["jokes"])prompt = best_joke_prompt.format(topic=state["topic"], jokes=jokes)response = llm.with_structured_output(BestJoke).invoke(prompt)return {"best_selected_joke": state["jokes"][response.id]}# Build the graphgraph = StateGraph(OverallState)# Add nodesgraph.add_node("generate_topics", generate_topics)graph.add_node("generate_joke", generate_joke)graph.add_node("best_joke", best_joke)# Add edgesgraph.add_edge(START, "generate_topics")graph.add_conditional_edges("generate_topics", continue_to_jokes, ["generate_joke"])graph.add_edge("generate_joke", "best_joke")graph.add_edge("best_joke", END)# Compile the graphapp = graph.compile()# Display the graphImage(app.get_graph().draw_mermaid_png())Copied
<IPython.core.display.Image object>
Vamos executá-lo novamente, mas agora, em vez de com animais, vamos fazê-lo com carros
InputPythonfor state in app.stream({"topic": "cars"}):print(state)Copied
{'generate_topics': {'subjects': ['Car Maintenance and Repair', 'Electric and Hybrid Vehicles', 'Automotive Design and Engineering']}}{'generate_joke': {'jokes': ["Why don't electric cars tell jokes? They're afraid of running out of charge before they get to the punchline!"]}}{'generate_joke': {'jokes': ["Why don't automotive engineers play hide and seek? Because good luck hiding when you're always making a big noise about torque!"]}}{'generate_joke': {'jokes': ["Why don't cars ever tell their own jokes? Because they always exhaust themselves during the delivery! Plus, their timing belts are always a little off."]}}{'best_joke': {'best_selected_joke': "Why don't electric cars tell jokes? They're afraid of running out of charge before they get to the punchline!"}}
Melhorar o chatbot com ferramentas
Para lidar com algumas consultas, o nosso chatbot não pode responder a partir do seu conhecimento, por isso vamos integrar uma ferramenta de busca na web. O nosso bot pode utilizar essa ferramenta para encontrar informações relevantes e fornecer melhores respostas.
Requisitos
Antes de começar, temos que instalar o mecanismo de busca Tavily, que é um buscador web que nos permite pesquisar informações na web.
pip install -U tavily-python langchain_communityDepois, temos que criar uma API KEY, escrevemo-la no nosso arquivo .env e carregamo-la numa variável.
InputPythonimport dotenvimport osdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")TAVILY_API_KEY = os.getenv("TAVILY_LANGGRAPH_API_KEY")Copied
Chatbot com tools
Primeiro criamos o estado e o LLM
InputPythonfrom typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom huggingface_hub import loginimport jsonimport osfrom IPython.display import Image, displayos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracingimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")class State(TypedDict):messages: Annotated[list, add_messages]# Create the LLMlogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)Copied
Agora, definimos a ferramenta de busca na web por meio de TavilySearchResults
InputPythonfrom langchain_community.utilities.tavily_search import TavilySearchAPIWrapperfrom langchain_community.tools.tavily_search import TavilySearchResultsTAVILY_API_KEY = os.getenv("TAVILY_LANGGRAPH_API_KEY")wrapper = TavilySearchAPIWrapper(tavily_api_key=TAVILY_API_KEY)tool = TavilySearchResults(api_wrapper=wrapper, max_results=2)Copied
Vamos experimentar a ferramenta, vamos fazer uma pesquisa na Internet
InputPythontool.invoke("What was the result of Real Madrid's at last match in the Champions League?")Copied
Failed to multipart ingest runs: langsmith.utils.LangSmithError: Failed to POST https://eu.api.smith.langchain.com/runs/multipart in LangSmith API. HTTPError('403 Client Error: Forbidden for url: https://eu.api.smith.langchain.com/runs/multipart', '{"error":"Forbidden"} ')
[{'title': 'HIGHLIGHTS | Real Madrid 3-2 Leganés | LaLiga 2024/25 - YouTube','url': 'https://www.youtube.com/watch?v=Np-Kwz4RDpY','content': "20:14 · Go to channel · RONALDO'S LAST MATCH WITH REAL MADRID: THE MOST THRILLING FINAL EVER! ... Champions League 1/4 Final | PES. Football",'score': 0.65835214},{'title': 'Real Madrid | History | UEFA Champions League','url': 'https://www.uefa.com/uefachampionsleague/history/clubs/50051--real-madrid/','content': '1955/56 P W D L Final 7 5 0 2 UEFA Champions League [...] 2010/11 P W D L Semi-finals 12 8 3 1 2009/10 P W D L Round of 16 8 4 2 2 2000s 2008/09 P W D L Round of 16 8 4 0 4 2007/08 P W D L Round of 16 8 3 2 3 2006/07 P W D L Round of 16 8 4 2 2 2005/06 P W D L Round of 16 8 3 2 3 2004/05 P W D L Round of 16 10 6 2 2 2003/04 P W D L Quarter-finals 10 6 3 1 2002/03 P W D L Semi-finals 16 7 5 4 2001/02 P W D L Final 17 12 3 2 2000/01 P W D L Semi-finals 16 9 2 5 1990s 1999/00 P W D L Final 17 10 3 4 1998/99 P W D L Quarter-finals 8 4 1 3 [...] 1969/70 P W D L Second round 4 2 0 2 1968/69 P W D L Second round 4 3 0 1 1967/68 P W D L Semi-finals 8 2 4 2 1966/67 P W D L Quarter-finals 4 1 0 3 1965/66 P W D L Final 9 5 2 2 1964/65 P W D L Quarter-finals 6 4 1 1 1963/64 P W D L Final 9 7 0 2 1962/63 P W D L Preliminary round 2 0 1 1 1961/62 P W D L Final 10 8 0 2 1960/61 P W D L First round 2 0 1 1 1950s 1959/60 P W D L Final 7 6 0 1 1958/59 P W D L Final 8 5 2 1 1957/58 P W D L Final 7 5 1 1 1956/57 P W D L Final 8 6 1 1','score': 0.6030211}]
Os resultados são resumos de páginas que nosso chatbot pode usar para responder perguntas.
Criamos uma lista de ferramentas, porque nosso grafo precisa definir as ferramentas por meio de uma lista.
InputPythontools_list = [tool]Copied
Agora que temos a lista de tools, criamos um llm_with_tools
InputPython# Modification: tell the LLM which tools it can callllm_with_tools = llm.bind_tools(tools_list)Copied
Definimos a função que irá no nó chatbot
InputPython# Define the chatbot functiondef chatbot_function(state: State):return {"messages": [llm_with_tools.invoke(state["messages"])]}Copied
Precisamos criar uma função para executar as tools_list se forem chamadas. Adicionamos as tools_list a um novo nó.
Mais tarde faremos isso com o método ToolNode de LangGraph, mas primeiro vamos construí-lo nós mesmos para entender como funciona.
Vamos implementar a classe BasicToolNode, que verifica a mensagem mais recente no estado e chama as tools_list se a mensagem contiver tool_calls.
Baseia-se no suporte de tool_calling dos LLMs, que está disponível na Anthropic, HuggingFace, Google Gemini, OpenAI e vários outros fornecedores de LLM.
InputPythonfrom langchain_core.messages import ToolMessageclass BasicToolNode:"""A node that runs the tools requested in the last AIMessage."""def __init__(self, tools: list) -> None:"""Initialize the toolsArgs:tools (list): The tools to useReturns:None"""# Initialize the toolsself.tools_by_name = {tool.name: tool for tool in tools}def __call__(self, inputs: dict):"""Call the nodeArgs:inputs (dict): The inputs to the nodeReturns:dict: The outputs of the node"""# Get the last messageif messages := inputs.get("messages", []):message = messages[-1]else:raise ValueError("No message found in input")# Execute the toolsoutputs = []for tool_call in message.tool_calls:tool_result = self.tools_by_name[tool_call["name"]].invoke(tool_call["args"])outputs.append(ToolMessage(content=json.dumps(tool_result),name=tool_call["name"],tool_call_id=tool_call["id"],))return {"messages": outputs}basic_tool_node = BasicToolNode(tools=tools_list)Copied
Usamos ToolMessage, que passa o resultado de executar uma tool de novo para o LLM.
ToolMessage contém o resultado de uma invocação de uma tool.
Ou seja, assim que temos o resultado de usar uma Tool, passamo-lo ao LLM para que o processe
Com o objeto basic_tool_node (que é um objeto da classe BasicToolNode que criamos) já podemos fazer com que o LLM execute tools
Agora, assim como fizemos quando construímos um chatbot básico, vamos criar o grafo e adicionar nós
InputPython# Create graphgraph_builder = StateGraph(State)# Add the chatbot nodegraph_builder.add_node("chatbot_node", chatbot_function)graph_builder.add_node("tools_node", basic_tool_node)Copied
<langgraph.graph.state.StateGraph at 0x14996cd70>
Quando o LLM receber uma mensagem, como conhece as tools que tem à disposição, decidirá se responde ou usa uma tool. Então vamos criar uma função de roteamento, que executará uma tool se o LLM decidir usá-la, ou então finalizará a execução do grafo
InputPythondef route_tools_function(state: State,):"""Use in the conditional_edge to route to the ToolNode if the last messagehas tool calls. Otherwise, route to the end."""# Get last messageif isinstance(state, list):ai_message = state[-1]elif messages := state.get("messages", []):ai_message = messages[-1]else:raise ValueError(f"No messages found in input state to tool_edge: {state}")# Router in function of last messageif hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:return "tools_node"return ENDCopied
Adicionamos os edges.
Temos que adicionar um edge especial por meio de add_conditional_edges, que criará um nó condicional. Una o nó chatbot_node com a função de roteamento que criamos antes route_tools_function. Com este nó, se obtivermos na saída de route_tools_function a string tools_node, ele roteará o grafo para o nó tools_node; mas, se recebermos END, roteará o grafo para o nó END e encerrará a execução do grafo
Mais tarde, substituiremos isso pelo método pré-construído tools_condition, mas agora o implementamos nós mesmos para ver como funciona.
Por fim, adiciona-se outro edge que une tools_node com chatbot_node, para que, quando uma tool terminar de ser executada, o grafo volte ao nó do LLM
InputPython# Add edgesgraph_builder.add_edge(START, "chatbot_node")graph_builder.add_conditional_edges("chatbot_node",route_tools_function,# The following dictionary lets you tell the graph to interpret the condition's outputs as a specific node# It defaults to the identity function, but if you# want to use a node named something else apart from "tools",# You can update the value of the dictionary to something else# e.g., "tools": "my_tools"{"tools_node": "tools_node", END: END},)graph_builder.add_edge("tools_node", "chatbot_node")Copied
<langgraph.graph.state.StateGraph at 0x14996cd70>
Compilamos o nó e o representamos
InputPythongraph = graph_builder.compile()try:display(Image(graph.get_graph().draw_mermaid_png()))except Exception as e:print(f"Error al visualizar el grafo: {e}")Copied
<IPython.core.display.Image object>
Agora podemos fazer perguntas ao bot fora dos seus dados de treinamento
InputPython# Colors for the terminalCOLOR_GREEN = "\033[32m"COLOR_YELLOW = "\033[33m"COLOR_RESET = "\033[0m"def stream_graph_updates(user_input: str):for event in graph.stream({"messages": [{"role": "user", "content": user_input}]}):for value in event.values():print(f"{COLOR_GREEN}User: {COLOR_RESET}{user_input}")print(f"{COLOR_YELLOW}Assistant: {COLOR_RESET}{value['messages'][-1].content}")while True:try:user_input = input("User: ")if user_input.lower() in ["quit", "exit", "q"]:print(f"{COLOR_GREEN}User: {COLOR_RESET}{user_input}")print(f"{COLOR_YELLOW}Assistant: {COLOR_RESET}Goodbye!")breakstream_graph_updates(user_input)except:# fallback if input() is not availableuser_input = "What do you know about LangGraph?"print("User: " + user_input)stream_graph_updates(user_input)breakCopied
User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{"title": "Real Madrid 3-2 Leganes: Goals and highlights - LaLiga 24/25 | Marca", "url": "https://www.marca.com/en/soccer/laliga/r-madrid-leganes/2025/03/29/01_0101_20250329_186_957-live.html", "content": "While their form has varied throughout the campaign there is no denying Real Madrid are a force at home in LaLiga this season, as they head into Saturday's match having picked up 34 points from 13 matches. As for Leganes they currently sit 18th in the table, though they are level with Alaves for 17th as both teams look to stay in the top flight. [...] The two teams have already played twice this season, with Real Madrid securing a 3-0 win in the reverse league fixture. They also met in the quarter-finals of the Copa del Rey, a game Real won 3-2. Real Madrid vs Leganes LIVE - Latest Updates Match ends, Real Madrid 3, Leganes 2. Second Half ends, Real Madrid 3, Leganes 2. Foul by Vinícius Júnior (Real Madrid). Seydouba Cissé (Leganes) wins a free kick in the defensive half. [...] Goal! Real Madrid 1, Leganes 1. Diego García (Leganes) left footed shot from very close range. Attempt missed. Óscar Rodríguez (Leganes) left footed shot from the centre of the box. Goal! Real Madrid 1, Leganes 0. Kylian Mbappé (Real Madrid) converts the penalty with a right footed shot. Penalty Real Madrid. Arda Güler draws a foul in the penalty area. Penalty conceded by Óscar Rodríguez (Leganes) after a foul in the penalty area. Delay over. They are ready to continue.", "score": 0.8548001}, {"title": "Real Madrid 3-2 Leganés (Mar 29, 2025) Game Analysis - ESPN", "url": "https://www.espn.com/soccer/report/_/gameId/704946", "content": "Real Madrid Leganés Mbappé nets twice to keep Real Madrid's title hopes alive Real Madrid vs. Leganés - Game Highlights Watch the Game Highlights from Real Madrid vs. Leganés, 03/30/2025 Real Madrid's Kylian Mbappé struck twice to help his side come from behind to claim a hard-fought 3-2 home win over relegation-threatened Leganes on Saturday to move the second-placed reigning champions level on points with leaders Barcelona. [...] Leganes pushed for an equaliser but fell to a third consecutive defeat to sit 18th on 27 points, level with Alaves who are one place higher in the safety zone on goal difference. "We have done a tremendous job. We leave with our heads held high because we were fighting until the end to score here," Leganes striker Garcia said. "Ultimately, it was down to the details that they took it. We played a very serious game and now we have to think about next week." Game Information", "score": 0.82220376}]User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{"title": "Real Madrid vs Leganes 3-2 | Highlights & All Goals - YouTube", "url": "https://www.youtube.com/watch?v=ngBWsjmeHEk", "content": "Real Madrid secured a dramatic 3-2 victory over Leganes in an intense La Liga showdown on 29 March 2025! ⚽ Watch all the goals and", "score": 0.5157425}, {"title": "Real Madrid 3-2 Leganés (Mar 29, 2025) Game Analysis - ESPN", "url": "https://www.espn.com/soccer/report/_/gameId/704946", "content": ""We know what we always have to do: win. We started well, in the opposition half, and we scored a goal. Then we didn't play well for 20 minutes and conceded two goals," said Mbappé. "But we know that if we play well we'll score and in the second half we scored two goals. We won the game and we're very happy. "We worked on [the set piece] a few weeks ago with the staff. I knew I could shoot this way, I saw the space. I asked the others to let me shoot and it worked out well." [...] Leganes pushed for an equaliser but fell to a third consecutive defeat to sit 18th on 27 points, level with Alaves who are one place higher in the safety zone on goal difference. "We have done a tremendous job. We leave with our heads held high because we were fighting until the end to score here," Leganes striker Garcia said. "Ultimately, it was down to the details that they took it. We played a very serious game and now we have to think about next week." Game Information [...] However, Leganes responded almost immediately as Diego Garcia tapped in a loose ball at the far post to equalise in the following minute before Rodriguez set up Dani Raba to slot past goalkeeper Andriy Lunin in the 41st. Real midfielder Jude Bellingham brought the scores level two minutes after the break, sliding the ball into the net after a rebound off the crossbar. Mbappé then bagged the winner with a brilliant curled free kick in the 76th minute for his second.", "score": 0.50944775}]User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{"title": "Real Madrid 3-2 Leganés (Mar 29, 2025) Game Analysis - ESPN", "url": "https://www.espn.com/soccer/report/_/gameId/704946", "content": "Real Madrid Leganés Mbappé nets twice to keep Real Madrid's title hopes alive Real Madrid vs. Leganés - Game Highlights Watch the Game Highlights from Real Madrid vs. Leganés, 03/30/2025 Real Madrid's Kylian Mbappé struck twice to help his side come from behind to claim a hard-fought 3-2 home win over relegation-threatened Leganes on Saturday to move the second-placed reigning champions level on points with leaders Barcelona. [...] Leganes pushed for an equaliser but fell to a third consecutive defeat to sit 18th on 27 points, level with Alaves who are one place higher in the safety zone on goal difference. "We have done a tremendous job. We leave with our heads held high because we were fighting until the end to score here," Leganes striker Garcia said. "Ultimately, it was down to the details that they took it. We played a very serious game and now we have to think about next week." Game Information [...] However, Leganes responded almost immediately as Diego Garcia tapped in a loose ball at the far post to equalise in the following minute before Rodriguez set up Dani Raba to slot past goalkeeper Andriy Lunin in the 41st. Real midfielder Jude Bellingham brought the scores level two minutes after the break, sliding the ball into the net after a rebound off the crossbar. Mbappé then bagged the winner with a brilliant curled free kick in the 76th minute for his second.", "score": 0.93666285}, {"title": "MBAPPE BRACE Leganes vs. Real Madrid - ESPN FC - YouTube", "url": "https://www.youtube.com/watch?v=0xwUhzx19_4", "content": "MBAPPE BRACE 🔥 Leganes vs. Real Madrid | LALIGA Highlights | ESPN FC ESPN FC 6836 likes 550646 views 29 Mar 2025 Watch these highlights as Kylian Mbappe scores 2 goals to give Real Madrid the 3-2 victory over Leganes in their LALIGA matchup. ✔ Subscribe to ESPN+: http://espnplus.com/soccer/youtube ✔ Subscribe to ESPN FC on YouTube: http://bit.ly/SUBSCRIBEtoESPNFC 790 comments", "score": 0.92857105}]User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{"title": "(VIDEO) All Goals from Real Madrid vs Leganes in La Liga", "url": "https://www.beinsports.com/en-us/soccer/la-liga/articles-video/-video-all-goals-from-real-madrid-vs-leganes-in-la-liga-2025-03-29?ess=", "content": "Real Madrid will host CD Leganes this Saturday, March 29, 2025, at the Santiago Bernabéu in a Matchday 29 clash of LaLiga EA Sports.", "score": 0.95628047}, {"title": "Real Madrid v Leganes | March 29, 2025 | Goal.com US", "url": "https://www.goal.com/en-us/match/real-madrid-vs-leganes/sZTw_SnjyKCcntxKHHQI7", "content": "Latest news, stats and live commentary for the LaLiga's meeting between Real Madrid v Leganes on the March 29, 2025.", "score": 0.9522955}]User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: Real Madrid faced Leganes in La Liga this weekend and came away with a 3-2 victory at the Santiago Bernabéu. The match was intense, with Kylian Mbappé scoring twice for Real Madrid, including a curled free kick in the 76th minute that proved to be the winner. Leganes managed to take the lead briefly with goals from Diego García and Dani Raba, but Real Madrid leveled through Jude Bellingham before Mbappé's second goal secured the win. This result keeps Real Madrid's title hopes alive, moving them level on points with leaders Barcelona.User: Which players played the match?Assistant: The question is too vague and doesn't provide context such as the sport, league, or specific match in question. Could you please provide more details?User: qAssistant: Goodbye!
Como você vê, primeiro perguntei como o Real Madrid ficou em sua última partida na Liga contra o Leganés
, como é algo atual, decidiu usar a ferramenta de busca, com o que obteve o resultado
No entanto, a seguir perguntei-lhe que jogadores jogaram e ele não sabia do que eu estava a falar, isso é porque o contexto da conversa não é mantido. Então, o que vamos fazer a seguir é adicionar uma memória ao agente para que ele possa manter o contexto da conversa.
Vamos escrever tudo junto para que fique mais legível
InputPythonfrom typing import Annotatedfrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_huggingface import HuggingFaceEndpoint, ChatHuggingFacefrom huggingface_hub import loginfrom langchain_community.utilities.tavily_search import TavilySearchAPIWrapperfrom langchain_community.tools.tavily_search import TavilySearchResultsfrom langchain_core.messages import ToolMessagefrom IPython.display import Image, displayimport jsonimport osos.environ["LANGCHAIN_TRACING_V2"] = "false" # Disable LangSmith tracingimport dotenvdotenv.load_dotenv()HUGGINGFACE_TOKEN = os.getenv("HUGGINGFACE_LANGGRAPH")TAVILY_API_KEY = os.getenv("TAVILY_LANGGRAPH_API_KEY")# Stateclass State(TypedDict):messages: Annotated[list, add_messages]# Toolswrapper = TavilySearchAPIWrapper(tavily_api_key=TAVILY_API_KEY)tool = TavilySearchResults(api_wrapper=wrapper, max_results=2)tools_list = [tool]# Create the LLM modellogin(token=HUGGINGFACE_TOKEN) # Login to HuggingFace to use the modelMODEL = "Qwen/Qwen2.5-72B-Instruct"model = HuggingFaceEndpoint(repo_id=MODEL,task="text-generation",max_new_tokens=512,do_sample=False,repetition_penalty=1.03,)# Create the chat modelllm = ChatHuggingFace(llm=model)# Create the LLM with toolsllm_with_tools = llm.bind_tools(tools_list)# BasicToolNode classclass BasicToolNode:"""A node that runs the tools requested in the last AIMessage."""def __init__(self, tools: list) -> None:"""Initialize the toolsArgs:tools (list): The tools to useReturns:None"""# Initialize the toolsself.tools_by_name = {tool.name: tool for tool in tools}def __call__(self, inputs: dict):"""Call the nodeArgs:inputs (dict): The inputs to the nodeReturns:dict: The outputs of the node"""# Get the last messageif messages := inputs.get("messages", []):message = messages[-1]else:raise ValueError("No message found in input")# Execute the toolsoutputs = []for tool_call in message.tool_calls:tool_result = self.tools_by_name[tool_call["name"]].invoke(tool_call["args"])outputs.append(ToolMessage(content=json.dumps(tool_result),name=tool_call["name"],tool_call_id=tool_call["id"],))return {"messages": outputs}basic_tool_node = BasicToolNode(tools=tools_list)# Functionsdef chatbot_function(state: State):return {"messages": [llm_with_tools.invoke(state["messages"])]}# Route functiondef route_tools_function(state: State):"""Use in the conditional_edge to route to the ToolNode if the last messagehas tool calls. Otherwise, route to the end."""# Get last messageif isinstance(state, list):ai_message = state[-1]elif messages := state.get("messages", []):ai_message = messages[-1]else:raise ValueError(f"No messages found in input state to tool_edge: {state}")# Router in function of last messageif hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:return "tools_node"return END# Start to build the graphgraph_builder = StateGraph(State)# Add nodes to the graphgraph_builder.add_node("chatbot_node", chatbot_function)graph_builder.add_node("tools_node", basic_tool_node)# Add edgesgraph_builder.add_edge(START, "chatbot_node")graph_builder.add_conditional_edges("chatbot_node",route_tools_function,{"tools_node": "tools_node",END: END},)graph_builder.add_edge("tools_node", "chatbot_node")# Compile the graphgraph = graph_builder.compile()# Display the graphtry:display(Image(graph.get_graph().draw_mermaid_png()))except Exception as e:print(f"Error al visualizar el grafo: {e}")Copied
Error al visualizar el grafo: Failed to reach https://mermaid.ink/ API while trying to render your graph after 1 retries. To resolve this issue:1. Check your internet connection and try again2. Try with higher retry settings: `draw_mermaid_png(..., max_retries=5, retry_delay=2.0)`3. Use the Pyppeteer rendering method which will render your graph locally in a browser: `draw_mermaid_png(..., draw_method=MermaidDrawMethod.PYPPETEER)`
Executamos o grafo
InputPython# Colors for the terminalCOLOR_GREEN = "\033[32m"COLOR_YELLOW = "\033[33m"COLOR_RESET = "\033[0m"def stream_graph_updates(user_input: str):for event in graph.stream({"messages": [{"role": "user", "content": user_input}]}):for value in event.values():print(f"{COLOR_GREEN}User: {COLOR_RESET}{user_input}")print(f"{COLOR_YELLOW}Assistant: {COLOR_RESET}{value['messages'][-1].content}")while True:try:user_input = input("User: ")if user_input.lower() in ["quit", "exit", "q"]:print(f"{COLOR_GREEN}User: {COLOR_RESET}{user_input}")print(f"{COLOR_YELLOW}Assistant: {COLOR_RESET}Goodbye!")breakstream_graph_updates(user_input)except:# fallback if input() is not availableuser_input = "What do you know about LangGraph?"print("User: " + user_input)stream_graph_updates(user_input)breakCopied
User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{"title": "Real Madrid 3-2 Leganes: Mbappe, Bellingham inspire comeback to ...", "url": "https://www.nbcsports.com/soccer/news/how-to-watch-real-madrid-vs-leganes-live-stream-link-tv-team-news-prediction", "content": "Real Madrid fought back to beat struggling Leganes 3-2 at the Santiago Bernabeu on Saturday as Kylian Mbappe scored twice and Jude", "score": 0.78749067}, {"title": "Real Madrid vs Leganes 3-2: LaLiga – as it happened - Al Jazeera", "url": "https://www.aljazeera.com/sports/liveblog/2025/3/29/live-real-madrid-vs-leganes-laliga", "content": "Defending champions Real Madrid beat 3-2 Leganes in Spain's LaLiga. The match at Santiago Bernabeu in Madrid, Spain saw Real trail 2-1 at half-", "score": 0.7485182}]User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{"title": "Real Madrid vs Leganés: Spanish La Liga stats & head-to-head - BBC", "url": "https://www.bbc.com/sport/football/live/cm2ndndvdgmt", "content": "Mbappe scores winner as Real Madrid survive Leganes scare Match Summary Sat 29 Mar 2025 ‧ Spanish La Liga Real Madrid 3 , Leganés 2 at Full time Real MadridReal MadridReal Madrid 3 2 LeganésLeganésLeganés Full time FT Half Time Real Madrid 1 , Leganés 2 HT 1-2 Key Events Real Madrid K. Mbappé (32' pen, 76')Penalty 32 minutes, Goal 76 minutes J. Bellingham (47')Goal 47 minutes Leganés Diego García (34')Goal 34 minutes Dani Raba (41')Goal 41 minutes [...] Good nightpublished at 22:14 Greenwich Mean Time 29 March 22:14 GMT 29 March Thanks for joining us, that was a great game. See you again soon for more La Liga action. 13 2 Share close panel Share page Copy link About sharing Postpublished at 22:10 Greenwich Mean Time 29 March 22:10 GMT 29 March FT: Real Madrid 3-2 Leganes [...] Postpublished at 22:02 Greenwich Mean Time 29 March 22:02 GMT 29 March FT: Real Madrid 3-2 Leganes Over to you, Barcelona. Hansi Flick's side face Girona tomorrow (15:15 BST) and have the chance to regain their three point lead if they are victorious. 18 6 Share close panel Share page Copy link About sharing", "score": 0.86413884}, {"title": "Real Madrid 3 - 2 CD Leganés (03/29) - Game Report - 365Scores", "url": "https://www.365scores.com/en-us/football/match/laliga-11/cd-leganes-real-madrid-131-9242-11", "content": "The game between Real Madrid and CD Leganés ended with a score of Real Madrid 3 - 2 CD Leganés. On 365Scores, you can check all the head-to-head results between", "score": 0.8524574}]User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{"title": "Real Madrid 3-2 Leganés (Mar 29, 2025) Final Score - ESPN", "url": "https://www.espn.com/soccer/match/_/gameId/704946/leganes-real-madrid", "content": "Game Information Santiago Bernabéu 8:00 PM, March 29, 2025Coverage: ESPN Deportes/ESPN+ Madrid, Spain Attendance: 73,641 [...] Match Commentary -Match ends, Real Madrid 3, Leganes 2.90'+9'Second Half ends, Real Madrid 3, Leganes 2.90'+7'Seydouba Cissé (Leganes) wins a free kick in the defensive half. Full Commentary Match Stats RMALEG Possession 70.7% 29.3% Shots on Goal 10 4 Shot Attempts 24 10 Yellow Cards 1 4 Corner Kicks 8 3 Saves 2 6 4-2-3-1 13 Lunin * 20 García * 22 Rüdiger * 35 Asencio * 17 Vázquez 6 Camavinga * 10 Modric 21 Díaz 5 Bellingham * 15 Güler 9 Mbappé [...] | Rayo Vallecano | 35 | 12 | 11 | 12 | -5 | 47 | | Mallorca | 35 | 13 | 8 | 14 | -7 | 47 | | Valencia | 35 | 11 | 12 | 12 | -8 | 45 | | Osasuna | 35 | 10 | 15 | 10 | -8 | 45 | | Real Sociedad | 35 | 12 | 7 | 16 | -9 | 43 | | Getafe | 35 | 10 | 9 | 16 | -3 | 39 | | Espanyol | 35 | 10 | 9 | 16 | -9 | 39 | | Girona | 35 | 10 | 8 | 17 | -12 | 38 | | Sevilla | 35 | 9 | 11 | 15 | -10 | 38 | | Alavés | 35 | 8 | 11 | 16 | -12 | 35 | | Leganés | 35 | 7 | 13 | 15 | -18 | 34 |", "score": 0.93497354}, {"title": "Real Madrid v Leganes | March 29, 2025 | Goal.com US", "url": "https://www.goal.com/en-us/match/real-madrid-vs-leganes/sZTw_SnjyKCcntxKHHQI7", "content": "Latest news, stats and live commentary for the LaLiga's meeting between Real Madrid v Leganes on the March 29, 2025.", "score": 0.921929}]User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{"title": "Real Madrid 3-2 Leganés (Mar 29, 2025) Final Score - ESPN", "url": "https://www.espn.com/soccer/match/_/gameId/704946/leganes-real-madrid", "content": "Game Information Santiago Bernabéu 8:00 PM, March 29, 2025Coverage: ESPN Deportes/ESPN+ Madrid, Spain Attendance: 73,641 [...] Match Commentary -Match ends, Real Madrid 3, Leganes 2.90'+9'Second Half ends, Real Madrid 3, Leganes 2.90'+7'Seydouba Cissé (Leganes) wins a free kick in the defensive half. Full Commentary Match Stats RMALEG Possession 70.7% 29.3% Shots on Goal 10 4 Shot Attempts 24 10 Yellow Cards 1 4 Corner Kicks 8 3 Saves 2 6 4-2-3-1 13 Lunin * 20 García * 22 Rüdiger * 35 Asencio * 17 Vázquez 6 Camavinga * 10 Modric 21 Díaz 5 Bellingham * 15 Güler 9 Mbappé [...] Mbappé nets twice to maintain Madrid title hopes ------------------------------------------------ Kylian Mbappé struck twice to guide Real Madrid to a 3-2 home win over relegation-threatened Leganes on Saturday. Mar 29, 2025, 10:53 pm - Reuters Match Timeline Real Madrid Leganés KO 32 34 41 HT 47 62 62 62 65 66 72 74 76 81 83 86 89 FT", "score": 0.96213967}]User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant:User: How did Real Madrid fare this weekend against Leganes in La Liga?Assistant: [{"title": "Real Madrid 3-2 Leganés (Mar 29, 2025) Final Score - ESPN", "url": "https://www.espn.com/soccer/match/_/gameId/704946/leganes-real-madrid", "content": "Game Information Santiago Bernabéu 8:00 PM, March 29, 2025Coverage: ESPN Deportes/ESPN+ Madrid, Spain Attendance: 73,641 [...] Match Commentary -Match ends, Real Madrid 3, Leganes 2.90'+9'Second Half ends, Real Madrid 3, Leganes 2.90'+7'Seydouba Cissé (Leganes) wins a free kick in the defensive half. Full Commentary Match Stats RMALEG Possession 70.7% 29.3% Shots on Goal 10 4 Shot Attempts 24 10 Yellow Cards 1 4 Corner Kicks 8 3 Saves 2 6 4-2-3-1 13 Lunin * 20 García * 22 Rüdiger * 35 Asencio * 17 Vázquez 6 Camavinga * 10 Modric 21 Díaz 5 Bellingham * 15 Güler 9 Mbappé [...] -550 o3.5 +105 -1.5 -165 LEGLeganésLeganés (6-9-14) (6-9-14, 27 pts) u3.5 -120 +950 u3.5 -135", "score": 0.9635647}, {"title": "Real Madrid v Leganes | March 29, 2025 | Goal.com US", "url": "https://www.goal.com/en-us/match/real-madrid-vs-leganes/sZTw_SnjyKCcntxKHHQI7", "content": "Latest news, stats and live commentary for the LaLiga's meeting between Real Madrid v Leganes on the March 29, 2025.", "score": 0.95921934}]...- **Attendance**: The match was played in front of 73,641 spectators.- **Key Moments**:- Real Madrid trailed 2-1 at half-time but mounted a comeback in the second half.- Mbappé's penalty in the 32nd minute and his second goal in the 76th minute were crucial in turning the game around.- Bellingham's goal in the 47th minute shortly after the break tied the game.This victory is significant for Real Madrid as they continue their push for the La Liga title, while Leganés remains in a difficult position, fighting against relegation.User: Which players played the match?Assistant: I'm sorry, but I need more information to answer your question. Could you please specify which match you're referring to, including the sport, the teams, or any other relevant details? This will help me provide you with the correct information.User: qAssistant: Goodbye!
Voltamos a ver que o problema é que não lembra o contexto da conversa.
---
➡️ **Continua na Parte 2: memória de curto prazo**, onde faremos com que o chatbot se lembre da conversa.















